基于 TensorFlow.js 构建垃圾评论检测系统
基于 TensorFlow.js 构建垃圾评论检测系统。

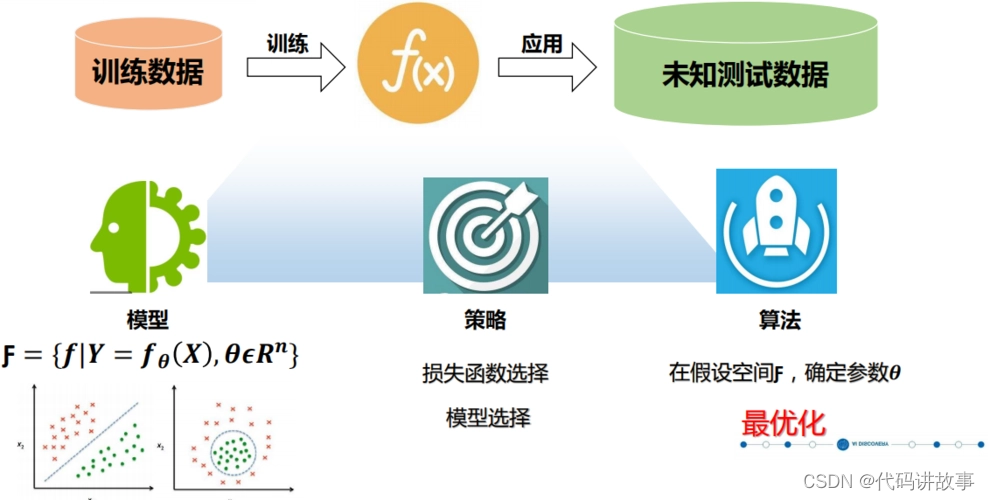
- 准备工作
在过去的十年中,Web 应用变得越来越具有社交性和互动性,而即使是在中等热门的网站上,也有数万人可能实时对多媒体、评论等的支持。
这也让垃圾内容发布者有机会滥用此类系统,将不太令人满意的内容与其他人撰写的文章、视频和帖子联系起来,以提高曝光率。
而旧的垃圾内容检测方法(例如屏蔽的字词列表)很容易被绕过,并且与高级垃圾内容漫游器不匹配,后者会越来越复杂。时至今日,我们现在可以利用经过训练的机器学习模型来检测此类网络垃圾。
按照传统,运行机器学习模型来预过滤评论是在服务器端执行,但现在,您可以使用 TensorFlow.js 在客户端通过 JavaScript 在浏览器中执行机器学习模型。您可以在垃圾邮件到达后端之前将其拦截,从而节省宝贵的服务器端资源。
您可能已经知道,机器学习如今已经成为一个大热门,涉及的几乎所有行业,但作为网络开发者,您该如何着手使用这些功能呢?
此 Codelab 将介绍如何使用自然语言处理技术(通过计算机理解人类语言艺术)从空白画布中构建 Web 应用,以解决垃圾评论的真正问题。许多 Web 开发者都在处理当今越来越多的热门应用之一时遇到这一问题,此 Codelab 将帮助您有效地解决此类问题。
前提条件
此 Codelab 的编写者是刚开始接触机器学习、希望开始通过 TensorFlow.js 使用预训练模型的 Web 开发者。
本实验假设您熟悉 HTML5、CSS 和 JavaScript。
学习内容
您将学习以下内容:
详细了解 TensorFlow.js 是什么以及存在哪些用于自然语言处理的模型。
为一个虚构的视频博客构建一个简单的 HTML / CSS / JS 网页,并在其中添加实时评论部分。
注意:系统不会使用 React / Angular 等框架,但您可以根据需要自行调整。
使用 TensorFlow.js 加载经过预训练的机器学习模型,该模型可以预测输入的句子是否可能为垃圾内容,如果是,则警告用户他们的评论需经审核才能发布。
以可供机器学习模型使用的方式对句子句子进行编码,以便进行分类。
解释机器学习模型的输出,以决定是否要自动举报该评论。这一假设的用户体验可以在您可能正在处理的任何网站上重复使用,并经过调整以适应任何客户用例 - 它可能是常规的博客、论坛或某种形式的 CMS,如 Drupal。
很不错。很难做到?不正确。让我们开始吧…
所需条件
最好使用 Glitch.com 帐号,您也可以使用自己能轻松编辑和运行的网络服务环境。
- 什么是 TensorFlow.js?
1aee0ede85885520.png
TensorFlow.js 是一个开源机器学习库,可运行在 JavaScript 可以运行的任何位置。它基于使用 Python 编写的原始 TensorFlow 库,旨在为 JavaScript 生态系统打造这种开发者体验和一系列 API。
可以在哪里使用?
