快速改善代码的几个小建议
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
本文举例的代码,仅做案例讨论。影响代码质量最大的因素其实是开发进度,写得不好有时未必是能力不够。
可读性
什么样的代码才是高质量的代码呢?
对于这个问题,每个人都有自己的看法,但我始终坚持认为:高质量的代码必然要简单、易读。
@Test
public void testListSimpleStyle() {
// 有点像匿名类,但本质是重写代码块,在代码块里调用本对象的add()方法
List<Superman> list = new ArrayList<Superman>(){
{
add(new Superman("AAA"));
add(new Superman("BBB"));
add(new Superman("CCC"));
}
};
System.out.println(list);
}这样的代码固然骚,但也只剩下骚了。想要简化变量的初始化,其实有更优雅的写法。
@Test
public void testListSimpleStyle() {
// 利用可变形参的特性直接把多个参数传入,而不需要另外创建数组
List<Superman> list = Arrays.asList(
new Superman("xixi"),
new Superman("haha")
);
System.out.println(list);
}如果你觉得Arrays不好(返回的List不可增删元素),还可以使用Guava:
@Test
public void testListSimpleStyle() {
List<Superman> list = Lists.newArrayList(
new Superman("xixi"),
new Superman("haha")
);
System.out.println(list);
}后两种代码风格显然更具备可读性。很多刚入职场的热血青年,常常会有一个误区:我写的代码,一定要把同事绕晕,让他哭着求我给他解释,这样才能鹤立鸡群。
不好意思,如果你敢这样,大概率会被开除。随着互联网的普及与壮大,现在的软件设计变得愈发复杂,像中国初代程序员求伯君那样一个人写出WPS的时代早就过去了,更多时候我们都是在集体战斗。个人能力固然重要,但终有一天你会发现自己只是一个平凡的程序员,编码能力并没有大幅领先身边的同事,甚至反过来经常被同事教做人。与其写骚代码炫技,不如想想如何把代码写得更简单易懂,让别人正确理解你的意图。
不要使用魔法值
public boolean saveUser() {
// do something...
user.setType(1);
return userService.save(user) > 1;
}上面代码setType(1)中的数字就是魔法值,它既不由参数传入,也不是枚举或常量,而是凭空出现的。看到这个数字1,你会疑惑:1代表什么呢?学生还是教师?亦或是某种状态?真是让人抓狂!
一般来说,应该把type、status等变化有限的数据抽取到枚举或常量中,并赋予有意义的名字,然后在需要的地方引用:
public boolean saveUser() {
// do something...
user.setType(UserTypeEnum.STUDENT.getType);
return userService.save(user) > 1;
}如果只有当前代码用到,而你又懒得抽取枚举或常量,最好用一个变量去接收:
public boolean saveUser() {
// do something...
Integer studentType = 1;
user.setType(studentType);
return userService.save(user) > 1;
}变量声明后立即使用
很多人都知道“变量要先声明再使用”,但实际开发时,却容易“只声明不使用”或者“声明后过很久才使用”:
/**
* 格式化官方素材信息
*
* @param uid
* @param momentTOList
* @param isMomentUser
* @param versionNum
* @param loginUid
* @return
*/
private List<XxxMomentTypeInfoTO> formatXxxMomentTO(Long uid, List<MomentTO> momentTOList, Boolean isSeller,
Boolean isMomentUser, int versionNum, Long loginUid) {
// 你能看出plusGrade是干嘛用的吗?
