Redis持久化
Redis是内存数据库,它将所有数据存储在内存。其优点是可以高速的读写,但是缺点是如果机器一旦宕机,数据也会消失。为了数据安全,Redis需要将内存的数据持久化到磁盘上。持久化方式有RDB持久化和AOF持久化。
RDB持久化
RDB持久化方案是指按照一定的时间间隔,对数据集生成一个时间点的快照,RDB持久化生成的RDB文件是一个经过压缩的二进制文件。可用于Redis的数据备份、迁移和恢复。
RDB持久化可以手动触发或者自动触发。
- 手动触发:通过save或者bgsave可以执行生成快照也就是RDB文件
- 自动触发主要包含以下几种情况
- redis.conf中配置的 save m n即在m秒内有n次修改
- 主从复制时,从节点从主节点进行全量复制时,会触发bgsave,生成快照文件发给从节点
- 在执行shutdown命令时,如果没有配置aof持久化,会执行bgsave
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成。
SAVE与BGSAVE
整体上来讲,SAVE是同步执行的,调用SAVE命令后会直接触发数据集的持久化,因为Redis是单线程模型,所以在持久化期间会阻塞线程,无法对外提供服务。BGSAVE是后台异步执行的,在持久化之前首先会fork出一个子进程,后续的持久化操作是在子进程中完成,与此同时主进程可以继续对外提供服务。
SAVE命令
执行SAVE命令时会调用rdbSave函数。
/* Save the DB on disk. Return C_ERR on error, C_OK on success. */
int rdbSave(int req, char *filename, rdbSaveInfo *rsi, int rdbflags) {
char tmpfile[256]; // 创建临时文件
char cwd[MAXPATHLEN]; /* Current working dir path for error messages. */
startSaving(RDBFLAGS_NONE);
snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid());
if (rdbSaveInternal(req,tmpfile,rsi,rdbflags) != C_OK) { // 内存数据写入临时文件
stopSaving(0);
return C_ERR;
}
/* Use RENAME to make sure the DB file is changed atomically only
* if the generate DB file is ok. */
if (rename(tmpfile,filename) == -1) {
char *str_err = strerror(errno);
char *cwdp = getcwd(cwd,MAXPATHLEN);
serverLog(LL_WARNING,
"Error moving temp DB file %s on the final "
"destination %s (in server root dir %s): %s",
tmpfile,
filename,
cwdp ? cwdp : "unknown",
str_err);
unlink(tmpfile);
stopSaving(0);
return C_ERR;
}
if (fsyncFileDir(filename) != 0) { // 持久化到磁盘
serverLog(LL_WARNING,
"Failed to fsync directory while saving DB: %s", strerror(errno));
stopSaving(0);
return C_ERR;
}
serverLog(LL_NOTICE,"DB saved on disk");