鉴于 JavaScript 的可移植性,您现在可以使用 1 种语言编写,并在以下所有平台上轻松执行机器学习:
使用原版 JavaScript 的网络浏览器中的客户端
使用 Node.js 进行服务器端,甚至是 Raspberry Pi 等 IoT 设备
使用 Electron 的桌面应用
使用 React Native 的原生移动应用
TensorFlow.js 还支持在每个环境中使用多个后端(例如,可以在 CPU 或 WebGL 中执行的实际基于硬件的环境)。此处的“后端”并不意味着服务器端环境(例如,执行后端可以是 WebGL 中的客户端),以确保兼容性并保持运行速度。目前,TensorFlow.js 支持:
在设备的显卡上执行 WebGL - 这是使用 GPU 加速执行大型模型(大小超过 3MB)的最快方法。
Web Assembly (WASM) 在 CPU 上执行 - 旨在改进各种设备的 CPU 性能,例如旧款手机。这更适合较小模型(小于 3MB),在具有 WASM 的 CPU 上,由于将内容上传到图形处理器的开销,其实际运行速度比使用 WebGL 更快。
CPU 执行 - 在其他环境均不可用的情况下进行回退。这是三者中最慢的一个,但会始终存在。
注意:如果您知道要在哪个设备上执行,可以选择强制执行这些后端之一,也可以直接让 TensorFlow.js 来决定未指定。
客户端超能力
在客户端计算机上的网络浏览器中运行 TensorFlow.js 有几个值得考虑的优势。
隐私权
您可以在客户端计算机上训练和分类数据,而无需将数据发送到第三方网络服务器。有时,根据这些规定,您可能需要遵守 GDPR 等当地法律,或者在处理用户可能想要保留但不希望将其发送给第三方的任何数据时。
速度
由于您不必向远程服务器发送数据,因此推断速度(数据分类操作)可能会更快。更棒的是,如果用户可以授予访问权限,您可以直接访问设备的传感器,例如相机、麦克风、GPS、加速度计等。
扩大覆盖面并扩大覆盖面
只需点击一下,世界上的任何用户都可以点击您向其发送的链接,在其浏览器中打开网页,并利用您创建的内容。您无需使用 CUDA 驱动程序完成复杂的服务器端 Linux 设置,只需要使用机器学习系统即可。
费用
没有服务器意味着您只需支付 CDN 即可托管 HTML、CSS、JS 和模型文件。与保持服务器全天候运行(可能安装有显卡)相比,CDN 的费用要低得多。
服务器端功能
利用 TensorFlow.js 的 Node.js 实现可以启用以下功能。
全面的 CUDA 支持
对于服务器端的图形卡加速,您必须安装 NVIDIA CUDA 驱动程序,才能让 TensorFlow 与显卡配合使用(这与使用 WebGL 的浏览器不同 - 无需安装)。不过,借助全面的 CUDA 支持,您可以充分利用显卡的较低级别功能,从而加快训练和推断速度。性能与 Python TensorFlow 实现不相上下,因为它们具有相同的 C++ 后端。
模型大小
对于研究中的先进模型,您使用的可能是超大模型,可能是 GB。由于每个浏览器标签页的内存用量限制,这些模型目前无法在网络浏览器中运行。如需运行这些更大的模型,您可以在自己的服务器上使用 Node.js,并高效地运行此类模型所需的硬件规格。
广告订单
Raspberry Pi 等常用的单板计算机也支持 Node.js,这也意味着您也可以在此类设备上执行 TensorFlow.js 模型。
速度
Node.js 是使用 JavaScript 编写的,这意味着,它仅在即时编译时很有用。这意味着,使用 Node.js 时,其性能通常会提高,因为运行时会进行优化,尤其是在执行任何预处理时。一个很好的例子是此案例研究,展示了 Hugging Face 如何利用 Node.js 将自然语言处理模型的性能提升了 2 倍。
现在,您已经了解了 TensorFlow.js 的基础知识、运行位置以及它的一些优势,下面让我们开始对它进行实用的操作吧!
- 预训练模型
为什么要使用预训练模型?
从受欢迎的预训练模型入手,如果它符合您预期的用例,有很多好处,例如:
无需自行收集训练数据。 以正确的格式准备数据并为其添加标签以便机器学习系统从中学习,此过程可能非常耗时且昂贵。
能够快速降低创意的原型,并降低成本和时间。
如果预先训练好的模型足够好,可以执行您需要的操作,那么您就可以“集中精力训练模型”,从而集中精力运用模型提供的知识来实现您的广告创意。
采用先进研究成果。 预训练模型通常基于热门的研究,让您了解这些模型,同时了解它们在现实世界中的表现。
易于使用和大量文档。 由于此类模型很受欢迎。
迁移学习 功能。一些预训练模型可以提供迁移学习功能,本质上是一种将所学信息从一个机器学习任务传输到另一个类似示例的做法。例如,如果您向该模型训练模型,但其最初经过训练可识别猫,则可以重新训练该模型来识别狗。这会更快速,因为您不会从空白画布开始。该模型可以使用学到的知识来识别猫,然后识别新事物 - 毕竟,狗的眼睛和耳朵也太过了,所以如果它已经知道如何查找这些特征,我们将完成一半。以更快的速度基于您自己的数据重新训练模型。
预训练的垃圾评论检测模型
您将使用“平均字词嵌入”模型架构来满足垃圾评论检测需求,但是,如果您尝试使用未经训练的模型,则最佳选择莫过于猜测句子是否为垃圾句子。
为了使模型有用,它需要在自定义数据上训练,以便它能够了解垃圾评论和非垃圾评论的外观。然后,基于所学习到的知识,未来更有可能正确分类。
幸运的是,已经有人针对这种垃圾评论分类任务训练了此精确模型架构,因此您可以以此为起点。您可能会发现使用相同模型架构的其他预训练模型可以执行不同的操作,例如检测编写了哪种语言的评论,或预测系统是否应该根据编写的文本将网站联系表单数据自动发送给某个公司团队例如销售(产品查询)或工程(技术错误或反馈) 有了足够的训练数据,此类模型就可以学习在各种情况下对此类文本进行分类,让您的 Web 应用拥有超能力和提高组织效率。
在将来的 Codelab 中,您将学习如何使用 Model Maker 重新训练此预训练垃圾评论模型,并基于您自己的评论数据进一步改进其模型。 现在,您将以现有的垃圾评论检测模型为起点,让初始 Web 应用成为第一个原型。
此预训练的垃圾评论检测模型已发布到称为 TF Hub 的网站,TF Hub 是由 Google 维护的机器学习模型库,机器学习工程师可以在其中发布针对许多常见用例的预制模型(例如文本、视觉、声音等)。接下来,立即下载模型文件,以便稍后在此 Codelab 中使用相应 Web 应用。
- 开始设置代码
所需条件
现代网络浏览器。
了解 HTML、CSS、JavaScript 和 Chrome 开发者工具(查看控制台输出)。
我们来编码吧。
我们创建了一个 Glitch.com Node.js Express 样板模板,您只需点击一下即可克隆此 Codelab 作为基本状态。
在 Glitch 上,只需点击重新合成按钮,即可创建分支,然后编辑一组新文件。
这个非常简单的框架会为我们提供 www 文件夹中的以下文件:
HTML 网页 (index.html)
样式表 (style.css)
用于编写 JavaScript 代码 (script.js) 的文件
为方便起见,我们还在 HTML 文件中添加了 TensorFlow.js 库的导入代码,如下所示:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
然后,我们通过 package.json 和 server.js 通过一个简单的 Node Express 服务器提供此 www 文件夹
替代方案:使用您首选的网络编辑器或在本地工作如果您想下载代码并在本地服务器上使用,或者需要使用其他在线编辑器,只需在 Node.js 中重新创建文件即可选择您想使用的环境,然后复制 Glitch 样板代码并将其粘贴到每个文件的本地环境中。
- 应用 HTML 样板
从何处入手?
