【linux】awk的基本使用
awk是shell中一个强大的文本处理工具,被用于处理文本和数据
当你心中默念想要使用类似于
处理某一行,处理某一列 的文本
的功能时,就是awk登场的时候了
举个简单的例子是,当我们想知道自己的所有网卡的名字时,可以用ifconfig查看
enp3s0f0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 98:fa:9b:fb:15:f7 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 22442 bytes 2200764 (2.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 22442 bytes 2200764 (2.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlp1s0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.40.162 netmask 255.255.255.0 broadcast 192.168.40.255
inet6 2405:1201:1203:b300::6fe:659a prefixlen 128 scopeid 0x0<global>
inet6 fe80::d3f0:6ff7:5950:bbfe prefixlen 64 scopeid 0x20<link>
inet6 2405:1201:1203:b300:e4a6:88ce:3460:f061 prefixlen 64 scopeid 0x0<global>
ether 28:7f:cf:53:02:96 txqueuelen 1000 (Ethernet)
RX packets 2431832 bytes 2540254972 (2.3 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1357755 bytes 280044371 (267.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0我们会看到类似于上述信息一样密密麻麻的文字,当然我们可以手动CTRL C CTRL V 把网卡名称拿出来,但是如果希望有一种写法可以不用手动去查看获取的话,可以试试使用awk
ifconfig | awk -F: '/^[a-z0-9]*:{1}/ {print $1 }'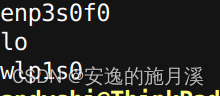
基本用法
打印文件的每一行,其中filename是文件名(或者可访问路径)
重要的是引号之内的写法
awk '{print}' filename
print如果没有加任何参数的话就是打印一整行的意思,如果加上 $数字 的话,就是打印第几列
一般来说用空格分隔开
比如打印每一行的第一列
awk '{print $1}' filename
打印每一行的第二列
awk '{print $2}' filename
并且 列 是可以多选的
awk '{print $3, $4}' filename
使用条件语句进行判断,只打印出正数,比如我们想要从账单中取出所有收入的部分
awk '$1 > 0 {print $1}' filename打印的时候顺便带上行号
awk '{print NR, $0}' filename
可以同时处理多个文件(上面有一个例子是可以处理多个列)
会按照file1 然后 file2 的顺序输出
awk '{print}' file1 file2
还有最常用的正则表达式处理数据
awk '/pattern/ {print}' filename
以某种字符作为分割符,因为默认是空格作为分割的条件
但是不同的情况下希望使用不同的分割符
比如192.168.xxx.xxx的时候,在局域网中前两部分是一样的,所以如果想用小数点作为分割方式的话,直接使用 -F 然后紧跟着你要指定的分隔符就行了
除此之外还可以用 / 分割日期, : 分割时间等
echo 192.168.11.123 | awk -F. '{print $3,$4}'
还可以使用自定义变量进行更灵活地数据处理(文本数据)
awk -v var=100 '{if ($1 > var) print $1}' filename
以上就是最基本的awk的几种使用情况
使用awk的时候通常对象要有以下特点才最容易使用
1 行之间有特定的规律,虽然是文本结构,但是具有表的特点,比如第一列是名字,第二列是ip,并且每行或者每n行代表一个记录
2 具有同一的分隔符的时候
这两种情形的文本在实际的linux系统中常见于各种config文件和log中
可以说用处十分广?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!