server.dirty = 0; // 更新状态信息
server.lastsave = time(NULL);
server.lastbgsave_status = C_OK;
stopSaving(1);
return C_OK;
}
工作流程主要包括:
3. 创建临时文件
4. 内存数据写入临时文件
5. 持久化到磁盘
6. 重命名RDB文件
7. 更新持久化状态信息
BGSAVE命令
执行BGSAVE命令时会调用rdbSaveBackground函数。
int rdbSaveBackground(int req, char *filename, rdbSaveInfo *rsi, int rdbflags) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.stat_rdb_saves++;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
retval = rdbSave(req, filename,rsi,rdbflags);
if (retval == C_OK) {
sendChildCowInfo(CHILD_INFO_TYPE_RDB_COW_SIZE, "RDB");
}
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent */
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}
rdbSaveBackgroud与rdbSave相比,主要是在开始持久化之前先fork出了子线程。由子线程执行持久化操作,主线程持续对外提供服务。
自动间隔保存
redisServer中有几个关于RDB持久化相关的参数。
struct redisServer {
/* 省略其他字段 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化后修改key的次数 */
struct saveparam *saveparams; /* Save points array for RDB,
* 对应配置文件多个save参数 */
int saveparamslen; /* Number of saving points,
* save参数的数量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化时间*/
/* 省略其他字段 */
}
其中saveparam对应着redis.conf下的save规则
/* 对应redis.conf中的save参数 */
struct saveparam {
time_t seconds; /* 统计时间范围 */
int changes; /* 数据修改次数 */
};
- dirty: 上次持久化后修改key的次数
- lastsave: 上次持久化时间
- saveparam/seconds: 为统计时间(单位:秒)
- saveparam/changes: 为在统计时间内发生写入的次数
save参数可以设置为多组saveparam,redis服务器会周期性检查键值变更情况,满足其中任意一组saveparam时,会触发持久化操作。
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(SLAVE_REQ_NONE,server.rdb_filename,rsiptr,RDBFLAGS_NONE);
break;
}
}
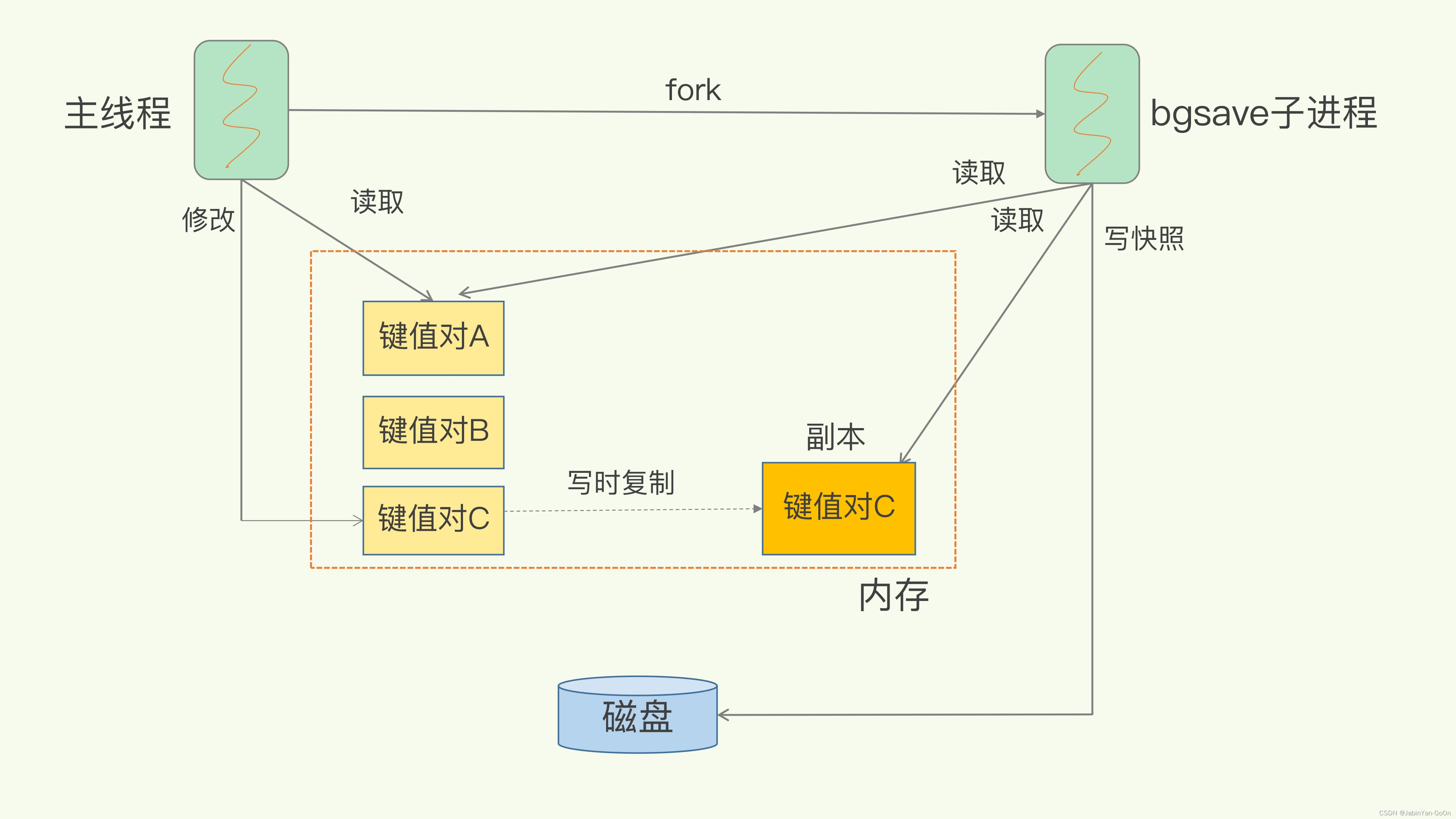
写时复制
数据集在进行RDB快照时,服务仍对外提供服务,期间如果出现了写操作,就需要考虑内存数据集和RDB文件数据一致性的问题。
RDB在解决数据一致性的问题时,主要是思路是写时复制。
