构建强大的产品级NLP系统:PaddleNLP Pipelines端到端流水线框架解析

搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)

专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源)
前人栽树后人乘凉,本专栏提供资料:
- 推荐系统算法库,包含推荐系统经典及最新算法讲解,以及涉及后续业务落地方案和码源
- 本专栏会持续更新业务落地方案以及码源。同时我也会整理总结出有价值的资料省去你大把时间,快速获取有价值信息进行科研or业务落地。帮助你快速完成任务落地,以及科研baseline
构建强大的产品级NLP系统:PaddleNLP Pipelines端到端流水线框架解析
1. NLP流水线系统框架-Pipelines简介

PaddleNLP Pipelines 是一个端到端NLP流水线系统框架,面向 NLP 全场景,帮助用户低门槛构建强大产品级系统。NLP流水线系统特色
-
全场景支持:依托灵活的插拔式组件产线化设计,支持各类 NLP 场景任务,包括:信息抽取、情感倾向分析、阅读理解、检索系统、问答系统、文本分类、文本生成等。
-
低门槛开发:依托丰富的预置组件,像搭积木一样快速构建产品级系统,预置组件覆盖文档解析、数据处理、模型组网、预测部署、Web 服务、UI 界面等全流程系统功能。
-
高精度预测:基于前沿的预训练模型、成熟的系统方案,可构建效果领先的产品级系统,如NLP流水线系统中预置的语义检索系统、阅读理解式智能问答系统等。
-
灵活可定制:除深度兼容 PaddleNLP 模型组件外,还可嵌入飞桨生态下任意模型、AI 开放平台算子、其它开源项目如 Elasticsearch 等作为基础组件,快速扩展,从而实现任意复杂系统的灵活定制开发。
1.0 组件
Pipepelines提供了很多工具来定制化您的NLP系统,下面就介绍一下NLP的这些组件:
| Component | 描述 |
|---|---|
| Documents, Answers and Labels | 核心数据结构 |
| Document Stores | 用来存储数据,连接各种各样的数据库,例如MySQL, Elastic Search, Milvus, Faiss等 |
| Pipelines | Pipelines使得各个节点能够很容易的进行配置 |
| 常用的Pipelines | 一些模板Pipeline,覆盖常用的一些Case,例如SemanticSearchPipeline,SemanticSearchPipeline |
| REST API | 能快速的把Pipelines部署成一个Service |
1.1 节点
Pipelines提供了多种节点,底层是基于PaddleNLP的模型进行了实现,实现过程类似与Taskflow,因此每个节点都可以单独进行调用。例如,你想用一个阅读理解模型做问答,你只需要提供文档和问题即可。这样做的一个好处是可以直接查看输入和输出,适合调试和单个任务的调用。
节点是处理和对文本进行路由的核心,包括预处理,检索等等,节点是通过Pipeline来进行结合在一起的,拔插式设计,可以很容易对其中的节点进行定制,使用Pipeline.run()函数,Pipeline就会调用每个节点的run函数。如果一次性需要传入批量数据,则使用Pipeline.run_batch()函数,Pipeline会调用每个节点的run_batch()函数。下面是一些节点的介绍:
| 节点 | 类 | 描述 |
|---|---|---|
| FileClassifier | FileTypeClassifier | 用于区分文本,pdf,Markdown,docx等文件的 |
| FileConverters | PDFToTextConverter, DocxToTextConverter, AzureConverter, ImageToTextConverter, MarkdownConverter | 用于清理和切分文档 |
| PreProcessor | PreProcessor | 用于清理和切分文档 |
| Retriever | BM25Retriever, ElasticsearchRetriever, DensePassageRetriever | 用于在Document Store查找与给定query相关的文档 |
| Reader | ErnieReader | 给定问题下,在文档中查找出答案 |
| Ranker | ERNIERanker | 根据Query对文档进行重排序 |
| … | … | … |
是让Taskflow兼容支持run和run_batch方法,这样可以直接放入Pipelines里面使用
!pip install paddlenlp==2.5.2
!pip install pandas
!pip install paddle-pipelines
- demo展示
from pipelines.nodes import ErnieReader
from pipelines.schema import Document
documents = [Document(content='防水作为目前高端手机的标配,特别是苹果也支持防水之后,国产大多数高端旗舰手机都已经支持防水。虽然我们真的不会故意把手机放入水中,但是有了防水之后,用户心里会多一重安全感。那么近日最为火热的小米6防水吗?小米6的防水级别又是多少呢? 小编查询了很多资料发现,小米6确实是防水的,但是为了保持低调,同时为了不被别人说防水等级不够,很多资料都没有标注小米是否防水。根据评测资料显示,小米6是支持IP68级的防水,是绝对能够满足日常生活中的防水需求的。',
content_type='text'),
]
reader = ErnieReader(model_name_or_path="ernie-gram-zh-finetuned-dureader-robust")
result = reader.predict(
query="高端手机的标配是什么?",
documents=documents,
top_k=10
)
print(result)
1.2 Pipelines
Pipelines的设计初衷是通过NLP不同节点的结合,用户可以创造强大和定制化的系统。当把节点加入到Pipeline,用户可以定义数据怎么流入系统,怎么进行预处理。在这种简化的数据流的逻辑下,用户可以构建更复杂的路由逻辑,例如包含一些决策节点逻辑。
p = Pipeline()
p.add_node(component=retriever, name="Retriever", inputs=["Query"])
p.add_node(component=ranker, name="Ranker", inputs=["Retriever"])
result = p.run(query="衡量酒水的价格的因素有哪些?")