Integer plusGrade = xxxMemberProfileManager.getPlusGrade(loginUid);
Boolean isGeneralFansSeller = relationUserTypeManager.isGeneralFansSeller(loginUid);
List<Long> momentUidList = ConvertUtil.resultToList(momentTOList, "uid");
List<XxxMemberTO> memberTOS = xxxMemberManager.listMemberByUids(momentUidList);
List<Long> adviserXxxUidList = bizXxxGroupCrm.listAdviserXxxUid();
Map<Long, XxxMemberTO> xxxMemberTOMap = getXxxMemberTOMap(ConvertUtil.listToMap(memberTOS, "uid"));
List<Long> momentIds = ConvertUtil.resultToList(momentTOList, "id", t -> Validator.greaterZero(t.getId()));
List<Long> pids = ConvertUtil.resultToList(momentTOList, "pid", t ->
Validator.isId(t.getPid()) && !Validator.isId(t.getIid()));
List<Long> iids = ConvertUtil.resultToList(momentTOList, "iid", t -> Validator.greaterZero(t.getIid()));
Map<Long, XxxFormatSearchItemTO> formatSearchItemTOMap = new HashMap<>(momentTOList.size());
XxxMomentSearchItemTO momentSearchItemTO = null;
if (!Validator.isNullOrEmpty(pids) || !Validator.isNullOrEmpty(iids)) {
momentSearchItemTO = getItemListByPidIid(pids, iids, loginUid);
}
Map<Long, XxxMomentStoreItemResTO> momentStoreItemResTOMap = mapStoreItemInfo(loginUid, iids);
XxxShopInfoTO shopInfoTO = xxxShopInfoManager.getByUid(uid);
Long shopId = Validator.isNull(shopInfoTO) ? null : shopInfoTO.getId();
Map<String, Boolean> hasForwardMap = checkHasForwardByMomentTOList(uid, momentTOList);
List<PlusGradeInfoTO> plusGradeInfoTOList = xxxMemberProfileManager.listPlusGradeInfoByUid(momentUidList);
Map<Long, PlusGradeInfoTO> plusGradeInfoTOMap = ConvertUtil.listToMap(plusGradeInfoTOList, "uid");
List<XxxMomentTypeInfoTO> momentTypeInfoTOList = Lists.newArrayList();
Map<Long, MomentLikeInfoTO> momentLikeMap = xxxMomentManager.momentLikeInfo(uid, momentIds);
for (MomentTO momentTO : momentTOList) {
XxxMomentTO xxxMomentTO = new XxxMomentTO();
XxxMomentTypeInfoTO momentTypeInfoTO = new XxxMomentTypeInfoTO();
if (xxxMemberTOMap.containsKey(momentTO.getUid())) {
if (Validator.isNotNull(uid) && plusGradeInfoTOMap.containsKey(momentTO.getUid())
&& Validator.isNotNull(plusGradeInfoTOMap.get(momentTO.getUid()).getGrade())) {
Integer shopGrade = plusGradeInfoTOMap.get(momentTO.getUid()).getGrade();
// 顾问的icon取VIP3的
if (adviserXxxUidList.contains(momentTO.getUid())) {
shopGrade = ShopPlusUtil.SHOP_PLUS_VIP3;
}
xxxMomentTO.setShopkeeperIcon(getShopkeeperIconInfoTO(shopGrade));
}
if (Validator.isNotNull(xxxMomentTO.getShopkeeperIcon())
&& getOfficialUidList().contains(momentTO.getUid())) {
xxxMomentTO.getShopkeeperIcon().setUrl(XxxMomentConstant.OFFICIAL_ICON_DEFAULT);
}
Long mapId = null;
if (Validator.isNotNull(momentSearchItemTO)) {
if (Validator.greaterZero(momentTO.getPid()) && !Validator.greaterZero(momentTO.getIid()) &&
momentSearchItemTO.getPidItemMap().containsKey(momentTO.getPid())) {
formatSearchItemTOMap = momentSearchItemTO.getPidItemMap();
mapId = momentTO.getPid();
}
if (Validator.greaterZero(momentTO.getIid()) &&
momentSearchItemTO.getIidItemMap().containsKey(momentTO.getIid())) {
formatSearchItemTOMap = momentSearchItemTO.getIidItemMap();
mapId = momentTO.getIid();
}
}
// 是否有效的iid
Boolean isEffectiveIid = momentStoreItemResTOMap.containsKey(momentTO.getIid())
? Boolean.TRUE : Boolean.FALSE;
String productTitle = null;
String productImg = null;
if (Validator.isNotNull(mapId) && formatSearchItemTOMap.containsKey(mapId)) {
isEffectiveIid = Boolean.TRUE;
productTitle = formatSearchItemTOMap.get(mapId).getTitle();
productImg = formatSearchItemTOMap.get(mapId).getImg();
if (!momentStoreItemResTOMap.containsKey(momentTO.getIid())) {
momentTO.setIid(formatSearchItemTOMap.get(mapId).getIid());
momentTO.setPid(formatSearchItemTOMap.get(mapId).getProductId());
}
xxxMomentTO = getDefaultMomentPriceCms(xxxMomentTO, formatSearchItemTOMap.get(mapId),
loginUid);
}
xxxMomentTO = setMomentPriceCommissionInfo(uid, isMomentUser, isGeneralFansSeller, shopId,
xxxMomentTO, momentTO, momentStoreItemResTOMap, plusGrade, versionNum);
// 买家不显示赚多少
if (!isGeneralFansSeller) {
xxxMomentTO.setCms(null);
}
// 省略100行...
