python-sqlparse的SQL表血缘解析
2023-12-26 13:27:30
python-sqlparse解析SQL表血缘
文章目录
前言
数据治理和分析的难度和阵痛总是伴随着数仓建设日益加剧。为了更好的治理数据和评估影响分析——血缘就是我们绕不过的抓手!
本文主旨:通过sqlparse解析sql获取血缘
一、血缘是什么
数据血缘也称为数据血统或谱系,是来描述数据的来源和派生关系。说白了就是这个数据是怎么来的,经过了哪些过程或阶段,从哪些表,哪些字段计算得来的。
按照血缘关系划分节点,主要有以下三类:流出节点->中间节点->流入节点

流出节点: 数据提供方,血缘关系的源端节点。
中间节点: 血缘关系中类型最多的节点,既承接流入数据,又对外流出数据。
流入节点: 血缘关系的终端节点,一般为应用层,例如可视化报表、仪表板或业务系统。
二、准备工作
当前数仓模型建设通常使用sql语言建设,而sql语言通过查表在插入表示着流出节点(from) 和 流入节点(insert)的关系。接下来就让我们开始着手准备解析sql
1、了解python-sqlparse库
内容引用:作者:fanstuck
Python-sqlparse解析SQL工具库一文详解(一)
Python-sqlparse解析SQL工具库一文详解(二)
2、python-sqlparse简单实战
2.1、直接查询sql解析
python脚本:
import sqlparse
if __name__ == '__main__':
sql = """
insert table dwd_table_name_prod_info_df (
ftime
,prod_id
,prod_name
)
select
ftime
,prod_id
,prod_name
from ods_table_name_prod_info_df t1_1
where ftime = 20231223
"""
parsed = sqlparse.parse(sql)[0]
count = 0
for item in parsed.tokens:
print(count, ':\t', type(item), '\t|', item.ttype, '\t|', item.value, '\t|', item.is_group)
count += 1
执行结果(上述sql中换行符 和 连续空格 仅仅保留一个空格,避免结果爆炸)

结论:通过from关键字可定位from_表名
2.2、子查询sql解析
python脚本:
import sqlparse
if __name__ == '__main__':
sql = """
insert table dwd_table_name_prod_info_df (
ftime
,prod_id
,prod_name
,prod_price
)
select
t1.ftime
,t1.prod_id
,t1.prod_name
,t2.prod_price
from (
select
ftime
,prod_id
,prod_name
from ods_table_name_prod_info_df t1_1
where ftime = 20231223
) t1
left join (
select
prod_id
,prod_price
from ods_table_name_prod_price_df t2_1
where ftime = 20231223
) t2
on t1.prod_id = t2.prod_id
"""
parsed = sqlparse.parse(sql)[0]
count = 0
for item in parsed.tokens:
print(count, ':\t', type(item), '\t|', item.ttype, '\t|', item.value, '\t|', item.is_group)
count += 1
执行结果(上述sql中换行符 和 连续空格 仅仅保留一个空格,避免结果爆炸)

结论:需进入子查询后,按照2.1解析
2.3、join 表名解析
python脚本:
import sqlparse
if __name__ == '__main__':
sql = """
insert table dwd_table_name_prod_info_df (
ftime
,prod_id
,prod_name
,prod_price
)
select
t1.ftime
,t1.prod_id
,t1.prod_name
,t2.prod_price
from ods_table_name_prod_info_df t1 left join ods_table_name_prod_price_df t2
on t1.prod_id = t2.prod_id
where ftime = 20231223
"""
parsed = sqlparse.parse(sql)[0]
count = 0
for item in parsed.tokens:
print(count, ':\t', type(item), '\t|', item.ttype, '\t|', item.value, '\t|', item.is_group)
count += 1
执行结果(上述sql中换行符 和 连续空格 仅仅保留一个空格,避免结果爆炸)
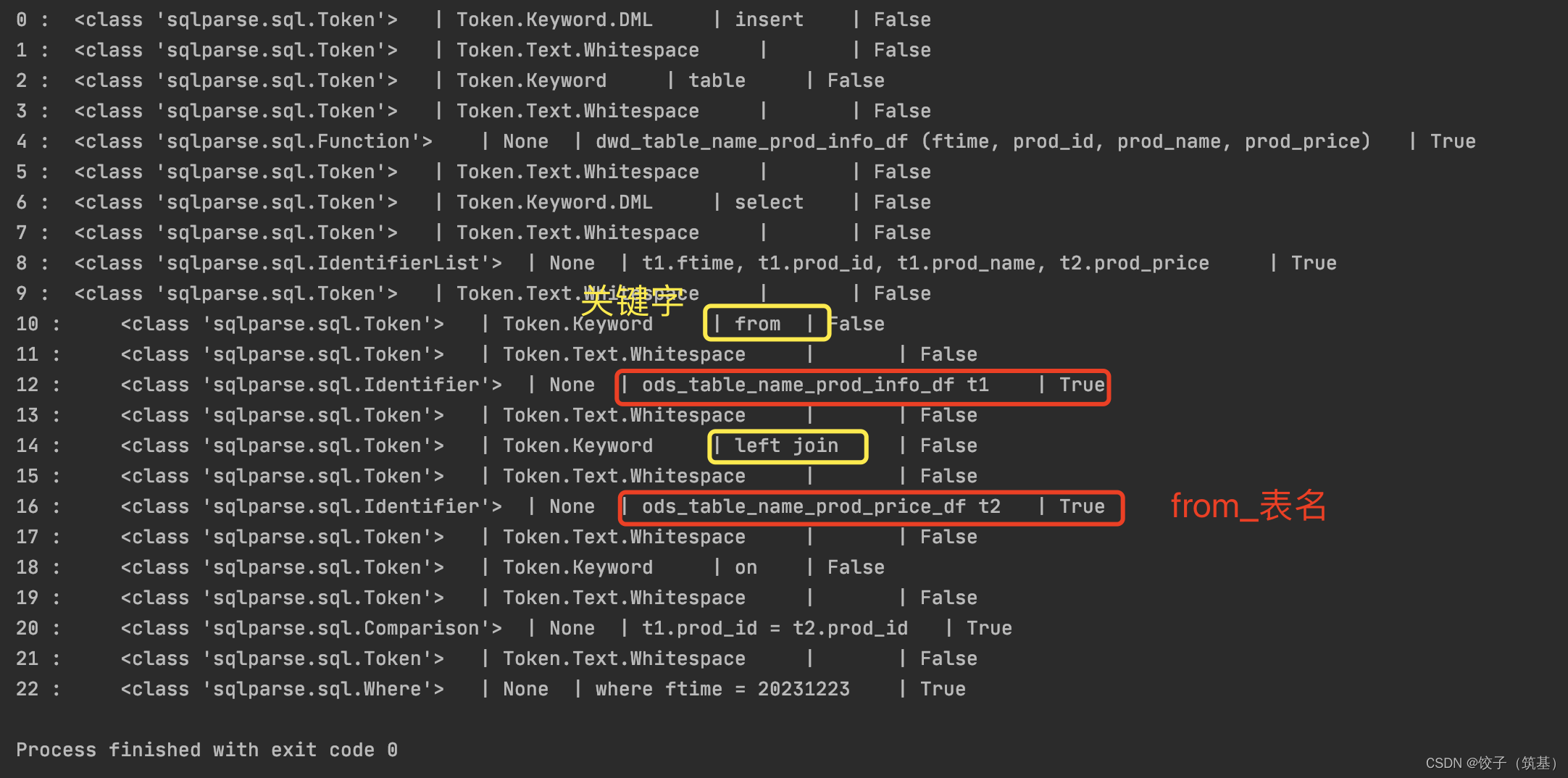
结论:通过join关键字也可直接解析from_表名
3、python-sqlparse解析思路
3.1、insert_表名解析
通过insert table 关键字解析 insert_表名
3.2、from_表名解析
通过from 和 join 关键字解析from_表名
三、实操演练
1.实操脚本
import re