也可以使用内置的一些常用case的节点:
#Step5: Initialize a SemanticSearchPipeline and ask questions
from pipelines import SemanticSearchPipeline
pipeline = SemanticSearchPipeline(retriever, ranker)
prediction = pipeline.run(query="衡量酒水的价格的因素有哪些?")
解释一下决策节点,比如下面的加了一个Query classifier的决策节点逻辑:
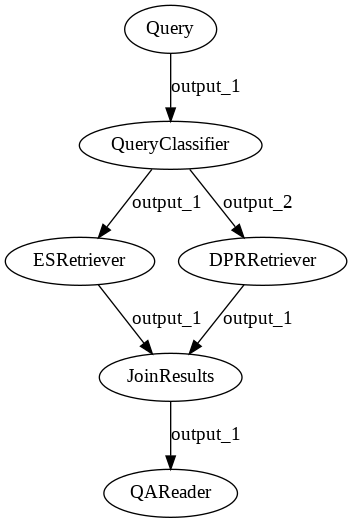
让Pipelines支持复杂的场景,比如多路召回,体现Pipelines的可拓展性。
1.3 REST API

为了部署一个系统,比如部署一个语义检索系统,你需要启动一个服务,来处理不同应用过来的请求,REST API是为了生产环境而设计的。你可以使用YAML文件来加载Pipelines,然后通过HTTP请求来跟Pipelines进行交互。
比如yaml文件的配置如下:
pipelines:
- name: query # a sample extractive-qa Pipeline
type: Query
nodes:
- name: Retriever
inputs: [Query]
- name: Ranker
inputs: [Retriever]
然后使用下面的请求:
curl -X POST -k \
http://localhost:8891/query \
-H 'Content-Type: application/json' \
-d '{"query": "北京市有多少个行政区?","params": {"Retriever": {"top_k": 5}, "Ranker":{"top_k": 5}}}'
- 如果有需要可以查阅swagger文档,目前Pipelines已经支持swagger的方式访问API:
1.4 Taskflow/huggingface/pipelines区别与联系
-
Taskflow:接入的是PaddleNLP的各个子任务,开箱即用的产业级NLP预置任务能力,无需训练,一键预测。
-
huggingface pipelines: 各种复杂NLP任务的简单接口,跟PaddleNLP的Taskflow一样的功能。
-
Paddle-pipelines: 能够实现各个NLP任务的流水线化,构成一个NLP应用系统,包括存储,NLP各个任务节点,服务化API,UI界面等等。
- 联系:Taskflow实现的类似Pipelines实现的各个节点的实现。
1.5 pipelines结构
├── API.md # API文档
├── benchmarks # Benchmark
│ └── README.md
├── docker # Docker打包库【可选】
│ ├── create_index.sh
│ ├── dense_qa.yaml
│ ├── docker-compose-gpu.yml
│ ├── docker-compose.yml
│ ├── Dockerfile
│ ├── Dockerfile-GPU
│ ├── README.md
│ ├── run_client.sh
│ ├── run_server.sh
│ ├── semantic_search.yaml
│ ├── start_compose.sh
│ └── start.sh
├── examples # 基于Pipelines应用的开发【必须】
│ ├── FAQ
│ ├── question-answering
│ └── semantic-search
├── FAQ.md # FAQ
├── pipelines # Pipelines核心库【必须】
│ ├── data_handler # 把数据转换成dataset,用法可以参考DensePassageRetriever的使用
│ ├── document_stores # 存储节点库
│ ├── errors.py
│ ├── __init__.py
│ ├── nodes # 节点添加的库
│ ├── pipelines # Pipelines流水线
│ ├── schema.py
│ └── utils
├── README.md # 项目的主readme文档
├── requirements.txt 【添加依赖】
├── rest_api # 后台API
│ ├── application.py
│ ├── config.py
│ ├── controller
│ ├── __init__.py
│ ├── pipeline
│ ├── schema.py
│ └── test
├── setup.py # 安装
├── ui # 前端界面/对gradio熟悉的可以选择gradio/Vue
│ ├── baike_qa.csv
│ ├── dureader_search.csv
│ ├── __init__.py
│ ├── insurance_faq.csv
│ ├── utils.py
│ ├── webapp_faq.py
│ ├── webapp_question_answering.py
│ └── webapp_semantic_search.py
├── utils # 离线建库模板
│ └── offline_ann.py
└── VERSION.txt
2. 案例快速讲解入门
Paddle-Pipelines已经提供了Docker,最快速的方法是使用Docker的方式直接运行,也可以根据官方教程从头到尾安装。下面带领大家快速体验一下Pipelines的代码:
2.1 单个节点的使用
下面是示例代码:
from pipelines.nodes import ErnieReader
from pipelines.schema import Document
documents = [Document(content='防水作为目前高端手机的标配,特别是苹果也支持防水之后,国产大多数高端旗舰手机都已经支持防水。虽然我们真的不会故意把手机放入水中,但是有了防水之后,用户心里会多一重安全感。那么近日最为火热的小米6防水吗?小米6的防水级别又是多少呢? 小编查询了很多资料发现,小米6确实是防水的,但是为了保持低调,同时为了不被别人说防水等级不够,很多资料都没有标注小米是否防水。根据评测资料显示,小米6是支持IP68级的防水,是绝对能够满足日常生活中的防水需求的。',
content_type='text'),
]
reader = ErnieReader(model_name_or_path="ernie-gram-zh-finetuned-dureader-robust")
result = reader.predict(
