维基百科文章爬虫和聚类【二】:KMeans

维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。
一、说明
????????在我的上一篇文章中,展示了该项目的轮廓,并奠定了其基础。首先,维基百科爬虫对象按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,语料库对象处理完整的文章集,允许方便地访问单个文件,并提供全局数据,例如单个标记的数量。
????????在本文中,创建了一组精选的维基百科文章并应用了 KMeans 聚类。具体来说,您将学习如何将语料库数据准备为 DataFrame。
????????本文的技术背景是Python v3.11和scikit-learn v1.2.2。所有示例也应该适用于较新的库版本。
二、语境
????????本文是有关使用 Python 进行 NLP 的博客系列的一部分。在我之前的文章中,我介绍了如何创建WikipediaReader文章爬虫,它将以文章名称作为输入,然后系统地下载所有链接的文章,直到达到给定的文章总数或深度。爬虫生成文本文件,然后由一个WikipediaCorpus对象(一个在 NLTK 之上自行创建的抽象)进一步处理,该对象可以方便地访问单个语料库文件和语料库统计信息,例如句子、段落和词汇的数量。
????????在本文中,WikipediaReader将从“机器学习”、“航天器”和“Python(编程语言)”文章中下载 100 个子页面,创建包含 270 篇文章的语料库。然后,应用 SciKit Learn 管道来处理每个文档,以进行预处理、标记化和词袋编码。该数据最终被矢量化并输入 KMeans 聚类。
三、设置和数据探索
WikipediaReader和管道的基础WikipediaCorpus以及所有必需的库已在之前的文章中进行了解释。
本文的起点是下载上述三个主题的 100 篇文章文档。
reader = WikipediaReader(dir = "articles")
reader.crawl_pages("Artificial Intelligence", total_number = 100)
reader.process()
reader.reset()
reader.crawl_pages("Spacecraft", total_number = 100)
reader.process()
reader.reset()
reader.crawl_pages("Python (programming language)", total_number = 100)
reader.process()
reader.reset()
语料库对象产生以下统计数据。由于有些文章被多次提及,因此最终的文档数量仅为 270 篇。
root_path = './articles'
corpus = WikipediaPlaintextCorpus(root_path)
print(corpus.describe())
# {'files': 270, 'paras': 13974, 'sents': 47289, 'words': 1146248, 'vocab': 40785, 'max_words': 21058, 'time': 6.870430946350098}
在此语料库中,应用以下 SciKit Learn 管道定义:
root_path = './articles'
pipeline = Pipeline([
('corpus', WikipediaCorpusTransformer(root_path=root_path)),
('categorizer', Categorizer(WikipediaReader())),
('preprocessor', TextPreprocessor(root_path=root_path)),
('tokenizer', TextTokenizer()),
('vectorizer', BagOfWordVectorizer(WikipediaPlaintextCorpus(root_path))),
])

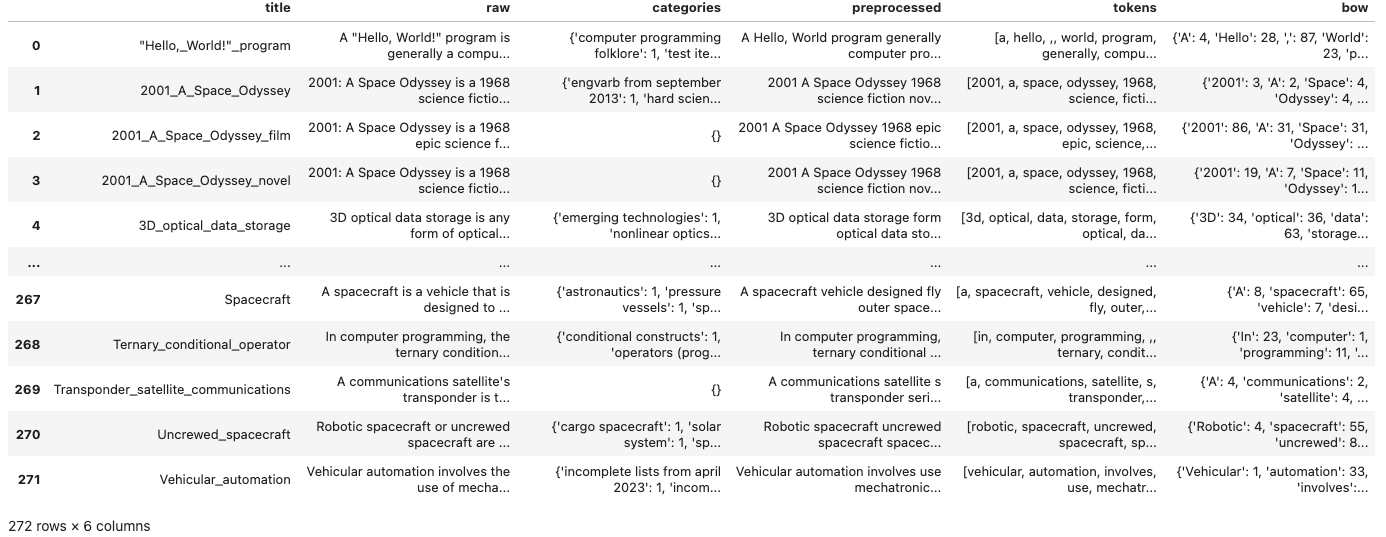
生成的 DataFrame 包含这些列:
- title:维基百科文章标题(保留大写,但用下划线替换空格)
- raw:原始的、未格式化的文本
- 类别:维基百科上为此页面定义的类别名称字典
- 预处理:词形还原和删除停用词的文本
- tokens:标记化的预处理文本
- Bow:对预处理文本进行词袋计数器。
四、使用 SciKit Learn 进行聚类
????????聚类是将多维数据点分离成具有相同属性的连贯集合的过程。存在几种具体算法,它们的方法、检测簇的能力和方法、以及它们对输入值的处理和生成输出值的不同。查看 SciKit Learn聚类算法文档页面,支持以下算法:
- 亲和力传播
- 凝聚聚类
- 桦木
- 数据库扫描
- 特征集聚
- K均值
- 二等分K均值
- 小批量K均值
- 均值平移
- 光学
- 谱聚类
- 谱双聚类
- 光谱共聚类
????????对这些算法的深入解释超出了本文的范围。如果您好奇,请参阅文档页面和其他来源,例如维基百科文章。