import sqlparse
from sqlparse.sql import IdentifierList, Identifier
from sqlparse.tokens import Keyword, Punctuation
# 支持的join方式
ALL_JOIN_TYPE = ('JOIN', 'INNER JOIN', 'LEFT JOIN', 'LEFT OUTER JOIN', 'RIGHT JOIN', 'FULL OUTER JOIN', 'FULL JOIN',
'FULL OUT JOIN', 'LEFT SEMI JOIN', 'RIGHT SEMI JOIN')
def format_sql(sql_str):
"""
规范sql,剔除备注信息
:param sql_str:
:return:
"""
format_mid_sql = ""
sql_line_list = sql_str.split('\n')
for sql_line in sql_line_list:
# print("=" * 100)
# print(sql_line)
while True:
res_str = re_check(r'\"([^\"]*)\"|\'([^\']*)\'', sql_line)
if res_str[0]:
res_sub_sql = re_check(r'--', res_str[1])
if res_sub_sql[0]:
format_mid_sql += " " + res_sub_sql[1]
break
else:
format_mid_sql += " " + res_str[1] + res_str[2]
sql_line = res_str[3]
else:
res_sql = re_check(r'--', sql_line)
if res_sql[0]:
format_mid_sql += " " + res_sql[1]
else:
format_mid_sql += " " + sql_line
break
format_sql = re.sub(r'\s+', ' ', format_mid_sql.replace('\t', ' ').replace('\n', ' '))
return format_sql
def re_check(rule, check_str):
"""
正则模版
:param rule:
:param check_str:
:return:
"""
pattern = re.compile(rule, re.I)
re_result = pattern.search(check_str)
flag = False
match_rule = None
before_rule = None
after_rule = None
if re_result:
match_rule = check_str[re_result.span()[0]:re_result.span()[1]]
before_rule = check_str[:re_result.span()[0]]
after_rule = check_str[re_result.span()[1]:]
flag = True
return flag, before_rule, match_rule, after_rule
class BloodSqlparseAnalysis(object):
def format_subselect(self, parsed):
"""
规范子查询
"""
str_par = str(parsed).strip()
first_index = str_par.find('(')
last_index = str_par.rfind(')')
if first_index != -1 and last_index != -1:
str_par = str_par[first_index+1:last_index]
return str_par
def is_subselect(self, parsed):
"""
是否子查询:判断依据是否存在() 是否存在select
:param parsed:
:return:
"""
no_token_str = str(parsed)
if no_token_str.find('(') != -1 and no_token_str.find(')') != -1 and no_token_str.upper().find('SELECT') != -1:
return True
return False
def extract_table_identifiers(self, token_stream):
"""
递归结果返回
:param token_stream:
:return:
"""
for item in token_stream:
if isinstance(item, IdentifierList):
for identifier in item.get_identifiers():
result_tb_name = identifier.value.split(' ')[0]
yield result_tb_name
elif isinstance(item, Identifier):
result_tb_name = item.value.split(' ')[0]
yield result_tb_name
elif item.ttype is Keyword and item.value.upper() not in ALL_JOIN_TYPE:
yield item.value
def extract_tables(self, sql):
"""
提取sql中的from | join 后的表名