所有原型都需要一些基本的 HTML 架构,以便呈现您的发现结果。立即进行设置。您将添加:
网页的标题
一些描述性文字
代表视频博客条目的占位视频
可查看和输入评论的区域
打开 index.html 并粘贴以下代码,以设置上述功能:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
详细说明
我们来分析一下上面的一些 HTML 代码,以突出您添加的一些关键内容。
您为网页标题添加了 <h1> 标记,并为所有包含在 <header> 中的登录按钮添加了 <a> 标记。然后,您为文章标题添加了 <h2>,并为视频说明添加了 <p> 标记。这里没什么特别的。
您添加了一个嵌入任意 YouTube 视频的 iframe 标记。目前,您是将功能强大的 TensorFlow.js 说作为占位符使用,但您只需更改 iframe 的网址,即可将任何视频放在此处。实际上,在生产网站上,这些值将由后端动态地呈现,具体取决于所查看的页面。
最后,您添加了一个 ID 为“comments”的 section,它包含一个用于写入新评论的 img div 以及一个 button,用于提交您要添加且未排序的新评论评论列表。您拥有每个列表项内 span 标记内的用户名和时间,最后是 p 标记内的评论本身。2 条示例注释目前硬编码为占位符。
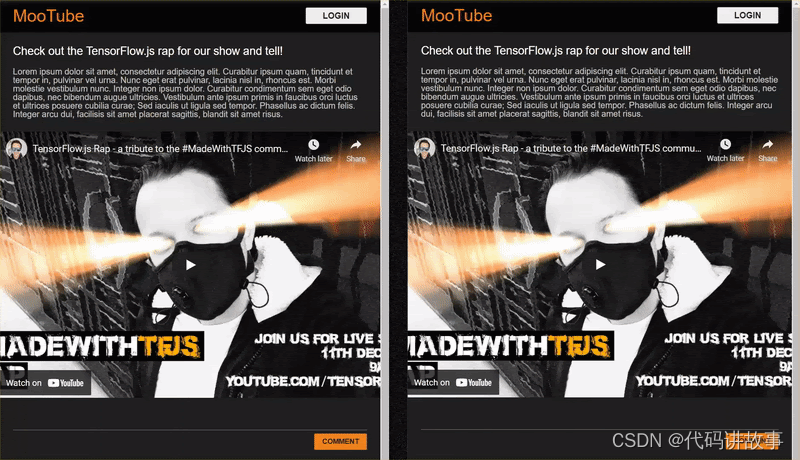
如果立即预览输出,结果应如下所示:
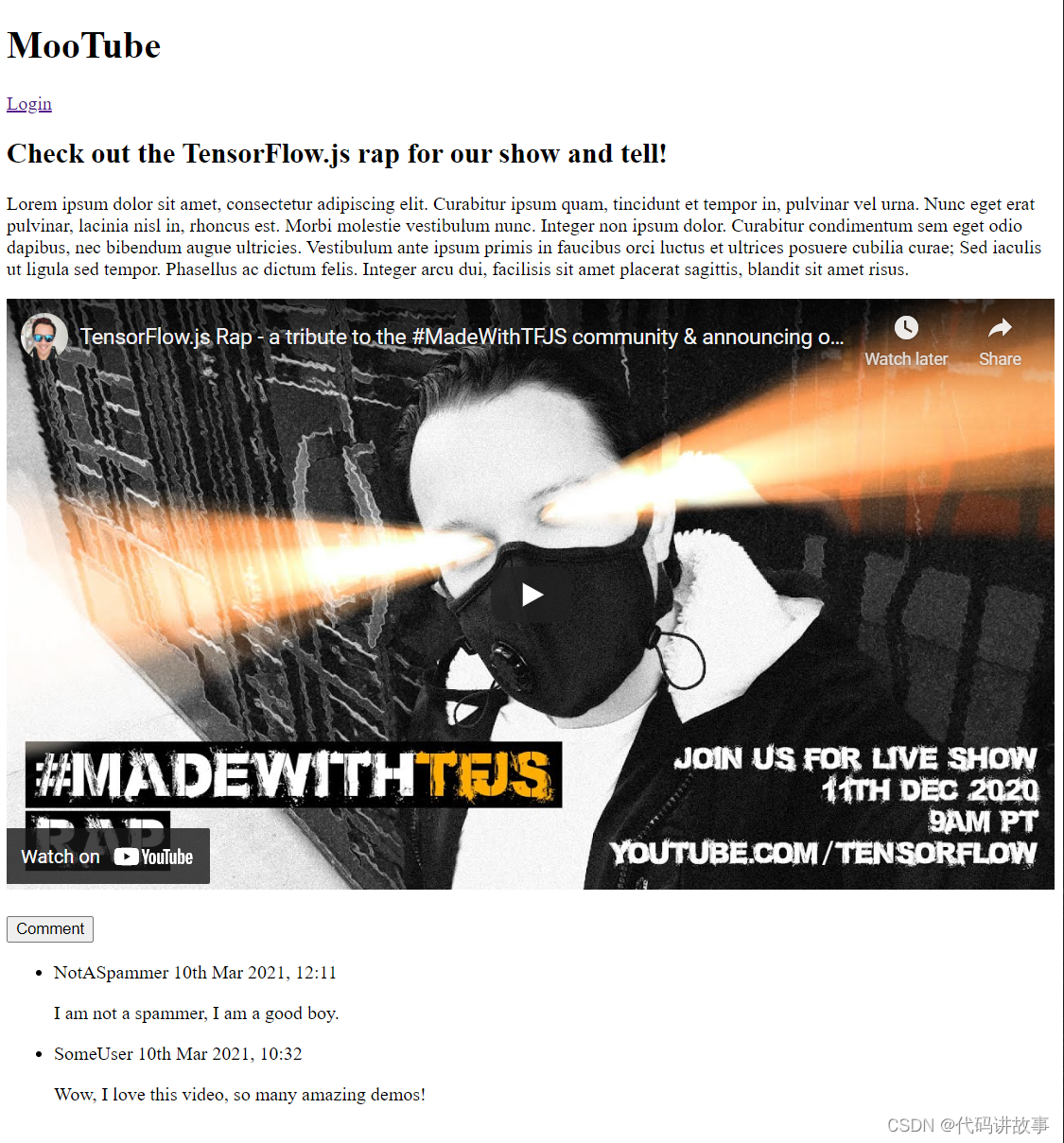
提示:您可以在 Glitch.com 中实时预览作品,方法是:点击屏幕左上方的显示下拉菜单,然后选择代码旁边的 或在新窗口中打开。
这看起来很糟糕,是时候添加一些样式了…
- 添加样式
元素默认值
首先,为刚添加的 HTML 元素添加样式,以确保其正确呈现。
首先,应用 CSS 重置,在所有浏览器和操作系统中应用评论起点。使用以下命令覆盖 style.css 内容:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
接下来,附加一些有用的 CSS,使界面生动起来。