fork出的子进程在进行数据持久化时,如果主进程接收到数据的写请求时,在对客户端进行响应的同时还会将新写入的数据以副本的方式存储到另一个新的内存区域,待快照操作结束之后,再将新的副本数据同步到RDB快照文件中。
优缺点
优点
- RDB是快照文件,适用于数据备份、迁移、灾后恢复等场景
- 因为RDB是二进制文件,Redis在启动时加载RDB文件速度快于AOF文件
- RDB支持fork子进程进行持久化,主进程可以不间断提供服务,可以最大程度的提升Redis性能
缺点
- RDB数据快照的实时性不够,无法做到秒级的持久化,服务宕机时会丢失更多的数据
- fork子进程是一个重量级操作,操作成本较高,如果内存数据很大时,fork子进程时会出现服务的波动,AOF也会fork子进程,但是无需像RDB一样频繁
AOF持久化
AOF(Append Only File)是通过保存Redis服务器所执行的写命令来记录数据库的状态。
AOF的实现过程

命令追加(append)
struct redisServer {
// ...
// AOF缓冲区
sds aof_buf;
// ...
};
redisServer结构中有一个sds结构的aof_buf属性。当服务器执行完一个写命令之后,会议协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区末尾。
/* Write the given command to the aof file.
17. dictid - dictionary id the command should be applied to,
18. this is used in order to decide if a `select` command
19. should also be written to the aof. Value of -1 means
20. to avoid writing `select` command in any case.
21. argv - The command to write to the aof.
22. argc - Number of values in argv
*/
void feedAppendOnlyFile(int dictid, robj **argv, int argc) {
sds buf = sdsempty();
serverAssert(dictid == -1 || (dictid >= 0 && dictid < server.dbnum));
/* Feed timestamp if needed */
if (server.aof_timestamp_enabled) {
sds ts = genAofTimestampAnnotationIfNeeded(0);
if (ts != NULL) {
buf = sdscatsds(buf, ts);
sdsfree(ts);
}
}
/* The DB this command was targeting is not the same as the last command
* we appended. To issue a SELECT command is needed. */
if (dictid != -1 && dictid != server.aof_selected_db) {
char seldb[64];
snprintf(seldb,sizeof(seldb),"%d",dictid);
buf = sdscatprintf(buf,"*2\r\n$6\r\nSELECT\r\n$%lu\r\n%s\r\n",
(unsigned long)strlen(seldb),seldb);
server.aof_selected_db = dictid;
}
/* All commands should be propagated the same way in AOF as in replication.