query="高端手机的标配是什么?",
documents=documents,
top_k=10
)
2.2 通用节点使用
多个节点组合使用,下面是Pipelines的示例代码
from pipelines.document_stores import FAISSDocumentStore
from pipelines.nodes import DensePassageRetriever, ErnieRanker
#Step1: Preparing the data
documents = [
{'content': '金钱龟不分品种,只有生长地之分,在我国主要分布于广东、广西、福建、海南、香港、澳门等地,在国外主要分布于越南等亚热带国家和地区。',
'meta': {'name': 'test1.txt'}},
{'content': '衡量酒水的价格的因素很多的,酒水的血统(也就是那里产的,采用什么工艺等);存储的时间等等,酒水是一件很难标准化得商品,只要你敢要价,有买的那就值那个钱。',
'meta': {'name': 'test2.txt'}}
]
#Step2: Initialize a FaissDocumentStore to store texts of documents
document_store = FAISSDocumentStore(embedding_dim=768)
document_store.write_documents(documents)
#Step3: Initialize a DenseRetriever and build ANN index
retriever = DensePassageRetriever(document_store=document_store, query_embedding_model="rocketqa-zh-base-query-encoder",embed_title=False)
document_store.update_embeddings(retriever)
#Step4: Initialize a Ranker
ranker = ErnieRanker(model_name_or_path="rocketqa-base-cross-encoder")
#Step5: Initialize a SemanticSearchPipeline and ask questions
from pipelines import SemanticSearchPipeline
pipeline = SemanticSearchPipeline(retriever, ranker)
prediction = pipeline.run(query="衡量酒水的价格的因素有哪些?")
2.3 定制化的Pipeline
#text pipeline for semantic search
from pipelines.pipelines import Pipeline
p = Pipeline()
p.add_node(component=retriever, name="Retriever", inputs=["Query"])
p.add_node(component=ranker, name="Ranker", inputs=["Retriever"])
p.run(query="衡量酒水的价格的因素有哪些?")
#file example for indexing
from pipelines.nodes import TextConverter, Preprocessor
text_converter = TextConverter()
preprocessor = Preprocessor()
p = Pipeline()
p.add_node(component=text_converter, name="TextConverter", inputs=["File"])
p.add_node(component=preprocessor, name="PreProcessor", inputs=["TextConverter"])
p.add_node(component=retriever, name="Retriever", inputs=["PreProcessor"])
p.add_node(component=document_store, name="DocumentStore", inputs=["Retriever"])
p.run(file_paths=["filename.txt"])
用户实例化一个Pipeline,加入定义的节点即可构建一些特定功能的流水线。
- 还可以做多路召回,并加入决策节点这些高级用法,代码示例如下:
#关键字和DPR的多路召回
p = Pipeline()
p.add_node(component=es_retriever, name="ESRetriever", inputs=["Query"])
p.add_node(component=dpr_retriever, name="DPRRetriever", inputs=["Query"])
p.add_node(component=JoinDocuments(join_mode="concatenate"), name="JoinResults", inputs=["ESRetriever", "DPRRetriever"])
p.add_node(component=reader, name="ranker", inputs=["JoinResults"])
res = p.run(query="衡量酒水的价格的因素有哪些?", params={"ESRetriever": {"top_k": 1}, "DPRRetriever": {"top_k": 3}})
#加入决策节点,上一些策略
class QueryClassifier(BaseComponent):
outgoing_edges = 2
def run(self, query):
if "?" in query:
return {}, "output_1"
else:
return {}, "output_2"
p = Pipeline()
p.add_node(component=QueryClassifier(), name="QueryClassifier", inputs=["Query"])
p.add_node(component=es_retriever, name="ESRetriever", inputs=["QueryClassifier.output_1"])
p.add_node(component=dpr_retriever, name="DPRRetriever", inputs=["QueryClassifier.output_2"])