将以下内容添加到您在上述步骤中添加的已重置的 CSS 代码的 style.css 末尾:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "?";
margin: -17px 2px;
zoom: 3;
float: right;
}
太好了!这就是您所需的一切。如果您成功使用上面的 2 个代码替换了样式,您的实际预览现在应如下所示:
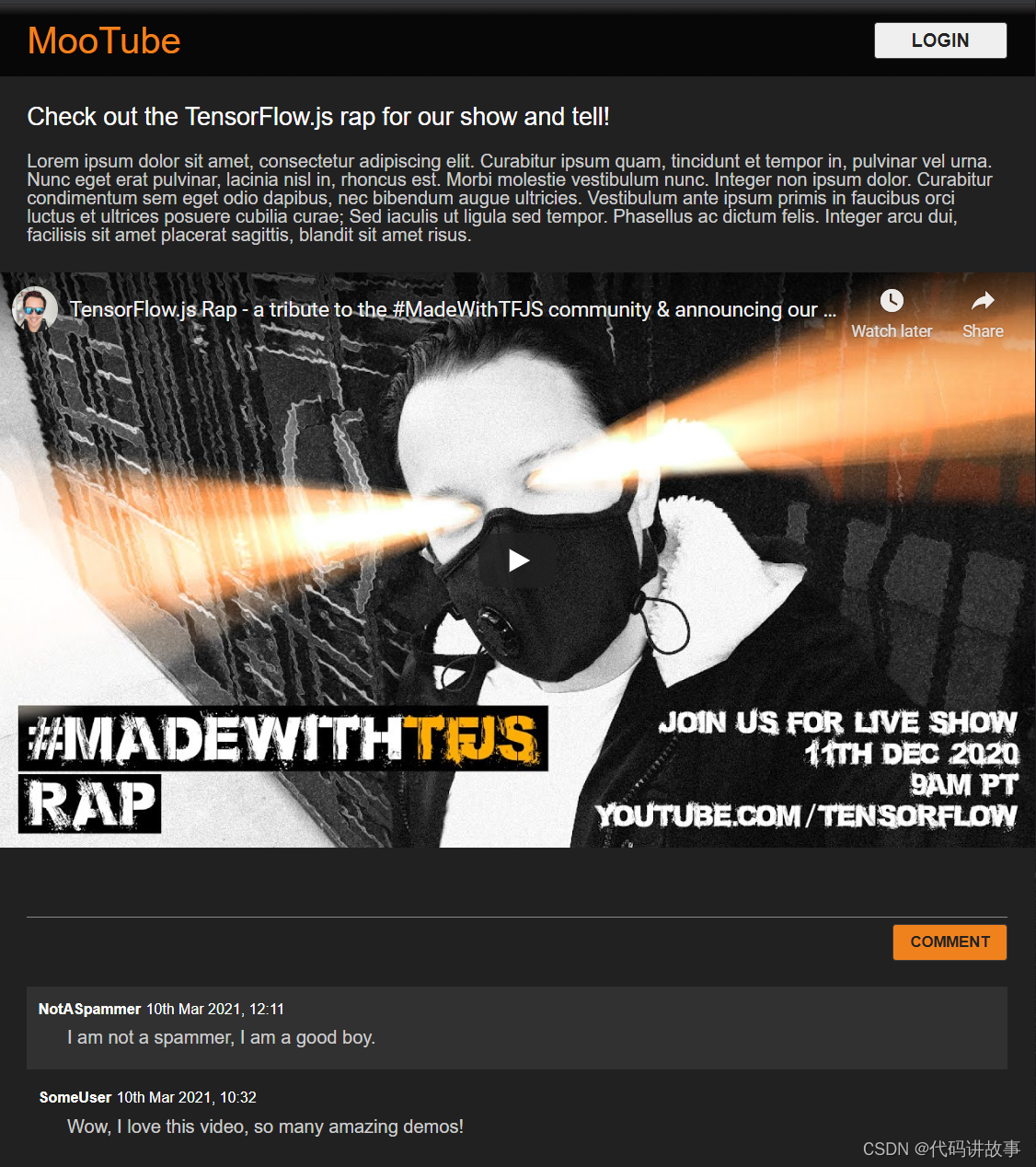
默认启用甜美的夜间模式以及迷人的 CSS 过渡,让关键元素呈现悬停效果。看起来很不错。现在,使用 JavaScript 集成一些行为逻辑。
- JavaScript:DOM 操作和事件处理程序
提示:以下代码按顺序显示,但被细分为更小的部分,以便做出进一步说明。如果您每次将每个段复制并粘贴到 JavaScript 文件的末尾,或者按照建议替换上一步中空的已定义函数,则一切正常 😃
引用主要 DOM 元素
首先,确保您可以访问需要稍后在代码中操作或访问的网页的关键部分,同时定义一些 CSS 类常量来设置样式。
首先,将 script.js 的内容替换为以下常量:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
处理评论发布
接下来,向 POST_COMMENT_BTN 添加事件监听器和处理函数,以便能够获取写入的评论文本并设置 CSS 类以表示已经开始处理。请注意,如果您正在进行处理,请确定您尚未点击该按钮。
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
太好了!如果您刷新网页并尝试发布评论,现在应该会看到评论按钮和文字变为灰度字样,在控制台中,您应该会看到类似下图输出的评论:
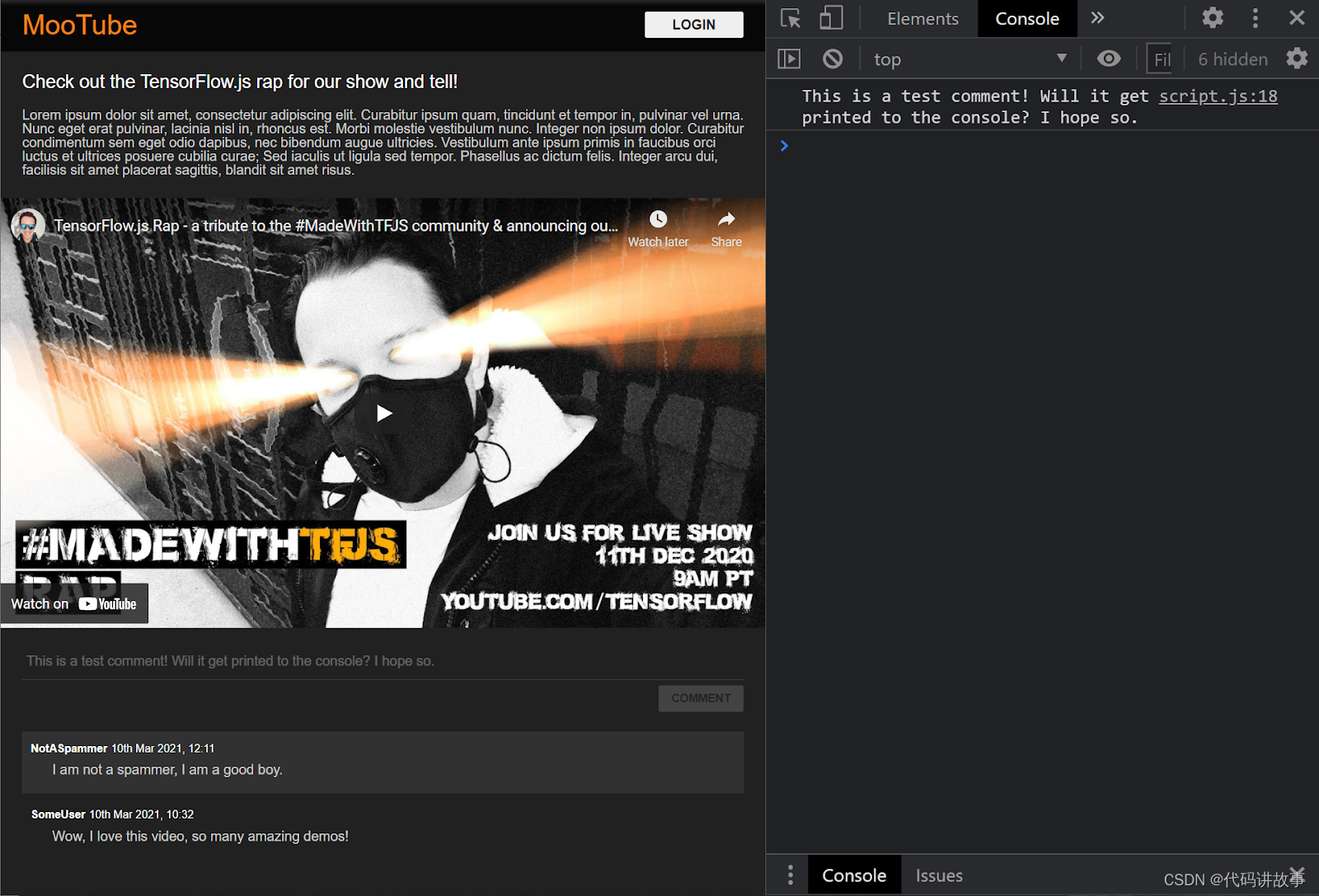
提示:您可以在网络浏览器中按 F12 键打开控制台窗口,或右键点击网页上的任何位置,然后依次选择 inspect 和 console。
现在,您已经有了基本的 HTML / CSS / JS 框架,是时候把注意力转回到机器学习模型上,从而将其与精美的网页融为一体。
- 应用机器学习模型
模型即将加载。不过,在执行此操作之前,您必须将之前在 Codelab 中下载的模型文件上传到您的网站,以便托管代码并在代码中使用。