* No need for AOF-specific translation. */
buf = catAppendOnlyGenericCommand(buf,argc,argv);
/* Append to the AOF buffer. This will be flushed on disk just before
* of re-entering the event loop, so before the client will get a
* positive reply about the operation performed. */
if (server.aof_state == AOF_ON ||
(server.aof_state == AOF_WAIT_REWRITE && server.child_type == CHILD_TYPE_AOF))
{
server.aof_buf = sdscatlen(server.aof_buf, buf, sdslen(buf));
}
sdsfree(buf);
}
sds catAppendOnlyGenericCommand(sds dst, int argc, robj **argv) {
char buf[32];
int len, j;
robj *o;
buf[0] = '*';
len = 1+ll2string(buf+1,sizeof(buf)-1,argc);
buf[len++] = '\r';
buf[len++] = '\n';
dst = sdscatlen(dst,buf,len);
for (j = 0; j < argc; j++) {
o = getDecodedObject(argv[j]);
buf[0] = '$';
len = 1+ll2string(buf+1,sizeof(buf)-1,sdslen(o->ptr));
buf[len++] = '\r';
buf[len++] = '\n';
dst = sdscatlen(dst,buf,len);
dst = sdscatlen(dst,o->ptr,sdslen(o->ptr));
dst = sdscatlen(dst,"\r\n",2);
decrRefCount(o);
}
return dst;
主要包括以下几个流程
- 初始化buf
- 选择相应的db
- 按照既定协议拼接指令
- 写入到aof_buf
文件写入(write)
每次事件循环过程中,通过时间事件调用serverCron函数进行定时运行。循环结束之前回调flushAppendOnlyFile函数,考虑是否将aof_buf数据写入和同步到AOF文件(磁盘)。
flushAppendOnlyFile流程包括write和fsync两步操作。
通过write操作之后,此时aof_buf数据将会进入page_cache。等待后续的刷盘时机,进行同步操作
/* Write the append only file buffer on disk.
*
* Since we are required to write the AOF before replying to the client,
* and the only way the client socket can get a write is entering when
* the event loop, we accumulate all the AOF writes in a memory
* buffer and write it on disk using this function just before entering
* the event loop again.
*
* About the 'force' argument:
*
* When the fsync policy is set to 'everysec' we may delay the flush if there
* is still an fsync() going on in the background thread, since for instance
* on Linux write(2) will be blocked by the background fsync anyway.
* When this happens we remember that there is some aof buffer to be
* flushed ASAP, and will try to do that in the serverCron() function.
*
* However if force is set to 1 we'll write regardless of the background
* fsync. */
#define AOF_WRITE_LOG_ERROR_RATE 30 /* Seconds between errors logging. */
void flushAppendOnlyFile(int force) {
ssize_t nwritten;
int sync_in_progress = 0;
mstime_t latency;
// 判定fsync相关 略
nwritten = aofWrite(server.aof_fd,server.aof_buf,sdslen(server.aof_buf));
// 判定fsync相关 略
}
/* This is a wrapper to the write syscall in order to retry on short writes
* or if the syscall gets interrupted. It could look strange that we retry
* on short writes given that we are writing to a block device: normally if
* the first call is short, there is a end-of-space condition, so the next
* is likely to fail. However apparently in modern systems this is no longer
* true, and in general it looks just more resilient to retry the write. If
* there is an actual error condition we'll get it at the next try. */
ssize_t aofWrite(int fd, const char *buf, size_t len) {
ssize_t nwritten = 0, totwritten = 0;
while(len) {
nwritten = write(fd, buf, len);
if (nwritten < 0) {
if (errno == EINTR) continue;
return totwritten ? totwritten : -1;
}
len -= nwritten;
buf += nwritten;
totwritten += nwritten;
}
return totwritten;
}
文件同步(fsync)
文件同步才是真正的执行持久化操作,经过fsync后会将page_cache中的数据刷到磁盘中。redis可以通过appendfsync设置不同的刷盘时机。
