JAVAEE初阶相关内容第二十弹--HTTP协议
写在前:2024年啦!新的一年要努力学习啦
本篇博客围绕HTTP协议,对HTTP协议进行了解,需要理解其工作过程,对HTTP协议格式要清楚,通过抓包工具进行协议分析,认识“方法”、“请求报头”,后续还会进一步对HTTP这部分内容继续更新。

目录
1. HTTP协议是什么
超文本传输协议,属于应用层协议。
HTTP往往是基于传输层的TCP协议实现的(HTTP1.0,HTTP1.1,HTTP2.0均为TCP,HTTP3基于UDP实现),我们平时打开一个网站,就是通过HTTP协议来传输数据的。目前我们使用的还是HTTP1.1。
当我们在浏览器中输入一个网址(URL)时,浏览器就会给服务器发送一个HTTP请求,服务器返回一个HTTP响应。这个响应结果被浏览器解析后,就展示成了我们看到的页面内容。所谓“超文本”,就是传输的内容不仅仅时文本(比如html、css这个就是文本),还可以时一些其他的资源,比如图片、视频、音频等二进制的数据。
2. 理解HTTP协议的工作过程
当我们在浏览器中输入一个“网址”,此时浏览器就会给对应的服务器发送一个HTTP请求,对方服务器收到这个请求后,经过计算处理,就会返回一个HTTP响应。
3. HTTP协议格式
3.1 抓包工具的使用
http协议的交互详细过程,可以借助第三方工具来看到,这里我们使用的是Fiddler。
关于Fiddler
fiddler本质上是一个代理程序,使用的时候需要注意两点:
(1)可能和别的代理程序冲突,使用的时候要关闭其他的代理程序【包括一些浏览器插件】
(2)要想正确抓包,还需要开启https功能。 https是基于http搞出来的进化版协议,当下互联网上绝大部分的服务器都是https的,fiddler默认不能抓https的包,需要我们手动启用一下https并且安装证书。
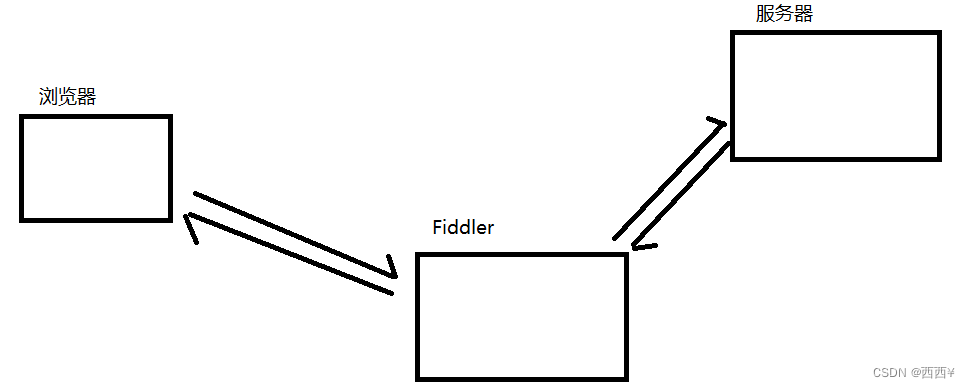
3.2 抓包工具的原理
Fiddler相当于一个代理,浏览器在访问baidu.com的时候就会把HTTP请求先发给Fiddler,Fiddler再把请求转发给baidu服务器返回数据,Fiddler拿到返回数据,再把数据交给浏览器。
3.3 抓包结果
以下是一个HTTP请求/响应的抓包结果
3.3.1 【请求】 Request

首行:[方法]+[url]+[版本]

[Get]:方法 Method
[url]:唯一资源定位符,描述资源在哪,具体地址。协议名称://ip:端口号/路径?查询字符串
Header:请求的属性,冒号分割的键值对,每组属性之间使用\n分割,遇到空行表示Header部分结束。
Body:空行后面的内容都是Body,Body允许为空字符串,如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度。
(1) 认识URL
平时我们俗称的“网址”,其实说的就是URL(Uniform Resource Locator 统一资源定位符)