p.add_node(component=JoinDocuments(join_mode="concatenate"), name="JoinResults",
inputs=["ESRetriever", "DPRRetriever"])
p.add_node(component=reader, name="QAReader", inputs=["JoinResults"])
res = p.run(query="衡量酒水的价格的因素有哪些?", params={"ESRetriever": {"top_k": 1}, "DPRRetriever": {"top_k": 3}})
3. 开发指南详解
注意事项:
- 先开发Pipelines核心库,再开发后台和前端
- 设计方案解耦合,通过新增节点的方式,保证可拓展性,一般不建议改动大的框架,节点那些的命名简单易懂,优先使用Taskflow的方式。
- 后端调用Pipelines的方式是使用了yaml文件,需要写yaml文件。
- 开发过程中编码的风格跟现有的Pipelines的代码风格保持一致,包括写注释和函数命名。

3.1 DocumentStore开发
- 继承KeywordDocumentStore/SQLDocumentStore
- 实现增删查改的基础功能
示例代码如下,以Milvus为例:
class Milvus2DocumentStore(SQLDocumentStore):
def __init__(...):
# save init parameters to enable export of component config as YAML
self.set_config(...)
def write_documents(...):
......
def update_embeddings(...):
........
def query_by_embedding(...):
......
def delete_documents(...):
......
def delete_index(..):
.......
def get_all_documents(...):
.......
def get_document_by_id(...):
.......
def get_documents_by_id(...):
......
源代码实现请参考 https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/pipelines/document_stores/base.py
现在已经把主流的Elastic Search, Milvus 2.1, Faiss, sqlite等库集成进去,后续支持Jina等向量索引库可以参考这个。输入格式如下:
from pipelines.document_stores import Milvus2DocumentStore
document_store = Milvus2DocumentStore()
documents = [
Document(
'content'=DOCUMENT_TEXT_HERE
'meta'={'name': DOCUMENT_NAME, ...}
),
...
]
document_store.write_documents(dicts)
3.2 节点开发
- 创建一个新类并继承BaseComponent
- 定义这个run()函数,这是Pipelines执行的函数,必须实现。run函数可以定义节点所需要配置的参数以及期待上一个节点传入的数据参数,例如:Documents,query,file_paths等等。
- run()函数需要返回一个tuple,第一个返回值是传给下一个节点的字典类型的数据,第二个值是输出的边的名称,通常是output_1。
- 定义这个run_batch()函数,使得pipelines能够输入批量的query进行处理。输入的参数配置可以跟run函数一样。
- run_batch()函数返回的是一个tuple,第一个返回值是一个字典,第二个是输出的边的名称,通常是output_1.
- 可选地,可以增加一个output[“_debug”]选项,用户在切换debug模式的时候可以得到这个pipeline的信息。
模板如下:
from pipelines.nodes.base import BaseComponent
class NodeTemplate(BaseComponent):
# If it's not a decision node, there is only one outgoing edge
outgoing_edges = 1
def run(self, query: str, my_arg: Optional[int] = 10):
# Insert code here to manipulate the input and produce an output dictionary
...
output={
"documents": ...,
"_debug": {"anything": "you want"}
}
return output, "output_1"
def run_batch(self, queries: List[str], my_arg: Optional[int] = 10):
# Insert code here to manipulate the input and produce an output dictionary
...
output={
"documents": ...,
}
return output, "output_1"
由于语义检索还需要排序模块,所以需要开发一个排序节点,排序节点ErnieRanker的示例如下:
class BaseRanker(BaseComponent):
@abstractmethod
def predict(...):
.......
@abstractmethod
def predict_batch(...):
.......
def run(...):
......
def run_batch(...):
......
class ErnieRanker(BaseRanker):
def __init__(...):
self.set_config(...)
def predict(...):
......
def predict_batch(....):
......
DensePassageRetriever的示例如下:
class BaseRetriever(BaseComponent):
def run(...):
......
def run_batch(...):
......
def run_query_batch(...):
......
def run_query(...):
......
@abstractmethod
def retrieve(...):
......