}
}
}不知道大家有没有“变量焦虑”:当我看到一个变量被声明,却无法在5行以内找到它的使用时,我会感到焦虑。在上面的代码中,plusGrade代表用户等级,用于计算不同等级对应的佣金。但是,变量声明在第14行,使用却在第83行...这会造成至少两个困惑:第14行初见时我不知它将去往何处,第83行再见时我不知它来自何方,两次相见都只能默默流泪。
变量声明与变量使用隔得太远,是很多程序员的通病。这种不良的编码风格,不仅影响可读性,还可能造成性能浪费。比如:
public void method() {
Integer plusGrade = memberProfileManager.getPlusGrade(loginUid);
// 隔了80行...
Long commission = caculateCms(originPrice, plusGrade);
}如果中间发生了异常,代码没有执行到caculateCms(),那么plusGrade的获取就毫无意义,白白浪费一次网络调用。所以,对于变量声明,不仅要见名知意,还要遵守“使用时再声明”,或者“声明后立即使用”。
用卫函数代替if else
小册在介绍Optional时,曾经提到过卫函数。所谓卫函数,一句话概括就是“及时return,以避免过深的嵌套”。
public static String getDepartmentNameOfUser(String username) {
ResultTO<User> resultTO = getUserByName(username);
if (resultTO != null) {
User user = resultTO.getData();
if (user != null) {
Department department = user.getDepartment();
if (department != null) {
return department.getName();
}
}
}
return "未知部门";
}像上面这种情况,嵌套就太深了(通常我连双层嵌套都无法忍受),如果每层嵌套中代码量再上去一些,阅读难度就会陡增。此时可以通过卫函数,分步消解:
public static String getDepartmentNameOfUser(String username) {
ResultTO<User> resultTO = getUserByName(username);
if (resultTO == null) {
return "ResultTO为空";
}
User user = resultTO.getData();
if (user == null) {
return "User为空";
}
Department department = user.getDepartment();
if (department == null) {
return "Department为空";
}
return department.getName();
}大家平时也可以多一个心眼,出现if嵌套时考虑下使用卫函数(特别是参数校验的场景),毕竟我们的大脑更习惯结构化的内容,强行套娃容易把自己搞晕。
网上有很多《求求你,别再用if else了》之类的文章,翻来覆去就那几种方式,有兴趣可以去了解一下。
像写诗一样换行
自从新文化运动以后,我们国家开始提倡白话文,为后面的扫盲打下了坚实的基础。现如今,普通人也能自己写诗了,唯一的诀窍就是:换行。
宝
今天我去输液了
输的什么液
想你的夜换行的好处在于,通过在合适的地方切断信息流,让读者能快速理清行文逻辑。编写代码也是如此,有时只需简单地换行,就能大大地提高可读性。
private List<RebateItemDetailInfo.ShopScore> getScoreList(ProductDetail productDetail) {
// 描述
RebateItemDetailInfo.ShopScore descScore = new RebateItemDetailInfo.ShopScore();
descScore.setScore(formatScore(productDetail.getDescScore()));
descScore.setType(ShopScoreTypeEnum.DESC.getType());
// 服务
RebateItemDetailInfo.ShopScore serviceScore = new RebateItemDetailInfo.ShopScore();
serviceScore.setScore(formatScore(productDetail.getServiceScore()));
serviceScore.setType(ShopScoreTypeEnum.SERVICE.getType());
// 物流
RebateItemDetailInfo.ShopScore shipScore = new RebateItemDetailInfo.ShopScore();
shipScore.setScore(formatScore(productDetail.getShipScore()));
