Redis中字符串表示是如何设计与实现的?
Redis中字符串表示是如何设计与实现的(SDS)?
引言
在redis中,其键值对中,值可以是数字、字符串或者集合等;但其键key却始终是 字符串 类型。
那么,redis中的字符串底层到底是如何设计的呢?为什么redis要这样设计呢?
本篇文章来详细介绍一下,带你一起了解和学习redis中字符串的设计与实现,不惧面试。
简单动态字符串
Sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示,它被用在几乎所有的 Redis 模块中。
SDS是Redis中用于表示字符串值的数据结构,它是一种动态字符串实现。与C语言中的字符串相比,SDS具有更多的特性和功能。SDS的设计目标是在保持高性能的同时,提供较为灵活的字符串操作接口。
底层数据结构
SDS的内部结构如下所示:
struct sdshdr {
int len; // 字符串当前长度
int free; // 字符串剩余空间
char buf[]; // 字符串数据
};
SDS的实际存储空间大小为len + free + 1,其中len表示字符串的当前长度,free表示字符串的剩余空间,buf是一个字节数组,用于存储字符串数据。SDS的结构允许字符串长度的动态增长和缩减,且不需要进行内存的重新分配。
为什么不用char *
将 sds 代替 C 默认的 char* 类型
因为 char* 类型的功能单一,抽象层次低,并且不能高效地支持一些 Redis 常用的操作(比 如追加操作和长度计算操作),所以在 Redis 程序内部,绝大部分情况下都会使用 sds 而不是 char* 来表示字符串。
同时:在 Redis 中,客户端传入服务器的协议内容、aof 缓 存、返回给客户端的回复,等等,这些重要的内容都是由都是由 sds 类型来保存的。
在 C 语言中,字符串可以用一个 \0 结尾的 char 数组来表示。 比如说,hello world 在 C 语言中就可以表示为 “hello world\0” 。这种简单的字符串表示在大多数情况下都能满足要求,但是,它并不能高效地支持长度计算和 追加(append)这两种操作:
- 每次计算字符串长度(strlen(s))的复杂度为 θ(N) 。
- 对字符串进行 N 次追加,必定需要对字符串进行 N 次内存重分配(realloc)。
在 Redis 内部,字符串的追加和长度计算并不少见,而 APPEND 和 STRLEN 更是这两种操 作在 Redis 命令中的直接映射,这两个简单的操作不应该成为性能的瓶颈。
另外,Redis 除了处理 C 字符串之外,还需要处理单纯的字节数组,以及服务器协议等内容, 所以为了方便起见,Redis 的字符串表示还应该是二进制安全的:程序不应对字符串里面保存 的数据做任何假设,数据可以是以 \0 结尾的 C 字符串,也可以是单纯的字节数组,或者其他 格式的数据。
考虑到这两个原因,Redis 使用 sds 类型替换了 C 语言的默认字符串表示:sds 既可以高效地 实现追加和长度计算,并且它还是二进制安全的。
举个🌰
- 作为例子,以下是新创建的,同样保存 hello world 字符串的 sdshdr 结构:
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0"; // buf 的实际长度为 len + 1
};
- 通过 len 属性,sdshdr 可以实现复杂度为 θ(1) 的长度计算操作。
- 另一方面,通过对 buf 分配一些额外的空间,并使用 free 记录未使用空间的大小,sdshdr 可
以让执行追加操作所需的内存重分配次数大大减少。 当然,sds 也对操作的正确实现提出了要求——所有处理 sdshdr 的函数,都必须正确地更新len 和 free 属性,否则就会造成 bug
如何优化append操作?
好的,以下是sds的源码分析,主要涉及预分配机制和连续增长策略的实现细节:
一、预分配机制
在sds中,预分配机制是通过sdsMakeRoomFor函数实现的。当执行append操作时,该函数会根据需要增加的空间大小计算出预分配的大小,并重新分配内存。预分配的大小通常会比实际需要的大小要大一些,以确保足够的空间进行后续的追加操作。