互联网上的每个文件都有一个唯一的URL。它包含的信息指出文件的位置以及浏览器应该怎么处理它。
(2) URL基本格式

3.3.2 【响应】
首行:【版本号】+【状态码】+【状态码解释】
Header:请求的属性,冒号分割的键值对,每组属性之间使用\n分隔,遇到空行表示Header部分结束。
Body:空行后面的内容都是body,Body允许为空字符串,如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度,如果服务器返回了一个html页面,那么html页面内容就是在body中。
关于HTTP报文中存在的空行:
因为HTTP协议并没有规定报头部分的键值对有多少个,空行就相当于是“报头的结束标志”,或者是”报头和正文之间的分隔符“。
HTTP在传输层依赖TCP协议,TCP是面向字节流的,如果没有这个空行,就会出现”粘包问题“。
3.4 认识“方法”
3.4.1 GET方法
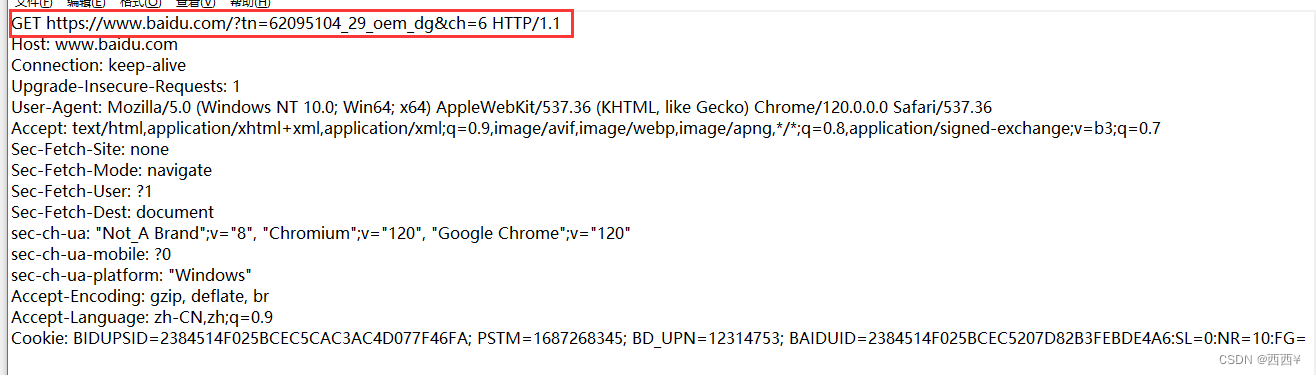
(1) 认识GET请求
GET是最常用的HTTP方法,常用于获取服务器上的某个资源,在浏览器中直接输入URL,此时浏览器就会发送出一个GET请求;另外,HTML中的link,img,script等标签,也会触发GET请求。
在浏览器地址栏中直接输入URL
html里的link,script,img,a......
通过js来构造get
(2) GET特点
首行第一部分为GET;URL的query string可以为空,也可以不为空;header部分有若干个键值对结构;body部分为空。
关于query string
query string中的内容是键值对结构,其中的key和value的取值和个数,完全都是程序员自己约定的,我们可以通过这样的方式来制定传输我们需要的信息给服务器。
3.4.2 POST方法
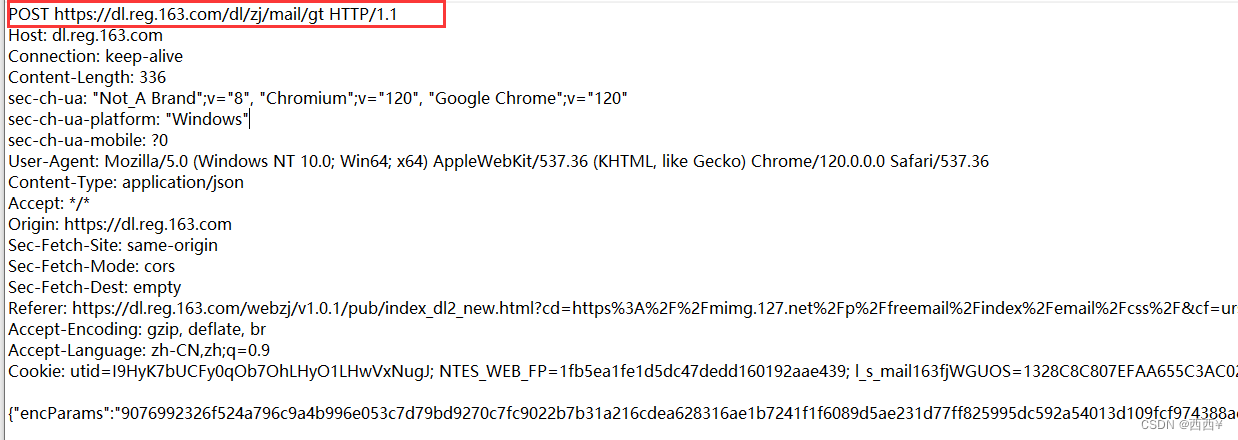
(1) 认识POST
POST方法也是一种常见的方法,多用于提交用户输入的数据给服务器(例如登录页面)。通过HTML中的form标签可以构造POST请求,或者使用JavaScript的ajax也可以构造POST请求。
(2) POST特点
首行的第一部分为POST;URL的query string一般为空(也可以不为空);header部分有若干个键值对结构;body部分一般不为空,body内的数据格式通过header中的Content-Type指定,body的长度由head中的Content-Length指定
3.4.3 其他方法
| 方法 | 介绍 |
| PUT | 与POST相似,只是具有幂等特性,一般用于更新 |
| DELETE | 删除服务器指定资源 |
| OPTIONS | 返回服务器所支持的请求方法 |
| HEAD | 类似于GET,只不过响应体不返回,只返回响应头 |
| TRACE | 回显服务器端收到的请求,测试的时候会用到 |
| CONNECT | 预留,暂无使用 |
3.4.4 面试题--谈谈GET和POST的区别