shipScore.setType(ShopScoreTypeEnum.SHIP.getType());
return Lists.newArrayList(descScore, serviceScore, shipScore);
}哦,对了,刚才那个plusGrade的代码,之所以读起来那么痛苦,其中一个原因就是没换行,甚至一点注释都没有...整个方法只有一个信息流,太大块了!如果想要临时去改一些逻辑,不得不从头到尾理解每个细节,有种你明明不想吃屎,却被强行按着头吃了一口屎的感觉,难受至极。
好的代码,应该可以让阅读它的人立即找到他关心的逻辑,而不是强迫对方去关注无关紧要的细节。
看到这,扪心自问,你写的代码像诗呢,还是像屎呢...
抽取方法
当一个方法的行数过多时,简单的换行就显得力不从心了,此时可以考虑抽取方法。抽取方法的核心要点是,把强相关的代码抽取到同一个方法中,保证一个方法只做一件事。假设10~20行都是查询用户信息的,那么就可以抽取出private User getUser(Long uid)。
由于借助IDE很容易就可以做到,这里就不再扩展。但有一点需要特别强调,是关于编码习惯的。很多新手程序员,喜欢一上来就噼里啪啦一顿敲,中间删删改改,代码块移来移去,最终显得异常凌乱。
我个人的习惯是,上来先写好注释:
/**
* 增加用户成长值
*/
public boolean upgradeGrowthValue(Long uid, Long iid) {
// 用户是否存在
// 查询用户等级
// 查询当前用户等级对应的成长值比例
// 查询商品成长值
// 计算实际成长值并更新
}有了这个骨架,其实很自然就能写出结构化的代码:
/**
* 增加用户成长值
*/
public boolean upgradeGrowthValue(Long uid, Long iid) {
// 用户是否存在
boolean userExist = checkIfUserExist(uid);
if(!userExist) {
return false;
}
// 查询用户等级
Integer plusGrade = getUserLevel(uid);
// 查询当前用户等级对应的成长值比例
Long growthRate = getGrowthRate(plusGrade);
// 查询商品成长值
Long itemGrowthValue = getItemGrowthValue(iid);
// 计算实际成长值并更新
Long finalGrowthValue = calculateGrowth(growthRate, itemGrowthValue);
return updateGrowthValue(uid, finalGrowthValue);
}哪怕有一天你离职了,新同事需要在这基础上调整成长值比例,他只需要关心getGrowthRate()方法即可,根本不用理会其他逻辑。换句话说,他会感谢你没有强行让他吃屎...至于这位新同事会不会让后面的人感到为难,就要看他的职业操守了。如果他接到的需求不是修改逻辑,而是新增逻辑呢?希望他也能记得抽取方法,不要让代码腐败得太快。
有一次我在处理另一个需求,太忙了,没时间对原先写的搜索接口做关键词屏蔽,于是让另一个同事帮忙,不到十分钟他就写好了。等晚上忙完之后,我重新pull代码,发现他写得很清爽:
@Override
public ApiResultTO<ItemSearchResTO> execute(ItemSearchReqTO reqTO) {
if (Validator.isNullOrEmpty(reqTO.getKeyword())) {
return ApiResultTO.buildFailed("请输入关键词");
}
ItemSearchResTO resTO = new ItemSearchResTO();
resTO.setItems(Collections.emptyList());
// IOS审核期间,关键词屏蔽(在我的主流程方法里,他只加了3行代码)
if (searchForbidden(reqTO.getKeyword())) {
return ApiResultTO.buildSuccess(resTO);
}
// ... 省略50行
}
private boolean searchForbidden(String keyword) {
// 是否IOS审核期间
boolean isIos = RebateVersionUtils.isIos();
Integer versionNum = RebateVersionUtils.getVersionNum();
boolean isIosAuditVersion = isIos && appVersionGrayManager.isAuditVersion(versionNum);
if(!isIosAuditVersion) {
return false;
}
// 需要屏蔽的关键词
String conf = BconfUtil.getConfValueByPath(BconfConstants.SEARCH_FORBIDDEN_KEYWORDS, null);