:param sql:
:return:
"""
parsed = sqlparse.parse(sql)[0]
from_seen = False
count = 1
for item in parsed.tokens:
# 定位问题备注
# print(from_seen, '|', count, ':\t', type(item), '\t|', item.ttype, '\t|', item.value, '\t|', item.is_group)
if from_seen:
if self.is_subselect(item):
from_seen = False
item = self.format_subselect(item)
for x in self.extract_tables(item):
yield x
elif (str(item).upper().find('WHERE') != -1) or (item.ttype is Keyword and item.value.upper() not in ALL_JOIN_TYPE) or item.ttype is Punctuation:
from_seen = False
continue
else:
yield item
elif (item.ttype is Keyword and item.value.upper() == 'FROM') or (item.ttype is Keyword and item.value.upper() in ALL_JOIN_TYPE):
from_seen = True
count += 1
def get_all_blood(self, sql):
all_tb = self.extract_tables(sql)
return list(self.extract_table_identifiers(all_tb))
def analysis_sql_blood(self, sql_str):
"""
根据函数 estimate_sql_type 返回的类型,执行不同的sql解析操作,返回解析后所有的数据源表(剔除临时表)
:param sql_str: sql字符串
:return: [数据源表]
"""
sql_str = format_sql(sql_str)
res_sql_flag = re_check(r'insert\s+table\s+[^\,]*?\s*?\(|insert\s+into\s+table\s+[^\,]*?\s*?\(|insert\s+overwrite\s+table\s+[^\,]*?\s*?\(|insert\s+table\s+[^\,]*?\s+?select|insert\s+into\s+table\s+[^\,]*?\s+?select|insert\s+overwrite\s+table\s+[^\,]*?\s+?select', sql_str)
if res_sql_flag[0]:
sql_flag = self.estimate_sql_type(sql_str)
if sql_flag == 'no_insert':
#TODO 返回非insertsql,不解析血缘
insert_table = ''
son_tables = []
elif sql_flag == 'no_with':
insert_table = self.analysis_insert_tb_name(sql_str)
son_tables = self.get_all_blood(sql_str)
else:
insert_table = self.analysis_insert_tb_name(sql_str)
tmp_tb_name_list, split_sql_str_list = self.analysis_with_sql(sql_str)
sub_tables = []
for sql_sub_str in split_sql_str_list:
sub_son_tables = self.get_all_blood(sql_sub_str)
sub_tables += sub_son_tables
son_tables = list(set(sub_tables).difference(set(tmp_tb_name_list)))
son_tables = list(set(son_tables))
else:
insert_table = None
son_tables = None
return insert_table, son_tables
def estimate_sql_type(self, sql_str):
"""
判断sql的具体类型
:param sql_str: sql字符串
:return: 返回三种类型:no_insert|with|no_with
"""
flag = 'no_insert' # 需要解析血缘的 insert sql
re_res = re_check(r'insert', sql_str)
if re_res[0]:
re_res_wiht = re_check(r'with\s+.*\s+as\s+\(', sql_str)
if re_res_wiht[0]:
flag = 'with' # sql中有临时表
else:
flag = 'no_with' # sql无有临时表
return flag
def analysis_with_sql(self, sql_str):
"""
解析带with临时表的sql字符串,返回一个二维数组: 临时表 和 各临时表计算sql
:param sql_str: sql字符串
:return: [[临时表名],[计算sql(拆分后)]]
"""
