慢SQL减少回表手段
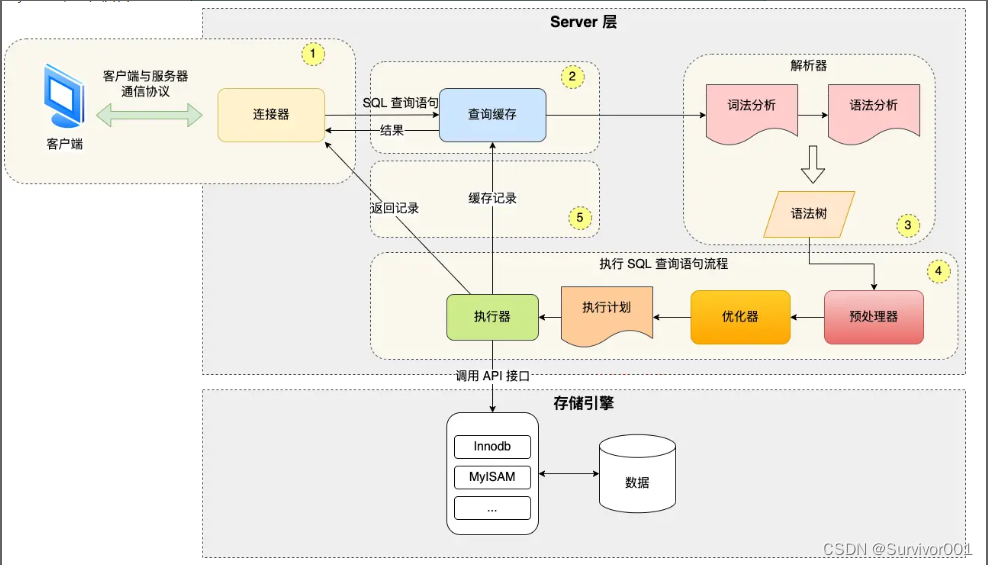
Mysql数据查询无疑就是IO过程,慢SQL的优化本质上其实就是一种减少IO的优化过程,首先了解一下Mysql架构:

- 客户端连接器: 客户端连接数据库服务的驱动,支持多种开发语言
- 连接池: 负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接
- 系统管理和控制工具: 提供备份恢复,安全管理等功能
- SQL接口: 接收客户端发送的各种SQL请求,并返回结果
- 解析器: 对SQL语句进行词法解析,语法解析和对象权限检查,并生成语法树
- 查询优化器: 对查询进行改写,通过对不同执行路径的cost对比,生成最优的执行计划。
- 缓存: 查询缓存,主要缓存查询的结果,为重复的查询节省执行的时间(默认关闭,8.0废弃)
- 存储引擎: 存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互。MySQL存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异 。
- 系统文件: 存储数据和日志的物理文件
Mysql查询链路
索引优化本质上就是对执行计划干预,通过建立和调整合适的索引策略,来使得执行器能更优、更高效的执行SQL。
Explain返回语句中使用的每个表的一行信息?。它按照 MySQL 在处理语句时读取表的顺序列出了输出中的表。MySQL 使用嵌套循环连接方法来解析所有连接。这意味着MySQL从第一个表中读取一行,然后在第二个表、第三个表等中找到匹配的行。当所有表都处理完毕后,MySQL 输出选定的列并回溯表列表,直到找到有更多匹配行的表。从此表中读取下一行,并继续处理下一个表。
可以看得出来此过程需要频繁回表操作,如果不能借助有效的优化手段,就可能导致严重的效能问题。【Mysql】 InnoDB引擎深入- 二级索引、联合索引、回表、索引覆盖_二级索引叶子节点-CSDN博客
一般减少回表消耗的本质就是减少IO开销,一般常用手段为:
1、索引覆盖
2、索引下推
索引覆盖
我们知道对于二级索引来说,索引结构中只会存储索引列信息+主键ID,如果需要额外的资讯信息,需要通过主键ID到聚簇索引结构中检索,这样的过程叫做回表,那索引覆盖的本质就是期望可以一次性通过二级索引拿到需要栏位资讯,较少回表操作。
做法很简单,建立二级索引,索引栏位覆盖所需要查询的栏位即可。
例如:
当前索引mkp_wo_info_b001(tenantsid)

添加plan_no到索引中
mkp_wo_info_b001(tenantsid,plan_no)

?需要注意的是索引覆盖是为了减少回表次数,而二级索引是用于提高检索效率,需要遵循最左原则,如果在已存在的二级索引上进行索引覆盖操作,注意不要影响二级索引的正常使用,建议覆盖栏位滞后。
索引下推(ICP)
索引条件下推(ICP)是针对 MySQL 使用索引从表中检索行的情况的优化。如果没有 ICP,存储引擎将遍历索引来定位基表中的行,并将它们返回到 MySQL 服务器,由 MySQL 服务器评估这些WHERE行的条件。启用 ICP 后,如果?WHERE可以仅使用索引中的列来评估部分条件,则 MySQL 服务器会将这部分条件推WHERE送到存储引擎。然后,存储引擎通过使用索引条目来评估推送的索引条件,并且仅当满足该条件时才从表中读取行。ICP可以减少存储引擎必须访问基表的次数以及MySQL服务器必须访问存储引擎的次数。
说白了索引下推的目的就是将where条件的过滤从Mysql服务层下推到存储引擎进行处理,较少返回的数据量,也就意味着减少后续需要回表的次数。
需要注意的是对于InnoDB表来说,ICP仅用于二级索引。ICP的目标是减少全行读取的次数,从而减少I/O操作。对于?InnoDB聚集索引,完整的记录已经读入缓冲区InnoDB?。在这种情况下使用 ICP 不会减少 I/O
举例:
现在有索引mkp_wo_info_b001 (`tenantsid`, `wo_no`, `eoc_company_id`)
tenantsid?bigint(20)、wo_no varchar(50)、eoc_company_id varchar(50)

测试:

key_len计算:8(bigint)+50*3(utf-8)+1(len)+1(null)+50*3+1+1 = 312
可以看出来上面使用到的条件:tenantsid=297471165657664 and wo_no = 'Y512-202110260001' and eoc_company_id = '1' 是完全使用到了索引,这也是理论之内的。
如果我们去掉wo_no条件,变成tenantsid=297471165657664 ?and eoc_company_id = '1' , 根据最左原则要求,这里只能使用到tenantsid,索引长度为8:

?但是我们发现在Extra中发现了?Using index condition,这个就代表了使用到了索引下推。
解释一下:
不使用索引条件下推时索引扫描如何进行:
1、通过tenantsid读取下一行,然后通过查询到的索引数据进行回表获取资讯
2、WHERE测试适用于此表的条件?部分,也就是在Server层进行eoc_company_id条件的过滤
使用索引条件下推时索引扫描如何进行:
1、通过tenantsid读取下一行
2、检查过where适用于该表的条件?部分,并且可以仅使用索引列进行检查。如果不满足条件,则继续查找下一行的索引元组。也就是说在索引查询时(存储引擎检索时)就已经将where条件中eoc_company_id条件下沉进行过滤操作,此时获取到的数据范围会更小。
3、如果满足条件,则使用索引元组定位并读取全表行
WHERE?测试适用于此表的条件?的其余部分。根据测试结果接受或拒绝该行。
当使用索引条件下推时,输出显示?Using index condition在 列中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!