Java实现布隆过滤器
目录
设计初衷
在实际开发中,会遇到很多要判断一个元素是否在某个集合中的业务场景,类似于垃圾邮件的识别,恶意ip地址的访问,缓存穿透等情况。类似于缓存穿透这种情况,有许多的解决方法,如:redis存储null值等,而对于垃圾邮件的识别,恶意ip地址的访问,我们也可以直接用 HashMap 去存储恶意ip地址以及垃圾邮件,然后每次访问时去检索一下对应集合中是否有相同数据。
但是对于大数据量的项目,如,垃圾邮件出现有十几二十万,恶意ip地址出现有上百万,或者从几十亿电话中检索出指定的电话是否在等操作,那么这十几亿的数据就会占据大几G的空间,这个时候就可以考虑一下布隆过滤器了。
?网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)、数据库防止查询击穿, 使用BloomFilter来减少不存在的行或列的磁盘查找?
布隆过滤器定义?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
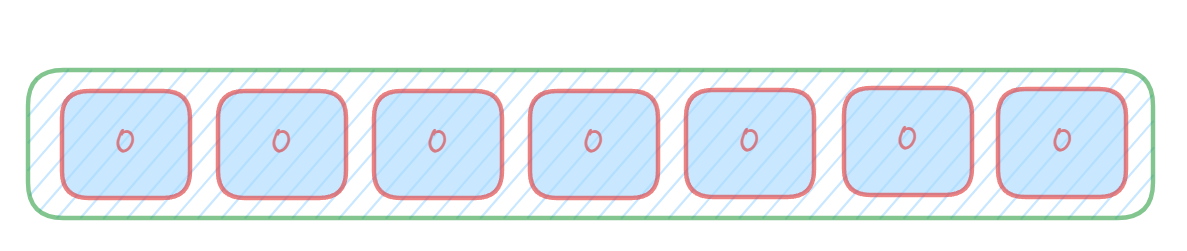
?由一个初始值为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素。?
布隆过滤器可以用于查询一个元素是否存在于一个集合当中,查询结果为以下二者之一:
- 这个元素可能存在于这个集合当中。
- 这个元素一定不存在于这个集合当中。
进行数据插入时:使用多个hash函数对key进行hash运算得到多个整数索引值,对位数组长度进行取模运算得到多个位置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。?
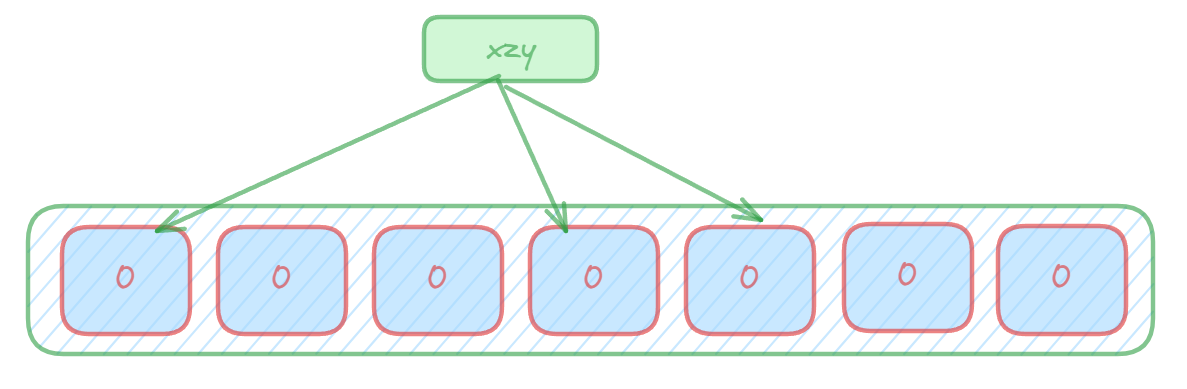
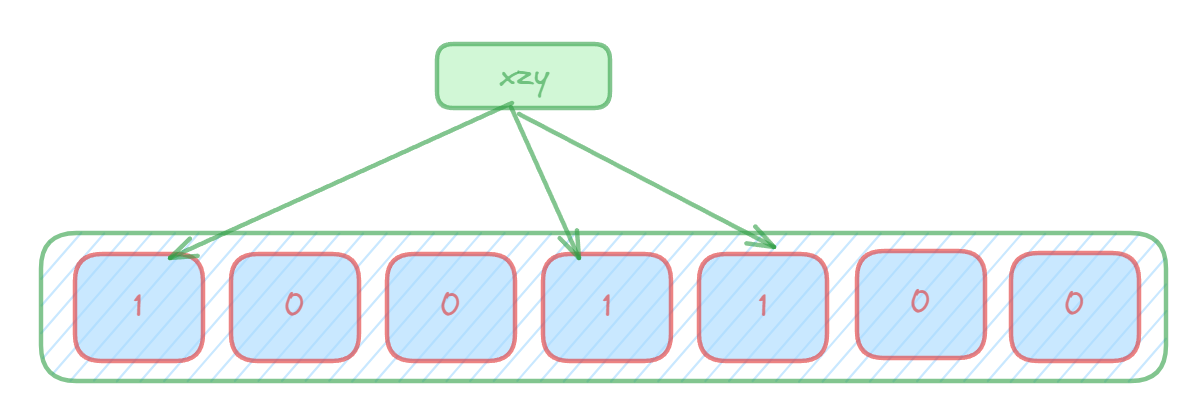
进行数据查询时:将这个key的多个位置上的值取出来,只要有其中一位是零就表示这个key不存在,但如果都是1,则不一定存在对应的key。(也就是有,不一定有,无,就一定无)?