try_fsync:
/* Don't fsync if no-appendfsync-on-rewrite is set to yes and there are
* children doing I/O in the background. */
if (server.aof_no_fsync_on_rewrite && hasActiveChildProcess())
return;
/* Perform the fsync if needed. */
if (server.aof_fsync == AOF_FSYNC_ALWAYS) {
/* redis_fsync is defined as fdatasync() for Linux in order to avoid
* flushing metadata. */
latencyStartMonitor(latency);
/* Let's try to get this data on the disk. To guarantee data safe when
* the AOF fsync policy is 'always', we should exit if failed to fsync
* AOF (see comment next to the exit(1) after write error above). */
if (redis_fsync(server.aof_fd) == -1) {
serverLog(LL_WARNING,"Can't persist AOF for fsync error when the "
"AOF fsync policy is 'always': %s. Exiting...", strerror(errno));
exit(1);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("aof-fsync-always",latency);
server.aof_last_incr_fsync_offset = server.aof_last_incr_size;
server.aof_last_fsync = server.unixtime;
atomicSet(server.fsynced_reploff_pending, server.master_repl_offset);
} else if (server.aof_fsync == AOF_FSYNC_EVERYSEC &&
server.unixtime > server.aof_last_fsync) {
if (!sync_in_progress) {
aof_background_fsync(server.aof_fd);
server.aof_last_incr_fsync_offset = server.aof_last_incr_size;
}
server.aof_last_fsync = server.unixtime;
}
}
- No:操作系统控制回刷,每个写命令执行完毕后,只是先把日志追加aof_buf和page_cache。由操作系统决定何时将缓冲区内容写回磁盘
- Everysec:每秒写回:每个写命令执行完毕后,先讲日志写到aof_buf和page_cache。每隔一秒会把page_cache的数据写回磁盘
- Always:同步写回:每个写命令执行完后,直接执行fsync进行刷盘
AOF文件重写
随着时间越来越长,AOF文件记录的写指令越来越多,文件也就越来越大。如果不加以控制,会对Redis服务器造成严重的影响。而且AOF文件越大,数据恢复也就越慢。为了解决AOF文件体积膨胀的问题,Redis提供AOF文件重写机制对AOF文件进行瘦身。
AOF重写时机
# Automatic rewrite of the append only file.
# Redis is able to automatically rewrite the log file implicitly calling
# BGREWRITEAOF when the AOF log size grows by the specified percentage.
#
# This is how it works: Redis remembers the size of the AOF file after the
# latest rewrite (if no rewrite has happened since the restart, the size of
# the AOF at startup is used).
#
# This base size is compared to the current size. If the current size is
# bigger than the specified percentage, the rewrite is triggered. Also
# you need to specify a minimal size for the AOF file to be rewritten, this
# is useful to avoid rewriting the AOF file even if the percentage increase
# is reached but it is still pretty small.
#
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
- auto-aof-rewrite-percentage:当前AOF文件大小与上一次重写后AOF文件大小相比,增量达到一定比值
- auto-aof-rewrite-min-size:运行AOF重写文件的最小大小
AOF重写过程
AOF重写过程是由后台进程bgrewriteof来完成的。主线程fork出后台的bgrewriteof子进程,fork会把主进程的内存拷贝一份到bgrewriteof子进程。然后bgrewriteof子进程就可以在不影响主线程的情况下,逐一把拷贝的数据完成操作,记入重写日志。
所以aof在重写时,在fork进程时是会阻塞住主线程的。
AOF重写期间数据一致性保证
在重写过程中,主进程仍可接收写命令,此时fork出的子进程拷贝的数据就是和主进程的数据会出现不一致。Redis通过写时复制和多个缓冲区来解决一致性的问题。
- 写时复制
首先在fork子进程启动AOF重写时,操作系统会把主进程的页表复制一份给子进程,但是并不是物理内存,此时主、子进程共享一块为物理内存区域,通知两个进程都只具有读的权限。当主进程发生写操作时,CPU会进行写保护中断,同时进行物理内存复制,并将权限设置为读写,然后为主子进程更新物理内存映射关系。这个过程称之为写时复制(COW:Copy On Write)。

- 多个缓冲区
重写AOF文件期间,当Redis执行写操作时,它同时将命令写到AOF缓冲区和AOF重写缓冲区。当子进程完成AOF重写操作后,会以信号的形式通知主进程,主进程收到信号后会做两件事儿。 - 将AOF重写缓冲区所有内容追加到新的AOF文件
- 将新的AOF文件进行重命名,以覆盖旧的AOF文件
AOF持久化优缺点
优点
AOF持久化秒级持久化,进程丢失的数据比较少,数据比较完整。
缺点
执行频率高,影响服务性能,写指令数据本本占用空间较大,导致磁盘文件也很大,重启恢复耗时较长。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!