@abstractmethod
def retrieve_batch(...):
......
class DensePassageRetriever(BaseRetriever):
def __init__(...):
self.set_config(...) # yaml的参数保存
def retrieve(...):
.....
def retrieve_batch(...):
......
run : 单个处理,比如搜索,就是query进行后,调用模型抽取向量,然后检索的功能。
run_batch:批量处理
如果实现,则默认调用父类的功能,如果有定制化功能,至少实现一个run函数
3.3 Pipeline流水线开发
-
实例化Pipeline,添加对应的节点。
-
实现run函数和run_batch函数实现,如果不是先,则会继承默认的。
class BaseStandardPipeline(ABC):
def add_node(self, component, name: str, inputs: List[str]):
......
def get_node(self, name: str):
......
def set_node(self, name: str, component):
....
def draw(self, path: Path = Path("pipeline.png")):
....
def save_to_yaml(self, path: Path, return_defaults: bool = False):
....
@classmethod
def load_from_yaml(cls, path: Path, pipeline_name: Optional[str] = None, overwrite_with_env_variables: bool = True)
.....
def run_batch(self,
queries: List[str],
params: Optional[dict] = None,
debug: Optional[bool] = None):
......
def get_nodes_by_class(self, class_type) -> List[Any]:
.....
class SemanticSearchPipeline(BaseStandardPipeline):
"""
Pipeline for semantic search.
"""
def __init__(self,
retriever: BaseRetriever,
ranker: Optional[BaseRanker] = None):
"""
:param retriever: Retriever instance
"""
self.pipeline = Pipeline()
self.pipeline.add_node(component=retriever,
name="Retriever",
inputs=["Query"])
if ranker:
self.pipeline.add_node(component=ranker,
name="Ranker",
inputs=["Retriever"])
def run(self,
query: str,
params: Optional[dict] = None,
debug: Optional[bool] = None):
"""
:param query: the query string.
:param params: params for the `retriever` and `reader`. For instance, params={"Retriever": {"top_k": 10}}
:param debug: Whether the pipeline should instruct nodes to collect debug information
about their execution. By default these include the input parameters
they received and the output they generated.
All debug information can then be found in the dict returned
by this method under the key "_debug"
"""
output = self.pipeline.run(query=query, params=params, debug=debug)
return output
3.4 REST API开发
开发文档请参考:https://fastapi.tiangolo.com/zh/ ,后台的目录结构如下:
rest_api/
├── application.py # fastAPI程序的启动函数
├── config.py # 配置文件,路径,配置文件路径
├── controller # 定义的Restful API处理逻辑
│ ├── document.py
│ ├── errors
│ ├── feedback.py
│ ├── file_upload.py
│ ├── __init__.py
│ ├── __pycache__
│ ├── router.py
│ ├── search.py
│ └── utils.py
├── schema.py # 定义的query,response等的数据字段
-
创建一个应用的yaml文件,参考rest_api下面的pipeline目录
-
实现一个controller的router文件,写业务逻辑,调用pipelines组件。
3.4.1 创建一个yaml文件
pipelines/rest_api/pipeline/,定义各种节点,以下是语义索引的yaml文件示例:
version: '1.1.0'
components: # define all the building-blocks for Pipeline
- name: DocumentStore
type: ElasticsearchDocumentStore # consider using Milvus2DocumentStore or WeaviateDocumentStore for scaling to large number of documents
params:
host: localhost
port: 9200
index: dureader_robust_query_encoder
embedding_dim: 312
- name: Retriever
type: DensePassageRetriever
params:
document_store: DocumentStore # params can reference other components defined in the YAML
top_k: 10
query_embedding_model: rocketqa-zh-nano-query-encoder
passage_embedding_model: rocketqa-zh-nano-para-encoder
embed_title: False
- name: Ranker # custom-name for the component; helpful for visualization & debugging
type: ErnieRanker # pipelines Class name for the component
params:
model_name_or_path: rocketqa-nano-cross-encoder
top_k: 3
- name: TextFileConverter
type: TextConverter
- name: ImageFileConverter
type: ImageToTextConverter
- name: PDFFileConverter
type: PDFToTextConverter
- name: DocxFileConverter
type: DocxToTextConverter
- name: Preprocessor
type: PreProcessor
params:
split_by: word
split_length: 1000
- name: FileTypeClassifier
type: FileTypeClassifier
pipelines:
- name: query # Query查询的Pipeline
type: Query
nodes:
- name: Retriever
inputs: [Query]
- name: Ranker
inputs: [Retriever]
- name: indexing # 建索引的Pipeline
type: Indexing
nodes:
- name: FileTypeClassifier
inputs: [File]
- name: TextFileConverter
inputs: [FileTypeClassifier.output_1]
- name: PDFFileConverter
inputs: [FileTypeClassifier.output_2]
- name: DocxFileConverter
inputs: [FileTypeClassifier.output_4]
- name: ImageFileConverter
inputs: [FileTypeClassifier.output_6]
- name: Preprocessor
inputs: [PDFFileConverter, TextFileConverter, DocxFileConverter, ImageFileConverter]
- name: Retriever
inputs: [Preprocessor]
- name: DocumentStore
inputs: [Retriever]
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/pipelines/nodes/file_classifier/file_type.py
在config.py里面配置不同的环境变量方便切换流水线:
QUERY_PIPELINE_NAME = os.getenv("QUERY_PIPELINE_NAME", "query")
INDEXING_PIPELINE_NAME = os.getenv("INDEXING_PIPELINE_NAME", "indexing")
3.4.2 创建一个controller/router
调流水线节点,传入参数,然后使用pipelines.run执行得到结果,返回给客户端,以下是代码示例:
PIPELINE = Pipeline.load_from_yaml(Path(PIPELINE_YAML_PATH),
pipeline_name=QUERY_PIPELINE_NAME)
def query(request: QueryRequest):
"""
This endpoint receives the question as a string and allows the requester to set
additional parameters that will be passed on to the pipelines pipeline.