List<String> searchForbiddenKeywords = Optional.ofNullable(JSON.parseArray(conf, String.class))
.orElse(Collections.emptyList());
// 是否包含屏蔽的关键词
boolean matchForbiddenKeyword = matchForbiddenKeyword(keyword, searchForbiddenKeywords);
// IOS审核期间 && 关键词被屏蔽
if (isIosAuditVersion && matchForbiddenKeyword) {
return true;
}
return false;
}
private boolean matchForbiddenKeyword(String keyword, List<String> searchForbiddenKeywords) {
if (Validator.isNullOrEmpty(keyword) || Validator.isNullOrEmpty(searchForbiddenKeywords)) {
return false;
}
String trimKeyword = keyword.trim();
return searchForbiddenKeywords.stream()
.anyMatch(forbiddenKeyword ->
forbiddenKeyword.contains(trimKeyword) || trimKeyword.contains(forbiddenKeyword));
}一个方法最好不要超过80行,甚至50行。平时可以把IDE的字体调大一些(size=14挺舒服的),既能缓解眼疲劳,又能强迫自己不会写出行数超过一个屏幕的方法。
最后,任何你觉得不是很重要的代码,都可以抽出来,不要占用主流程宝贵的篇幅,比如POJO的set方法:
public UserTO selectUser(Long uid) {
UserDO userDO = userService.selectOne(uid);
return buildUserTO(userDO);
}
private UserTO buildUserTO(UserDO userDO) {
// setters...
}又或者,任何你觉得冗余的地方:
public void method() {
// ...
if(Validator.isNotNullOrEmpty(activityList)) {
for(Activity activity : activityList) {
if (isOverlap(reqTO.getGmtBegin(), reqTO.getGmtEnd(), obmActivityBizMapTO.getGmtBegin(),
obmActivityBizMapTO.getGmtEnd())
&& !obmActivityBizMapTO.getActivityId().equals(reqTO.getId())
&& bizIdList.contains(obmActivityBizMapTO.getBizId())) {
return ServiceResultTO.buildFailed("当前时间段有重复活动在线,活动id" + obmActivityBizMapTO.getActivityId());
}
}
}
// ...
}
private boolean isOverlap(Long leftStartTime, Long leftEndTime, Long rightStartTime, Long rightEndTime) {
return ((leftStartTime >= rightStartTime)
&& leftStartTime < rightEndTime)
||
((leftStartTime > rightStartTime)
&& leftStartTime <= rightEndTime)
||
((rightStartTime >= leftStartTime)
&& rightStartTime < leftEndTime)
||
((rightStartTime > leftStartTime)
&& rightStartTime <= leftEndTime);
}isOverlap()既然抽取了方法,那就干脆抽取得彻底一些:
public void method() {
// ...
if(Validator.isNotNullOrEmpty(activityList)) {
for(Activity onlineActivity : activityList) {
if (timeScheduleConflict(currentActivity, onlineActivity)) {
return ServiceResultTO.buildFailed("当前时间段有重复活动在线,活动id" + obmActivityBizMapTO.getActivityId());
}
}
}
// ...