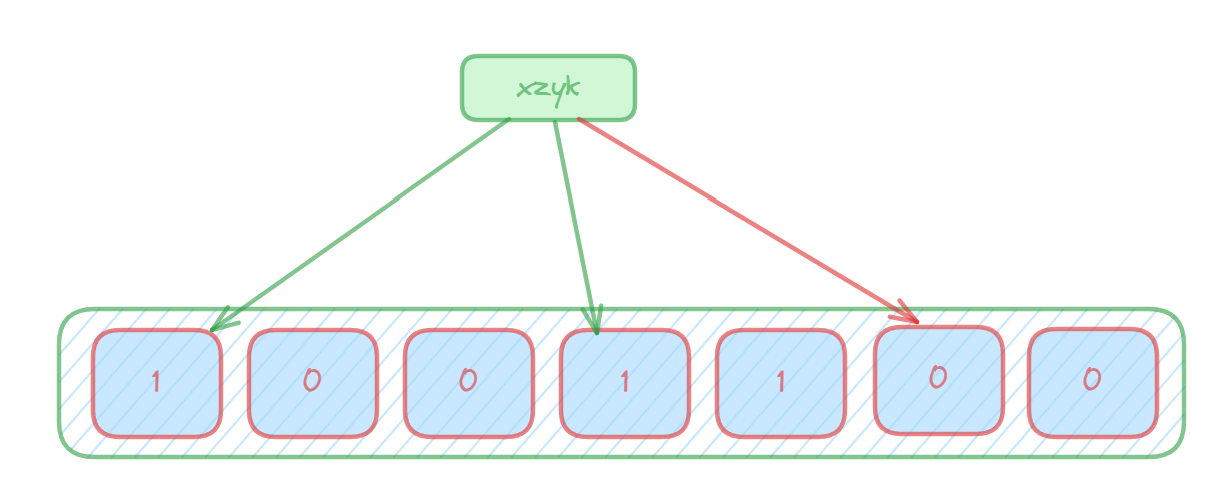 java实现?
java实现?
基于上面理解介绍?,我们现在基于java手撸一个简单布隆过滤器
- bitSize:位图的大小,即位图中的位数。
- bits:位图对象,用于存储元素的映射结果。
- seeds:用于哈希函数的种子数组。
- hashIterations:哈希函数的迭代次数。
class BloomFilter {
private int bitSize;
private BitSet bits;
private int[] seeds;
private int hashIterations;
/**
* @param size 预计元素数量
* @param falsePositive 期望误判率
*/
public BloomFilter(int size, double falsePositive) {
this.bitSize = (int) Math.ceil((size * Math.log(falsePositive)) / Math.log(1.0 / (Math.pow(2.0, Math.log(2.0)))));
this.bits = new BitSet(bitSize);
this.hashIterations = (int) Math.round(Math.log(2.0) * bitSize / size);
this.seeds = new int[hashIterations];
for (int i = 0; i < hashIterations; i++) {
seeds[i] = i + 1;
}
}
/**
* 添加一个元素
*
* @param element 元素
*/
public void add(String element) {
for (int seed : seeds) {
int hash = MurmurHash.hash(element.getBytes(), seed);
bits.set(Math.abs(hash % bitSize), true);
}
}
/**
* 判断一个元素是否存在
*
* @param element 元素
* @return 是否存在
*/
public boolean contains(String element) {
for (int seed : seeds) {
int hash = MurmurHash.hash(element.getBytes(), seed);
if (!bits.get(Math.abs(hash % bitSize))) {
return false;
}
}
return true;
}
/**
* MurmurHash算法
*/
static class MurmurHash {
public static int hash(byte[] data, int seed) {
int m = 0x5bd1e995;
int r = 24;
int h = seed ^ data.length;
int len = data.length;
int pos = 0;
while (len >= 4) {
int k = data[pos] & 0xff;
k |= (data[pos + 1] & 0xff) << 8;
k |= (data[pos + 2] & 0xff) << 16;
k |= (data[pos + 3] & 0xff) << 24;
k *= m;
k ^= k >>> r;
k *= m;
h *= m;
h ^= k;
pos += 4;
len -= 4;
}
switch (len) {
case 3:
h ^= (data[pos + 2] & 0xff) << 16;
case 2:
h ^= (data[pos + 1] & 0xff) << 8;
case 1:
h ^= data[pos] & 0xff;
h *= m;
}
h ^= h >>> 13;
h *= m;
h ^= h >>> 15;
return h;
}
}
}
BloomFilter类表示布隆过滤器,提供了add和contains方法用于添加元素和判断元素是否存在。在构造函数中,根据预计元素数量和期望误判率计算出位数组的大小、哈希函数个数和哈希种子。添加元素时,使用多个哈希函数对元素进行哈希,并将对应的位设置为 1;判断元素是否存在时,同样使用多个哈希函数对元素进行哈希,并检查对应的位是否都为 1。注意,上述代码中的哈希函数使用了 MurmurHash 算法,该算法的性能比较高,适合用于布隆过滤器中。同时,布隆过滤器的误判率随着元素数量的增加而增加,因此在实际使用中需要根据误判率和元素数量的情况来选择合适的参数。
测试
public class test {
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter(1000,0.01);
bloomFilter.add("xyz");
boolean xyz = bloomFilter.contains("xyz");
System.out.println("xyz查询结果:"+xyz);
boolean xyzk = bloomFilter.contains("xyzk");
System.out.println("xyz查询结果:"+xyzk);
}
}测试结果:
xyz查询结果:true
xyz查询结果:false?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!