"""
with concurrency_limiter.run():
result = _process_request(PIPELINE, request)
return result
def _process_request(pipeline, request) -> Dict[str, Any]:
start_time = time.time()
params = request.params or {}
# format global, top-level filters (e.g. "params": {"filters": {"name": ["some"]}})
if "filters" in params.keys():
params["filters"] = _format_filters(params["filters"])
# format targeted node filters (e.g. "params": {"Retriever": {"filters": {"value"}}})
for key in params.keys():
if "filters" in params[key].keys():
params[key]["filters"] = _format_filters(params[key]["filters"])
result = pipeline.run(query=request.query,
params=params,
debug=request.debug)
# Ensure answers and documents exist, even if they're empty lists
if not "documents" in result:
result["documents"] = []
if not "answers" in result:
result["answers"] = []
# if any of the documents contains an embedding as an ndarray the latter needs to be converted to list of float
for document in result["documents"]:
if isinstance(document.embedding, ndarray):
document.embedding = document.embedding.tolist()
logger.info(
json.dumps(
{
"request": request,
"response": result,
"time": f"{(time.time() - start_time):.2f}"
},
default=str))
return
3.4.3 文件类型的处理
- 接收数据并保存到服务器的FILE_UPLOAD_PATH目录下
- 传给Pipelines进行处理
- 根据Pipelines的输出,返回结果给前端
@router.post("/file-upload")
def upload_file(
files: List[UploadFile] = File(...),
# JSON serialized string
meta: Optional[str] = Form("null"), # type: ignore
fileconverter_params: FileConverterParams = Depends(
FileConverterParams.as_form), # type: ignore
preprocessor_params: PreprocessorParams = Depends(
PreprocessorParams.as_form), # type: ignore
):
"""
You can use this endpoint to upload a file for indexing
"""
if not INDEXING_PIPELINE:
raise HTTPException(status_code=501,
detail="Indexing Pipeline is not configured.")
file_paths: list = []
file_metas: list = []
meta_form = json.loads(meta) or {} # type: ignore
if not isinstance(meta_form, dict):
raise HTTPException(
status_code=500,
detail=
f"The meta field must be a dict or None, not {type(meta_form)}")
for file in files:
try:
file_path = Path(
FILE_UPLOAD_PATH) / f"{uuid.uuid4().hex}_{file.filename}"
with file_path.open("wb") as buffer:
shutil.copyfileobj(file.file, buffer)
file_paths.append(file_path)
meta_form["name"] = file.filename
file_metas.append(meta_form)
finally:
file.file.close()
result = INDEXING_PIPELINE.run(
file_paths=file_paths,
meta=file_metas,
params={
"TextFileConverter": fileconverter_params.dict(),
"PDFFileConverter": fileconverter_params.dict(),
"Preprocessor": preprocessor_params.dict(),
},
)
return {'message': "OK"}
3.5 前端开发
- streamlit的文档参考:https://github.com/streamlit/streamlit
- gradio的文档参考:https://gradio.app/docs/
- vue的文档请参考:https://vuejs.bootcss.com/guide/
ui/
├── baike_qa.csv
├── dureader_search.csv
├── __init__.py
├── insurance_faq.csv
├── __pycache__
│ ├── __init__.cpython-37.pyc
│ └── utils.cpython-37.pyc
├── utils.py # 数据交互
├── webapp_faq.py
├── webapp_question_answering.py # 前端界面
└── webapp_semantic_search.py
- 用streamlit的控件实现一个界面
- 在utils.py里面添加数据交互的函数
3.5.1 一般的HTTP请求交互
界面搭建参考:webapp_semantic_search.py
st.session_state.results, st.session_state.raw_json = semantic_search(
question,
top_k_reader=top_k_reader,
top_k_retriever=top_k_retriever) # 参数来源于界面各个控件
与后台数据交互参考:utils.py
def semantic_search(
query,
filters={},
top_k_reader=5,
top_k_retriever=5) -> Tuple[List[Dict[str, Any]], Dict[str, str]]:
"""
Send a query to the REST API and parse the answer.
Returns both a ready-to-use representation of the results and the raw JSON.