????????要开始在 SciKit learn 中使用聚类算法,最好理解并从示例中学习。具体而言,应明确以下几点:
- 如何定义和配置特定的聚类算法?
- 输入数据的预期形状是什么?
- 如何开始聚类生成(迭代次数,保持最佳拟合模型)?
- 算法的输出是什么(二元关联与多类关联、在输入数据中检测到的特征)?
- 哪些指标可用于计算聚类分离的好坏?
选择的示例是KMeans 示例教程,它展示了如何对内置数据集进行聚类。
五、KMeans 聚类示例
????????KMeans算法通过形成具有质心点的沃罗尼单元来检测簇,使得数据点和质心之间的平均距离最小。
????????SciKit Learn 示例适用于新闻组文章的内置数据集。文章加载如下:
# Source: https://scikit-learn.org/stable/auto_examples/text/plot_document_clustering.html#sphx-glr-auto-examples-text-plot-document-clustering-py
import numpy as np
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"talk.religion.misc",
"comp.graphics",
"sci.space",
]
dataset = fetch_20newsgroups(
remove=("headers", "footers", "quotes"),
subset="all",
categories=categories,
shuffle=True,
random_state=42,
)
????????生成的对象dataset提供以下方法来访问语料库及其类别:
print(dataset.DESCR)
# _20newsgroups_dataset:
#
# The 20 newsgroups text dataset
# ------------------------------
#
# The 20 newsgroups dataset comprises around 18000 newsgroups posts on
# 20 topics split in two subsets: one for tr ...
print(dataset.data[:1])
# ["My point is that you set up your views as the only way to believe. Saying \nthat all eveil in this world is caused by atheism is ridiculous and \ncounterproductive to dialogue in this newsgroups. I see in your posts a \nspirit of condemnation of the atheists in this newsgroup bacause they don'\nt believe exactly as you do. If you're here to try to convert the atheists \nhere, you're failing miserably. Who wants to be in position of constantly \ndefending themselves agaist insulting attacks, like you seem to like to do?!\nI'm sorry you're so blind that you didn't get the messgae in the quote, \neveryone else has seemed to."]
print(dataset.filenames)
#['/Users/guenthers/scikit_learn_data/20news_home/20news-bydate-train/alt.atheism/53184'
# '/Users/guenthers/scikit_learn_data/20news_home/20news-bydate-train/comp.graphics/37932'
# '/Users/guenthers/scikit_learn_data/20news_home/20news-bydate-test/comp.graphics/38933' ...
print(dataset.target)
# [0 1 1 ... 2 1 1]
print(dataset.target_names)
# ['alt.atheism', 'comp.graphics', 'sci.space', 'talk.religion.misc']
????????可以看出,数据集只是原始文本表示,类别名称是存储在列表中的字符串。文章和类别之间的关联表示为代表其列表中的类别的单个数字。例如,上面示例中的第一篇文章列出了0其类别,这意味着dataset.target_names[0]导致alt.atheism.