首先,请解压缩您在本 Codelab 开始时为模型下载的文件(如果您尚未执行此操作)。您应该会看到一个目录,其中包含以下文件:
您在这里有什么?
model.json - 这是经过训练的 TensorFlow.js 模型的一个文件。稍后,您将在 TensorFlow.js 代码中引用此特定文件。
group1-shard1of1.bin - 这是一个二进制文件,其中包含 TensorFlow.js 模型的经过训练的权重(基本上是它用来完成分类任务的大量数字),需要将其托管在您服务器上的某个位置以供下载。
vocab - 这种没有扩展名的奇怪文件来自 Model Maker,它展示了如何对句子中的字词进行编码,以便模型了解如何使用它们。我们将在下一部分中对此进行详细介绍。
labels.txt - 此属性仅包含模型将预测的结果类名称。对于此模型,如果您在文本编辑器中打开此文件,其中只会列出“false”和“true”,表示“不是垃圾邮件”或“垃圾邮件”。
托管 TensorFlow.js 模型文件
首先,将 model.json 和生成的 *.bin 文件放在网络服务器上,以便通过网页访问它们。
注意:如果您未使用 Glitch 而是运行自己的 Node.js Express 服务器,那么只需将这些文件原封不动放入 www 中即可文件夹进行投放。仅当您想使用 Glitch.com 来托管文件时,才需遵循下面的上传步骤。Glitch 不是 Google 拥有的产品,但对于许多代码开发者来说,是一个非常热门的试用代码。因此,如果您有兴趣,请随时查看其条款及条件。
将文件上传到 Glitch
点击 Glitch 项目左侧面板中的 assets 文件夹。
点击上传素材资源,然后选择 group1-shard1of1.bin 以将其上传到此文件夹。现在,上传后应如下所示:
太好了!现在,对 model.json 文件执行相同的操作。 2 个文件应位于 assets 文件夹中,如下所示:
点击您刚刚上传的 group1-shard1of1.bin 文件。您可以将网址复制到其位置。立即复制此路径,如下所示:
现在,点击屏幕左下角的工具 > 终端。等待终端窗口加载。加载完成后,输入以下内容,然后按 Enter 键将目录更改为 www 文件夹:
终端:
cd www