"""
url = f"{API_ENDPOINT}/{DOC_REQUEST}"
params = {
"filters": filters,
"Retriever": {
"top_k": top_k_retriever
},
"Ranker": {
"top_k": top_k_reader
}
}
req = {"query": query, "params": params}
response_raw = requests.post(url, json=req)
if response_raw.status_code >= 400 and response_raw.status_code != 503:
raise Exception(f"{vars(response_raw)}")
response = response_raw.json()
if "errors" in response:
raise Exception(", ".join(response["errors"]))
# Format response
results = []
answers = response["documents"]
for answer in answers:
results.append({
"context":
answer["content"],
"source":
answer["meta"]["name"],
"answer":
answer["meta"]["answer"]
if "answer" in answer["meta"].keys() else "",
"relevance":
round(answer["score"] * 100, 2),
"images":
answer["meta"]["images"] if 'images' in answer["meta"] else [],
})
return results, response
3.5.2 文件类型的HTTP交互
前端代码:
if not DISABLE_FILE_UPLOAD:
st.sidebar.write("## 文件上传:")
data_files = st.sidebar.file_uploader(
"",
type=["pdf", "txt", "docx", "png"],
help="文件上传",
accept_multiple_files=True)
for data_file in data_files:
# Upload file
if data_file:
raw_json = upload_doc(data_file)
st.sidebar.write(str(data_file.name) + " ? ")
数据传输:
def upload_doc(file):
url = f"{API_ENDPOINT}/{DOC_UPLOAD}"
files = [("files", file)]
response = requests.post(url, files=files).json()
return response
4. 常见问题汇总
4.1 windows常见问题
4.1.1 pip安装htbuilder包报错,UnicodeDecodeError: 'gbk' codec can't decode byte....
windows的默认字符gbk导致的,可以使用源码进行安装,源码已经进行了修复。
git clone https://github.com/tvst/htbuilder.git
cd htbuilder/
python setup install
4.1.2 Windows出现运行前端报错requests.exceptions.MissingSchema: Invalid URL 'None/query': No scheme supplied. Perhaps you meant http://None/query?
环境变量没有生效,请检查一下环境变量,确保PIPELINE_YAML_PATH和API_ENDPOINT生效:
$env:PIPELINE_YAML_PATH='rest_api/pipeline/semantic_search.yaml'
$env:API_ENDPOINT='http://127.0.0.1:8891'
4.1.3 Windows的GPU运行出现错误:IndexError: index 4616429690595525704 is out of bounds for axis 0 with size 1
paddle.nozero算子出现异常,请退回到PaddlePaddle 2.2.2版本,比如您使用的是cuda 11.2,可以使用如下的命令:
python -m pip install paddlepaddle-gpu==2.2.2.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
4.1.3 Windows运行应用的时候出现了下面的错误:RuntimeError: (NotFound) Cannot open file C:\Users\my_name/.paddleocr/whl\det\ch\ch_PP-OCRv3_det_infer/inference.pdmodel, please confirm whether the file is normal.
这是Windows系统用户命名为中文的原因,详细解决方法参考issue. https://github.com/PaddlePaddle/PaddleNLP/issues/3242
4.2 通用问题
4.2.1 语义检索系统可以跑通,但终端输出字符是乱码怎么解决?
- 通过如下命令设置操作系统默认编码为 zh_CN.UTF-8
export LANG=zh_CN.UTF-8
4.2…2 Linux上安装elasticsearch出现错误 java.lang.RuntimeException: can not run elasticsearch as root
elasticsearch 需要在非root环境下运行,可以做如下的操作:
adduser est
chown est:est -R ${HOME}/elasticsearch-8.3.2/
cd ${HOME}/elasticsearch-8.3.2/
su est
./bin/elasticsearch
4.2.3 Mac OS上安装elasticsearch出现错误 flood stage disk watermark [95%] exceeded on.... all indices on this node will be marked read-only
elasticsearch默认达到95%就全都设置只读,可以腾出一部分空间出来再启动,或者修改 config/elasticsearch.pyml。
cluster.routing.allocation.disk.threshold_enabled: false
4.2.4 nltk_data加载失败的错误 [nltk_data] Error loading punkt: [Errno 60] Operation timed out
在命令行里面输入python,然后输入下面的命令进行下载:
import nltk
nltk.download('punkt')
如果下载还是很慢,可以手动下载,然后放入本地的~/nltk_data/tokenizers进行解压即可。
4.2.5服务端运行报端口占用的错误 [Errno 48] error while attempting to bind on address ('0.0.0.0',8891): address already in use
lsof -i:8891
kill -9 PID # PID为8891端口的进程
4.2.6 faiss 安装上了但还是显示找不到faiss怎么办?
推荐您使用anaconda进行单独安装,安装教程请参考faiss
#CPU-only version
conda install -c pytorch faiss-cpu
#GPU(+CPU) version
conda install -c pytorch faiss-gpu
4.2.7如何更换pipelines中预置的模型?