在源码中,sdsMakeRoomFor函数的实现如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh;
size_t free = sdsavail(s);
size_t len = sdslen(s);
char *newptr;
size_t newlen = len + addlen;
if (free < addlen) {
newptr = zmalloc(newlen + free); // 预分配额外的空间
memcpy(newptr, s, len); // 将原有内容复制到新空间中
zfree(s); // 释放原有内存空间
sh = (struct sdshdr *) newptr;
sh->free = free; // 更新未使用空间大小
} else {
sh = sdshdr(s);
}
sh->len = newlen; // 更新字符串长度
return s; // 返回新的sds字符串指针
}
在函数中,首先计算出当前sds字符串的未使用空间free和字符串长度len。然后,根据需要增加的空间大小addlen计算出新的字符串长度newlen。如果当前未使用空间不足以容纳增加的空间,则分配额外的内存空间,并将原有内容复制到新空间中。最后,更新sds结构体中的相关字段,并返回新的sds字符串指针。
二、连续增长策略
在sds中,连续增长策略是通过sdsIncrLen函数实现的。该函数会在原有字符串的基础上追加新的内容,并更新sds结构体中的相关字段。如果原有字符串的缓冲区不足以容纳新的内容,该函数会重新分配更大的内存空间,并将原有内容复制到新空间中。这样可以确保追加操作不会频繁地触发内存重分配,从而提高性能。
在源码中,sdsIncrLen函数的实现如下:
sds sdsIncrLen(sds s, int len) {
struct sdshdr *sh = sdshdr(s);
if ((sh->free += len) < sdsavail(s)) { // 如果未使用空间足够容纳增加的空间
sh->len += len; // 更新字符串长度
} else { // 如果未使用空间不足,重新分配更大的内存空间
char *newptr;
size_t newlen = sh->len + len; // 计算新的字符串长度
newptr = zmalloc(newlen + sh->free); // 预分配额外的空间
memcpy(newptr, s, sh->len); // 将原有内容复制到新空间中
zfree(s); // 释放原有内存空间
sh = (struct sdshdr *) newptr;
sh->free = sh->free; // 更新未使用空间大小
}
return s; // 返回新的sds字符串指针
}
在函数中,首先检查未使用空间是否足够容纳增加的空间。如果足够,则直接更新字符串长度;否则,重新分配更大的内存空间,并将原有内容复制到新空间中。最后,返回新的sds字符串指针。
总结来说,sds通过预分配机制和连续增长策略等优化手段,实现了高效的字符串操作。在源码中,这些优化策略体现在sdsMakeRoomFor和sdsIncrLen等函数中,通过合理的内存管理和数据结构的设计,提高了Redis中字符串操作的性能。
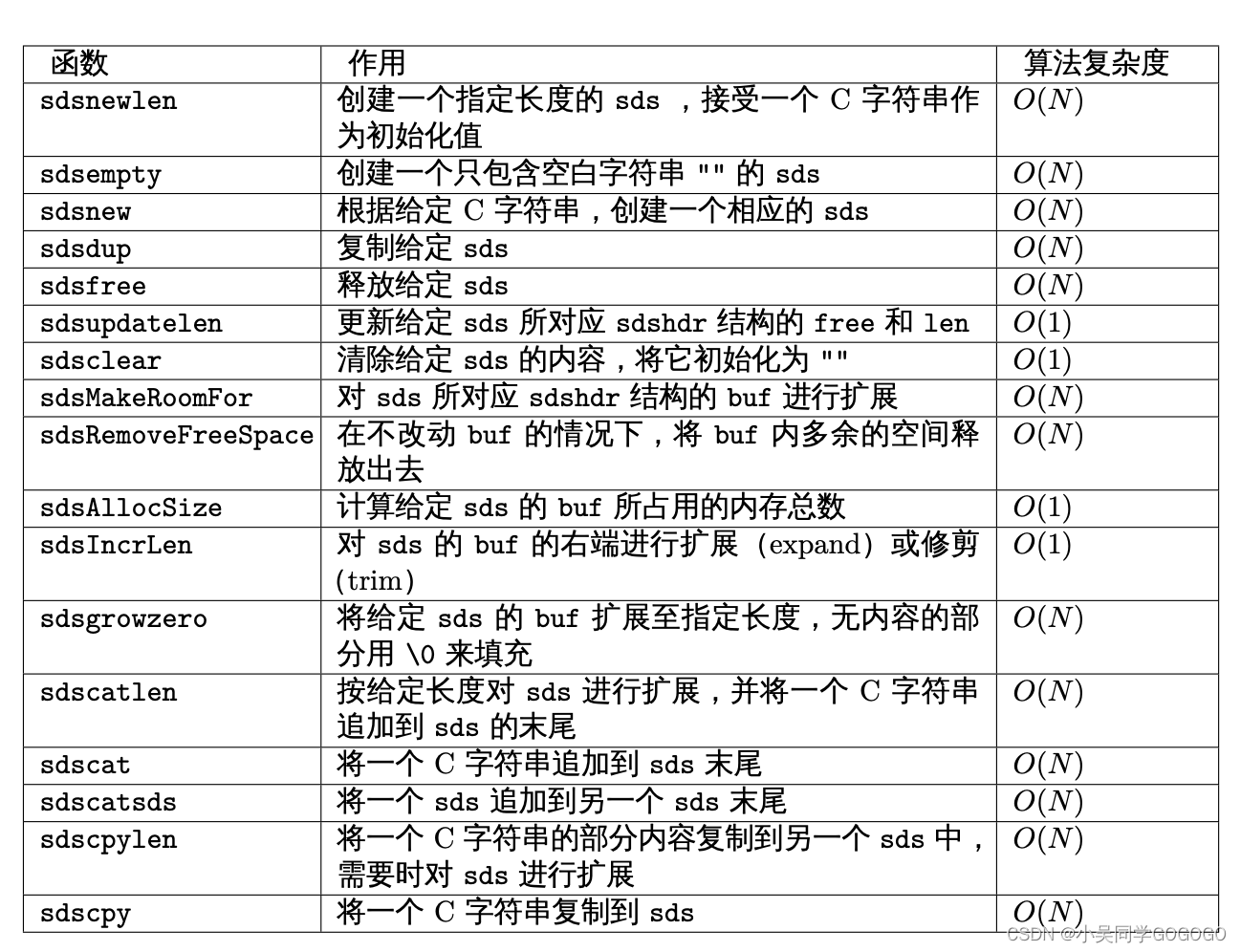
总结
- Redis 的字符串表示为 sds ,而不是 C 字符串(以 \0 结尾的 char*)。
- 对比 C 字符串,sds 有以下特性:
- 可以高效地执行长度计算(strlen);
- 可以高效地执行追加操作(append); – 二进制安全;
- sds 会为追加操作进行优化:加快追加操作的速度,并降低内存分配的次数,代价是多占 用了一些内存,而且这些内存不会被主动释放。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!