接下来,使用 wget 下载刚刚上传的 2 个文件,只需将下面的网址替换为您在 Glitch 上的 assets 文件夹中为这些文件生成的网址(检查每个文件对应的自定义网址的素材资源文件夹) )。请注意,这两个网址之间的空格和您需要使用的网址与下面的网址不同,但看起来会类似:
终端
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
太棒了!现在,您已为上传到 www 文件夹的文件制作了副本,但现在这些文件将以奇怪的名称下载。
在终端中输入 ls 并按 Enter 键。您会看到类似如下的内容:

您可以使用 mv 命令重命名这些文件。在控制台中输入以下内:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
最后,在终端中输入 refresh 并按 Enter 键以刷新 Glitch 项目:
太好了!您现在可以在浏览器中使用上传的模型文件的一些实际代码了。
- 加载和使用托管的 TensorFlow.js 模型
此时,您可以测试是否加载了包含一些数据的已上传 TensorFlow.js 模型,以检查模型是否有效。
现在,您将在下方看到的示例输入数据看起来比较神秘(数字数组),下一部分将说明这些数据的生成方式。暂时先用数字数组查看 在这个阶段,重要的是测试模型是否无错误地提供答案。
将以下代码添加到 script.js 文件的末尾,并务必将 MODEL_JSON_URL 字符串值替换为您在将文件上传到 Glitch 资源文件夹时生成的 model.json 文件的路径。上一步。(请注意,您只需在 Glitch 中点击 assets 文件夹中的文件即可找到该文件的网址)。
请阅读下方新代码中的注释,了解每行的代码用途:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
现在,如果项目设置正确,使用加载的模型预测从传递给它的输入的结果时,您应该会看到类似如下内容输出到控制台窗口:
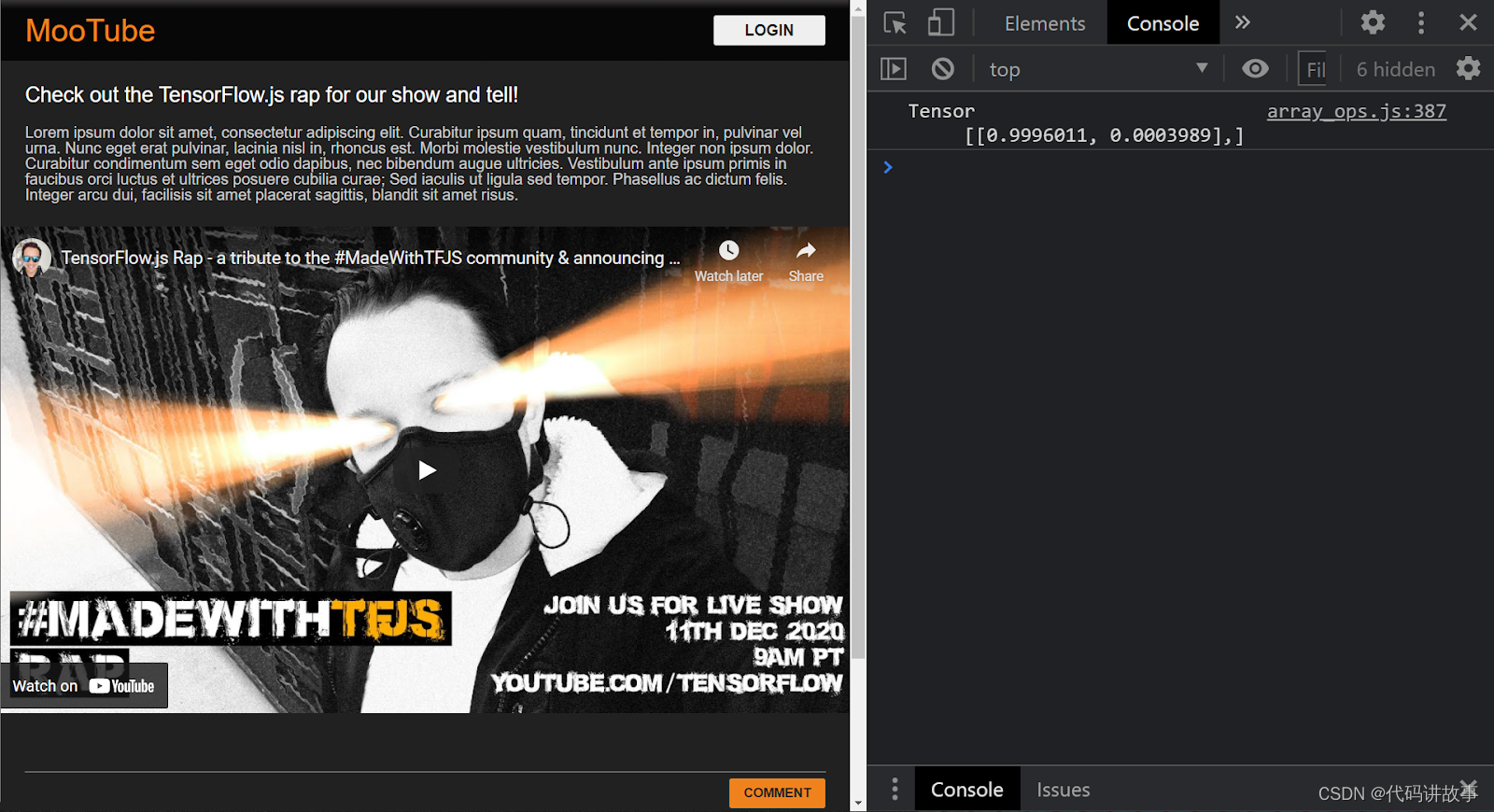
在控制台中,您会看到 2 个数字:
0.9996011
0.0003989
虽然这可能看起来很模糊,但这些数字实际上表示模型认为分类是针对您提供的输入的概率。但它们代表什么?