pattern_tmp_tb_name = re.compile(r'with\s+[^\,]*?\s+?as\s*?\(|\)\s*\,[^\,]*?\s+?as\s*?\(|\)\s*?select\s+?[^\,]*?\s+ftime', flags=re.I)
re_res_tb = pattern_tmp_tb_name.findall(sql_str)
tmp_tb_name_list = []
for have_tb_name_str in re_res_tb:
re_res_tb = re_check(r'select', have_tb_name_str)
if re_res_tb[0]:
continue
have_tb_name_list = have_tb_name_str.split(' ')
for index in range(len(have_tb_name_list)):
have_tb_name_list[index] = re.sub(r'\,|^with$|^as$|\(|\)|\s|\n|\t', '', have_tb_name_list[index], flags=re.I)
tmp_tb_name = ''.join(have_tb_name_list)
tmp_tb_name_list.append(tmp_tb_name)
split_sql_str_list = re.split(r'with\s+[^\,]*?\s+?as\s*?\(|\)\s*\,[^\,]*?\s+?as\s*?\(|\)\s*?select\s+?[^\,]*?\s+ftime', sql_str, flags=re.I)
split_sql_str_list[-1] = 'select ftime' + split_sql_str_list[-1]
return tmp_tb_name_list, split_sql_str_list
def analysis_insert_tb_name(self, sql_str):
"""
根据runsql获取insert后表名
:param sql_str: sql字符串
:return: [数据源表]
"""
pattern_tmp_tb_name = re.compile(
r'insert\s+table\s+[^\,]*?\s*?\(|insert\s+into\s+table\s+[^\,]*?\s*?\(|insert\s+overwrite\s+table\s+[^\,]*?\s*?\(|insert\s+table\s+[^\,]*?\s+?select|insert\s+into\s+table\s+[^\,]*?\s+?select|insert\s+overwrite\s+table\s+[^\,]*?\s+?select', flags=re.I)
re_res_tb_name = pattern_tmp_tb_name.findall(sql_str)
table_name = None
if len(re_res_tb_name) == 1:
insert_sql = re_res_tb_name[0]
insert_sql = insert_sql.replace(' :: ', "::")
insert_list = insert_sql.split(' ')
insert_table_name_flag = False
for insert_table in insert_list:
if insert_table_name_flag:
table_name = insert_table
break
if insert_table.upper() == 'TABLE':
insert_table_name_flag = True
if table_name[-1] == "(":
table_name = table_name[:-1]
return table_name
if __name__ == '__main__':
sql = """
insert table dwd_table_name_prod_info_df (
ftime
,prod_id
,prod_name
,prod_price
)
select
t1.ftime
,t1.prod_id
,t1.prod_name
,t2.prod_price
from (
select
ftime
,prod_id
,prod_name
from ods_table_name_prod_info_df t1_1
where ftime = 20231223
) t1
left join (
select
t2_1.prod_id
,t2_1.prod_price
,t2_2.prod_number
from ods_table_name_prod_price_df t2_1 left join ods_table_name_prod_number_df t2_2
where ftime = 20231223
) t2
on t1.prod_id = t2.prod_id
"""
bsa = BloodSqlparseAnalysis()
insert_table, from_table_list = bsa.analysis_sql_blood(sql)
print(insert_table)
print(from_table_list)
2.实操结果

符合预期
总结
以上就是今天分享的内容,本文仅仅简单介绍了python-sqlparse解析sql的方式,欢迎大家一起讨论呀。
文章来源:https://blog.csdn.net/chi_bai_001/article/details/135151160
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!