(1) GET也可以给服务器传递一些信息,GET传递信息一般都是放在query string中,POST传递消息则是通过body。
(2) 语义上的差别:GET请求一般是用于从服务器获取数据。POST一般是用于给服务器提交数据。
(3) GET通常会被涉资成幂等的,POST不要求幂等。【幂等:相同的输入,得到的结果也是确定的】
(4) GET可以被缓存,POST一般不能被缓存(把请求的姐夫哦保存下来,下次请求就不必真请求了,直接取缓存的结果)
GET和POST没有本质区别(在大部分场景下,彼此之间能相互替代)。完全可以使用GET提交,使用POST获取。也可以把POST设置成幂等,GET不幂等。
3.5 认识请求“报头”(header)
header的整体的格式也是“键值对”结构,每个键值对占一行,键和值之间使用分号分隔。
3.5.1 Host
表示服务器和主机的地址和端口。描述最终要访问的目标,大多数情况下和URL一样。
3.5.2 Content-Length
表示body中的数据长度。
3.5.3Content-Type
表示请求的body中数据格式
如果是GET请求,没body,请求中没有这俩字段;如果是POST请求,有body,请求中必须有这俩字段。
3.5.4 User-Agent(UA)
描述了浏览器和操作系统的版本,区分PC和移动。
3.5.5 Referer
表示这个页面是从哪个页面跳转过来的,如果直接通过地址栏输入地址或者是点击收藏夹,都是没有referer的。
3.5.6 Cookie
Cookie是非常重要的header属性,本质上是浏览器给网页提供的本地存储数据的机制。网页默认是不允许访问计算机硬盘的(保证安全),Cookie中存储了一个字符串,这个数据可能是客户端(网页)自行通过JS写入的,也可能来自于服务器(服务器在HTTP响应的header中通过Set-Cookie字段给浏览器返回数据)
Cookie浏览器对于访问硬盘做了明确的限制,Cookie就是通过键值对的方式来组织数据的。
(1) Cookie从哪来
Cookie中的数据是来自于服务器,服务器会通过HTTP响应的报头部分(Set-Cookie字段) 服务器来决定,浏览器的Cookie要存什么。
(2) Cookie在哪存
可以认为是存在于浏览器中。存在于硬盘的。Cookie在存的时候,是按照浏览器 + 域名维度来进行细分的,不同的浏览器,各自存各自的Cookie,同一个浏览器不同的域名,对应不同的Cookie。Cookie中的内容不仅是键值对,同时还有过期时间。比如,有很多网站,登录一次后自动记录登录状态。
(3) Cookie到哪去
Cookie会回到服务器这里,客户端同一时刻是有很多的,客户端会通过Cookie来保存当前用户使用的中间状态,当客户端访问浏览器的时候,就会自动的把Cookie的内容带入到请求中,服务器就能够知道现在的客户端是啥样的。
接下来将会学习构造HTTP请求、HTTPS等知识。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!