如果您从本地机器上的已下载模型文件打开 labels.txt 文件,您会看到它也包含 2 个字段:
错误
正确
因此,在本例中,模型表示99.96011% (在结果对象中显示为 0.9996011)您已提供的输入(其值[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]是非垃圾邮件(即 False)。
请注意,false 是 labels.txt 中的第一个标签,由控制台输出中的第一个输出表示,可让您知道输出预测与什么相关。
奖励知识:预测的输出可能会因您使用的模型架构及其训练所预测的内容而变化。一些经过训练的模型甚至可能具有超过 2 个标签以用于预测。假设模型经过训练,可对输入的句子是英语、法语还是西班牙语进行分类。在这种情况下,您可能有一个包含 3 个输出(例如“EN”、“FR”、“SP”)的 labels.txt,而不是输出到控制台的 2 个数字(您看到的是 3)。不过,您可以像在这里一样查询概率。
好了,您现在已经知道如何解读输出了,但实际输入数字到底是什么呢?如何将句子转换为此格式以供模型使用?为此,您需要了解标记化和张量。请继续阅读!
- 令牌化和张量
词法单元化
因此,事实证明机器学习模型只能接受大量数字作为输入。为什么呢?从本质上讲,这是因为机器学习模型实际上是一连串的链式运算,所以如果您向其传递非数字的内容,将会难以处理。那么现在的问题是如何将句子转换为数字,以便与加载的模型结合使用?
具体过程因模型而异,但对于这个模型,您下载的模型文件中还有一个名为 vocab, 的文件,这是您编码数据的关键。
接下来,使用计算机上的本地文本编辑器打开 vocab,您会看到如下内容:
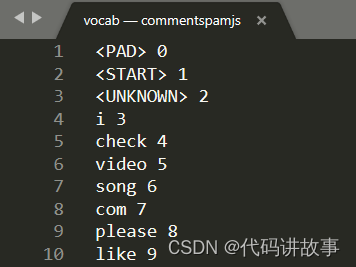
从本质上讲,这是一个对照表,介绍了如何将模型学习的有意义的字词转换为它可以理解的数字。文件 <PAD>、<START> 和 <UNKNOWN> 顶部还有一些特殊情况:
<PAD> - “内边距”的缩写。事实证明,无论模型的句子长度有多长,机器学习模型的输入都一样固定。使用的模型要求输入的内容始终有 20 个数字(这由模型创建者定义,如果您重新训练模型,可以进行更改)。因此,如果您有像“我喜欢视频”这样的短语,则需要使用 0 表示数组中剩余的空间,该空间表示 <PAD> 令牌。如果句子超过 20 个字,您需要将其拆分以满足此要求,并对许多较小的句子进行多个分类。
<START> - 这只是表示语句开始的第一个标记。在前面的步骤示例中,您会注意到以“1”开头的数字数组表示 <START> 令牌。
<UNKNOWN> - 您可能已经猜到,如果此字词中不存在该字词,只需使用 <UNKNOWN> 令牌(表示为“2”)作为数字即可。
对于每个其他字词,它要么存在于查找中,它具有与之关联的特殊编号,您就要使用它,或者它不存在,在这种情况下,您应改为使用 <UNKNOWN> 令牌编号。
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
您现在可以看到,这是一个包含 4 个字词的句子,其余是 或 词法单元,数组中有 20 个数字。好,我说的更有道理
我实际上写的这句话是“我爱我的狗”。从上面的屏幕截图中可以看出,“I”已转换为数字“3”,这是正确的。如果您查找其他字词,也可以找到对应的数字。
词汇表中的这些字词是如何挑选的,为什么是特别的? 对于像这样的语言模型来说,学习哪些字词彼此相似,以及针对特定上下文(例如垃圾内容与非垃圾内容)的重要指标会涉及使用预学习嵌入,这听起来很复杂,但实际上简单易懂。嵌套背后的理念是将字词转换为数字,整个正文中的每个字词都会获得一个数字。嵌入是与指定字词相关联的向量,通过为字词建立“方向”来确定该字词的情感。例如,垃圾评论消息中常用的字词最终会使其指向相似的方向,不常使用的字词将指向相反的方向。这些称为“嵌入”。通过“预先学习”的嵌入,您将从大量文本中积累了情感。相比从零开始,您应该可以更快地找到解决方案。
张量
最后还有一个难关,机器学习模型将接受您的数字输入。您必须将数字数组转换为所谓的张量,是的,您猜到了,TensorFlow 就是以这些命名 - 张量流动模型。
什么是张量?
TensorFlow.org 的官方定义是:
“张量是类型相同的多维数组。所有张量都是不可变的:您永远无法更新某个张量的内容,而只能创建新的张量。"
简单来说,它只是一个复杂数组中任意维度的一个数组,它具有一些内置于 TensorFlow 对象中的其他函数,对我们作为机器学习开发者来说非常有用。但需要注意的是,Tensors 仅存储 1 种类型的数据(例如所有整数或所有浮点数),并且一旦创建完毕,便无法再更改张量的内容,因此您可以将它视为数字的永久存储盒!
别担心。至少,您可以把它想象成与机器学习模型配合使用的多维存储机制,直到您深入了解一本好书(就像这本书一样) - 如果您想详细了解张量,那么我们强烈建议您使用这种机制及使用方法
总结:编码张量和令牌化
那么,如何在代码中使用该 vocab 文件呢?这个问题问得好!