????????该数据使用内置矢量化器进行矢量化。该示例使用 TfIdf。
# https://scikit-learn.org/stable/auto_examples/text/plot_document_clustering.html#sphx-glr-auto-examples-text-plot-document-clustering-py
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_df=0.5,
min_df=5,
stop_words="english",
)
t0 = time()
X_tfidf = vectorizer.fit_transform(dataset.data)
聚类算法由以下代码片段定义:
# https://scikit-learn.org/stable/auto_examples/text/plot_document_clustering.html#sphx-glr-auto-examples-text-plot-document-clustering-py
kmeans = KMeans(
n_clusters=true_k,
max_iter=100,
n_init=5,
)
????????为了计算特定的聚类模型、其指标(同质性、完整性、v-measure)及其训练时间,使用以下方法:
# Source: https://scikit-learn.org/stable/auto_examples/text/plot_document_clustering.html#sphx-glr-auto-examples-text-plot-document-clustering-py
def fit_and_evaluate(km, X, name=None, n_runs=5):
name = km.__class__.__name__ if name is None else name
train_times = []
scores = defaultdict(list)
for seed in range(n_runs):
km.set_params(random_state=seed)
t0 = time()
km.fit(X)
train_times.append(time() - t0)
scores["Homogeneity"].append(metrics.homogeneity_score(labels, km.labels_))
scores["Completeness"].append(metrics.completeness_score(labels, km.labels_))
scores["V-measure"].append(metrics.v_measure_score(labels, km.labels_))
scores["Adjusted Rand-Index"].append(
metrics.adjusted_rand_score(labels, km.labels_)
)
scores["Silhouette Coefficient"].append(
metrics.silhouette_score(X, km.labels_, sample_size=2000)
)
train_times = np.asarray(train_times)
fit_and_evaluate(kmeans, X_tfidf, name="KMeans\non tf-idf vectors")
????????这是很多代码,让我们稍微分离一下观察结果。此方法使用不同的随机种子值重复启动 KMeans 集群。它设置训练的开始时间,调用.fit(X)创建集群的方法,然后计算不同的指标分数。每个分数将预期标签集与聚类算法生成的标签进行比较。最后,训练时间和指标作为字典返回给调用者。
????????现在所有提出的问题都可以得到解答。
- 如何定义和配置特定的聚类算法?=> 该算法表示为一个 Python 类,其中包含一组特定于该算法的预定义和可自定义参数。
- 输入数据的预期形状是什么?=> 形状??为 的矩阵
number_of_samples x data_vector,其中data_vector是数值数据,并且所有样本需要具有相同的长度。 - 如何开始聚类生成(迭代次数,保持最佳拟合模型)?
.fit()=> 通过调用Python 对象并提供输入数据来开始生成簇。此方法返回一个表示具体聚类模式的对象。 - 算法的输出是什么(二元关联与多类关联、在输入数据中检测到的特征)?=> 聚类方案由将样本与索引号相关联的列表组成。索引号代表一个簇。
- 哪些指标可用于计算聚类分离的好坏?指标是特定于集群算法的,它们需要计算一组预期的集群。
有了这些知识,让我们尝试一下使用 KMeans 的简单尝试。
六、朴素 K 均值
????????首先,维基百科文章需要转换为向量表示。为此,我们将使用创建的词袋,它是一个字典数据结构,其中索引是一个单词,值是该单词出现的次数。该字典将使用内置的DictVectorizer.
from sklearn.feature_extraction import DictVectorizer
vectorizer = DictVectorizer(sparse=False)
x_train = vectorizer.fit_transform(X['bow'].to_numpy())
????????然后,我们创建 KMains 对象并定义其属性(8 个集群,随机状态设置为 0)。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=8, random_state=0)
????????该对象根据输入数据进行训练。
kmeans.fit(x_train)
????????然后可以检查生成的簇。
print(kmeans.labels_.shape)
#(272,)
#(272,)
print(kmeans.labels_)