更换系统预置的模型以后,由于模型不一样了,需要重新构建索引,并修改相关的配置文件。以语义索引为例,需要修改2个地方,第一个地方是utils/offline_ann.py,另一个是rest_api/pipeline/semantic_search.yaml,并重新运行:
首先修改utils/offline_ann.py:
python utils/offline_ann.py --index_name dureader_robust_base_encoder \
--doc_dir data/dureader_dev \
--query_embedding_model rocketqa-zh-base-query-encoder \
--passage_embedding_model rocketqa-zh-base-para-encoder \
--embedding_dim 768 \
--delete_index
然后修改rest_api/pipeline/semantic_search.yaml文件:
components: # define all the building-blocks for Pipeline
- name: DocumentStore
type: ElasticsearchDocumentStore # consider using MilvusDocumentStore or WeaviateDocumentStore for scaling to large number of documents
params:
host: localhost
port: 9200
index: dureader_robust_base_encoder # 修改索引名
embedding_dim: 768 # 修改向量的维度
- name: Retriever
type: DensePassageRetriever
params:
document_store: DocumentStore # params can reference other components defined in the YAML
top_k: 10
query_embedding_model: rocketqa-zh-base-query-encoder # 修改Retriever的query模型名
passage_embedding_model: rocketqa-zh-base-para-encoder # 修改 Retriever的para模型
embed_title: False
- name: Ranker # custom-name for the component; helpful for visualization & debugging
type: ErnieRanker # pipelines Class name for the component
params:
model_name_or_path: rocketqa-base-cross-encoder # 修改 ErnieRanker的模型名
top_k: 3
然后重新运行:
# 指定语义检索系统的Yaml配置文件
export PIPELINE_YAML_PATH=rest_api/pipeline/semantic_search.yaml
# 使用端口号 8891 启动模型服务
python rest_api/application.py 8891
4.2.8运行faiss examples出现了错误:sqlalchemy.exec.OperationalError: (sqlite3.OperationalError) too many SQL variables
python 3.7版本引起的错误,修改如下代码:
# 增加batch_size参数,传入一个数值即可
document_store.update_embeddings(retriever, batch_size=256)
4.2.9 运行后台程序出现了错误:Exception: Failed loading pipeline component 'DocumentStore': RequestError(400, 'illegal_argument_exception', 'Mapper for [embedding] conflicts with existing mapper:\n\tCannot update parameter [dims] from [312] to [768]')
以语义检索为例,这是因为模型的维度不对造成的,请检查一下 elastic search中的文本的向量的维度和semantic_search.yaml里面DocumentStore设置的维度embedding_dim是否一致,如果不一致,请重新使用utils/offline_ann.py构建索引。总之,请确保构建索引所用到的模型和semantic_search.yaml设置的模型是一致的。
4.2.10 安装后出现错误:cannot import name '_registerMatType' from 'cv2'
opencv版本不匹配的原因,可以对其进行升级到最新版本,保证opencv系列的版本一致。
pip install opencv-contrib-python --upgrade
pip install opencv-contrib-python-headless --upgrade
pip install opencv-python --upgrade
4.2.11 安装运行出现 RuntimeError: Can't load weights for 'rocketqa-zh-nano-query-encoder'
rocketqa模型2.3.7之后才添加,paddlenlp版本需要升级:
pip install paddlenlp --upgrade
4.2.12 安装出现问题 The repository located at mirrors.aliyun.com is not a trusted or secure host and is being ignored.
设置pip源为清华源,然后重新安装,可运行如下命令进行设置:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
4.2.13 Elastic search 日志显示错误 exception during geoip databases update
需要编辑config/elasticsearch.yml,在末尾添加:
ingest.geoip.downloader.enabled: false
如果是Docker启动,请添加如下的配置,然后运行:
docker run \
-d \
--name es02 \
--net elastic \
-p 9200:9200 \
-e discovery.type=single-node \
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"\
-e xpack.security.enabled=false \
-e ingest.geoip.downloader.enabled=false \
-e cluster.routing.allocation.disk.threshold_enabled=false \
-it \
docker.elastic.co/elasticsearch/elasticsearch:8.3.3
4.2.14 运行应用的时候出现错误 assert d == self.d
这是运行多个应用引起的,请在运行其他应用之前,删除现有的db文件:
rm -rf faiss_document_store.db
4.2.15 怎样从GPU切换到CPU上运行?
请在对应的所有sh文件里面加入下面的环境变量
export CUDA_VISIBLE_DEVICES=""
4.2.16 运行streamlit前端程序出现错误:AttributeError: module 'click' has no attribute 'get_os_args'
click版本过高导致:
pip install click==8.0
5. 参考文献
https://github.com/deepset-ai/haystack
https://github.com/PaddlePaddle/PaddleNLP
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!