作为 JS 开发者,此文件本身对您毫无用处。如果只是导入和使用 JavaScript 对象,效果会好很多。您可以看到,如何将此文件中的数据转换为更像下面这种格式:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
使用常用的文本编辑器,您可以通过一些查找和替换操作,轻松将 vocab 文件转换为这种格式。不过,您也可以使用此预制工具更轻松地完成此操作。
提前执行这项工作,并以正确的格式保存 vocab 文件,即可避免每次网页加载时都进行这种转换和解析,而这会浪费 CPU 资源。更好的是,JavaScript 对象具有以下属性:
“对象属性名称可以是任何有效的 JavaScript 字符串,也可以是可以转换为字符串的任何字符串,包括空字符串。但是,任何不是有效的 JavaScript 标识符的属性名称(例如,带有空格或连字符的属性名称,或以数字开头的属性名称)都只能用方括号表示法表示。
因此,只要您使用方括号表示法,就可以通过这种简单的转换创建相当高效的对照表。
转换为更实用的格式
通过文本编辑器或在此处使用此工具自行将词汇表文件转换为上述格式。将生成的输出保存为 www 文件夹中的 dictionary.js。
在 Glitch 上,您只需在此位置创建一个新文件,然后粘贴转换结果即可进行保存,如下所示:
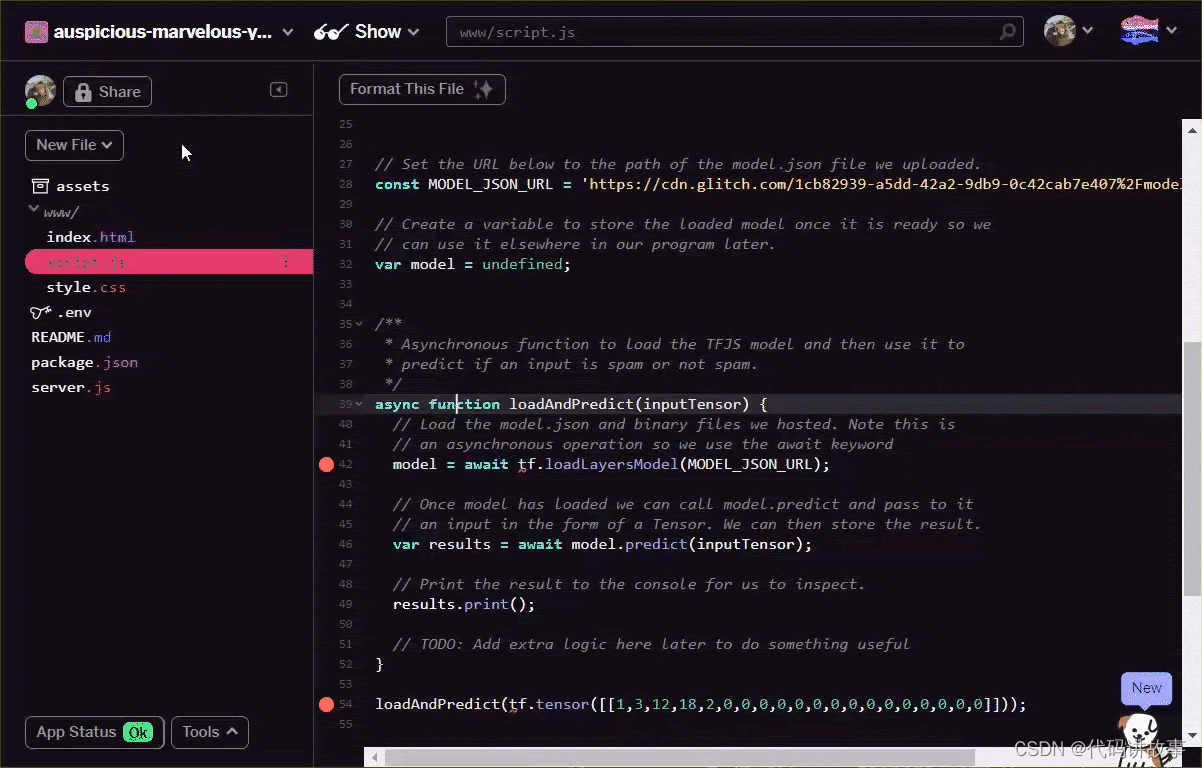
保存上述格式的 dictionary.js 文件后,您现在可以将以下代码添加到 script.js 的最前面,以导入您刚刚编写的 dictionary.js 模块。您还可以在此处定义一个额外的常量 ENCODING_LENGTH,以便您知道代码中稍后需要填充多少内容,并利用 tokenize 函数将单词数组转换为合适的张量,该张量可用作模型的输入。
请查看以下代码中的注释,详细了解各行的作用:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
现在,返回到 handleCommentPost() 函数,并替换为这个新版函数。
查看与您添加的内容相关的代码:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
最后,如果检测到评论为垃圾内容,请更新 loadAndPredict() 函数以设置样式。
目前,您可以只更改样式,但稍后可以选择将评论留在某种审核队列中,或者停止评论的发送。
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
- 实时更新:Node.js + Websocket
现在,您已具备了可检测垃圾内容的正常运行前端,接下来需要解决的最后一点是结合使用 Node.js 和一些 Websocket,以实现实时通信,并实时更新添加的任何非垃圾内容评论。
接口
Socket.io 是将 Nodesocket.与 Node.js 配合使用时最常用的一种方式(在编写时)。接下来,告知 Glitch 您要在 build 中添加 Socket.io 库,方法是在顶级目录(www 文件夹的父文件夹中)修改 package.json,将 socket.io 添加为其中一个依赖项:
JSON 文件
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
太好了!更新后,在 www 文件夹中下一次更新 index.html,以包含 socket.io 库。
只需将下面这行代码放置在 script.js 的 HTML 脚本代码导入语句上方、index.html 文件末尾附近即可:
index.html
<script src="/socket.io/socket.io.js"></script>
您的 index.html 文件中现在应包含 3 个脚本标记:
第一次导入 TensorFlow.js 库
您刚刚导入的第二个导入 socket.io
最后一个应导入 script.js 代码。
接下来,修改 server.js 以在节点内设置 socket.io,并创建一个简单的后端以中继发送到所有连接的客户端的消息。
有关 Node.js 代码作用的说明,请参阅下面的代码注释:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
太好了!您现在拥有了一个监听 socket.io 事件的网络服务器。也就是说,当客户端有新评论时,您有一个 comment 事件,而服务器会发出 remoteComment 事件,客户端代码将监听这些事件,以呈现远程评论。因此,最后需要将 socket.io 逻辑添加到客户端代码中,以便发出并处理这些事件。
首先,将以下代码添加到 script.js 的末尾,以连接到 socket.io 服务器,并监听 / 处理收到的 RemoteComment 事件:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
最后,向 loadAndPredict 函数添加一些代码,以便在评论不是垃圾内容时发出 socket.io 事件。如此一来,您便可使用这条新注释更新其他已连接的客户端,因为此消息的内容将通过您之前编写的 server.js 代码中继给它们。
只需使用现有的 loadAndPredict 函数替换以下代码,即可向最终的垃圾检查添加 else 语句;如果评论不是垃圾评论,调用 socket.emit() 以发送所有评论数据:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
太棒了!如果操作正确,您现在应该能够打开 index.html 页面的 2 个实例。
当您发布非垃圾内容的评论时,应该很快就会看到这些评论在另一个客户端上呈现了。如果垃圾评论是垃圾评论,系统绝不会发送,只是在生成该评论的前端被标记为垃圾评论,如下所示:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!