#[0 0 5 3 6 6 3 0 0 0 0 0 0 3 0 0 0 6 0 3 6 0 5 0 1 6 0 3 6 0 0 0 6 6 0 6 0
# 6 3 0 0 0 3 6 6 0 3 3 0 0 0 3 0 1 5 3 0 0 0 0 6 0 0 5 6 3 5 1 6 5 0 0 0 0
# 0 6 3 0 0 6 0 0 3 3 3 0 6 0 0 0 0 0 6 6 6 6 4 6 5 3 3 6 3 0 1 3 0 0 3 0 6
# 0 0 0 3 5 6 6 4 0 0 0 1 0 6 6 3 6 6 1 0 0 1 6 3 0 6 1 6 6 0 6 0 3 0 6 0 0
# 0 3 1 0 0 6 0 6 6 1 6 6 3 0 0 0 6 0 0 6 0 6 0 6 0 0 0 3 0 0 0 1 0 6 6 6 0
# 1 0 0 3 6 0 1 5 0 0 0 0 3 0 0 5 0 3 6 0 2 6 0 2 0 6 3 3 6 0 0 7 5 0 0 1 3
# 1 6 3 6 0 0 6 1 6 6 0 0 0 0 6 6 0 0 0 6 6 1 5 1 6 1 4 0 0 6 2 3 6 1 3 7 6
# 4 3 3 0 1 3 6 6 6 6 0?
七、聚类解释和绘图
????????只需查看标签向量,似乎许多文章都与第一个集群相关联。让我们想象一下具体的关联。
显示文档与集群关联的顺序的条形图:
import matplotlib.pyplot as plt
plt.ylabel('Clusters')
plt.xlabel('Document ID')
plt.plot(kmeans.labels_, 'o')

以及显示每个簇的文档绝对计数的直方图:
plt.hist(x=kmeans.labels_, bins=8, density=False)
plt.grid(True)
plt.show()

好的,但是簇 0 具体是关于什么的呢?我们先看一下文章名称。
def get_cluster_articles(c_id, lables):
return [X['title'][i] for i,l in enumerate(lables) if l == c_id]
print(get_cluster_articles(0, kmeans.labels_))
# '"Hello,_World!"_program', '2001_A_Space_Odyssey', 'ABC_programming_language', 'ACM_Computing_Classification_System', 'ADMB', 'AIVA', 'AIXI', 'AI_accelerator', 'AI_boom', 'AI_capability_control', 'AI_effect', 'AI_takeover', 'ALGOL_60', 'ANSI_C', 'Abaqus', 'Abstract_and_concrete', 'Academic_Free_License', 'Academic_conference', 'Acoustic_location', 'Activation_function', 'Adam_Tooze', 'Adaptable_robotics', 'Advanced_Simulation_Library', 'Aeronautics', 'Agent_architecture', 'Agricultural_robot', 'Ai', ... 'Earth_observation_satellite', 'Eclipsed_conformation', 'European_Union_Space_Programme', 'Expendable_launch_system', 'Fédération_Aéronautique_Internationale', "Gagarin's_Start", 'Geocentric_orbit', 'Geosynchronous_orbit', 'Ground_segment', 'Ground_station', 'Guidance,_navigation,_and_control', 'Inter-satellite_service', 'Intergalactic_travel', 'Orbital_inclination', 'Transponder_satellite_communications']
此外,让我们使用同名库创建一个Wordcloud 。
from wordcloud import WordCloud
def wordcloud_for_cluster(c_id, lables):
text = ' '.join([X['preprocessed'][i] for i,l in enumerate(lables) if l == c_id ])
wordcloud = WordCloud(max_font_size=50, max_words=20).generate(text)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
wordcloud_for_cluster(0, kmeans.labels_)

????????嗯,几篇关于人工智能与航天器混合的文章?虽然我第一次尝试使用 KMeans 时对一个聚类的“抽查”只是经验数据的印象,但所实现的聚类效果并不令人满意。没有预期的簇分离,没有预期的标签是理所当然的。
????????那么如何在人工智能和航天器文章更加分离的意义上改善这种聚类呢?这将是下一篇文章的任务。
八、项目学习
????????在项目期间,由于不熟悉所涉及的不同库,我做出了一些错误的假设和简单的编程错误。本节简要反映了这些经验教训,希望其他人可以避免它们:
- SciKit learn 使用传递给它的完整矩阵。使用 Pandas DataFrame 时,请确保仅转发那些包含数字数据的列。
- SciKit 学习算法仅适用于数字数据。您不能传递预处理的、标记化的文本,也不能传递表示单词出现或频率的字典对象。
- 决定从头开始推出自己的算法或使用库提供的算法。一方面,从头开始编程很有教育意义,另一方面,如果您使用错误的假设,则会令人沮丧。对于文本矢量化,所有库都提供了您可以使用的简单分词器和矢量化器。
九、结论
????????本文展示了如何将 KMeans 聚类应用于维基百科的一组文档。起点是创建一个语料库,这是来自维基百科的关于三个不同主题的纯文本文章列表。这些文章由 SciKit Learn 管道使用,以对文章进行预处理、标记化和词袋编码。为了实际理解聚类,您看到了 KMeans 示例的解释,它回答了有关聚类算法设置和配置、输入数据、如何执行聚类以及输出数据的问题。本文的最后部分使用 KMeans 对词袋进行向量化。唉,这些集群似乎没有足够的区别,例如将人工智能和宇宙飞船归为同一类别。下一篇文章将研究如何改进聚类。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!