}
boolean timeScheduleConflict(ActivityModifyReqTO current, ActivityBizMapTO online) {
boolean beginConflict = online.getGmtBegin() <= current.getGmtBegin() && current.getGmtBegin() <= online.getGmtEnd();
boolean endConflict = online.getGmtBegin() <= current.getGmtEnd() && current.getGmtEnd() <= online.getGmtEnd();
boolean isSelf = online.getActivityId().equals(current.getId());
// 和别的活动时间冲突
return (beginConflict || endConflict) && !isSelf;
}抽取类
代码块换行不管用时,需要抽取方法。同样地,当方法重复、膨胀时,你就该考虑这些方法是否可以抽取到类中。比如,可能很多地方都要用到getGrowthValue(Long iid)这个方法,如果每个方法内部都抽取一个getGrowthValue(Long iid),就太冗余了,后期改动也不方便,甚至会漏改。如果说,抽取方法是结构化编程思维,那么抽取到类,就稍微有点面向对象的味道了。
但是,如果你理解的面向对象就是把方法抽取到类,那就太肤浅了。在文章末尾,我会提出自己的见解。
少用显式for循环(多使用Java8)
我已经不止一次推荐大家多多使用Java8了,小册也花费了很多笔墨介绍Java8的诸多特性,特别是Stream API。Stream API都是内部迭代,它的好处是方便将遍历的流程与业务逻辑解耦,让我们能更加专注于业务逻辑的编写(如果你觉得Java8不好用,可能是不够了解它,可以先去复习小册Java8相关章节)。
比如:
public class StreamTest {
private final static List<Person> personList = ImmutableList.of(
new Person("i", 18, "杭州", 999.9),
new Person("am", 19, "温州", 777.7),
new Person("iron", 21, "杭州", 888.8),
new Person("iron", 17, "宁波", 888.8)
);
public static void main(String[] args) {
List<String> suitablePersonNames = filterSuitablePersonNames(List<Person> personList);
System.out.println(suitablePersonNames);
}
public static List<String> filterSuitablePersonNames(List<Person> personList) {
List<String> names = new ArrayList<>();
for (Person person : personList) {
if (person.getAge() < 18) {
continue;
}
if (!"宁波".equals(person.getAddress())) {
continue;
}
if (names.contains(person.getName())) {
continue;
}
names.add(person.getName());
}
return names;
}
}上面这段代码没什么太大问题,但传统的for循环有个弊端:容易暴露过多无关紧要的细节,让人无所适从。还是开头plusGrade那个案例,一个for循环100+行代码,如果你想搞清楚这里头都干了啥,不得不硬着头皮一行行读下去,最差的情况是,里面可能还充斥各种if嵌套、变量随处声明、不换行也不抽取方法,十分蛋疼。这个时候,如果女朋友刚好无理取闹,轻则感情破裂、重则分手边缘。这种毁人幸福的事,还是要少做。
但有了Java8的Stream API后,我们就可以挽回这段感情:
public class StreamTest {
private final static List<Person> personList = ImmutableList.of(
new Person("i", 18, "杭州", 999.9),
new Person("am", 19, "温州", 777.7),
new Person("iron", 21, "杭州", 888.8),
new Person("iron", 17, "宁波", 888.8)
);
// Stream API本身具有良好的可读性,filter、map等函数本身就是结构化的
public static void main(String[] args) {
Set<String> suitablePersonNames = personList.stream()
.filter(person.getAge() > 18 && "宁波".equals(person.getAddress())) // 过滤出年龄大于18 && 来自宁波的
.map(Person::getName) // 只要他们的名字
.collect(Collectors.toSet()); // 收集到set,避免重复
System.out.println(suitablePersonNames);
}
}如果条件再复杂些,可以考虑抽取方法:
public static void main(String[] args) {
Set<String> suitablePersonNames = personList.stream()
.filter(StreamTest::ageGt18AndFromNingbo) // 过滤出年龄大于18 && 来自宁波的
.map(Person::getName) // 只要他们的名字
.collect(Collectors.toSet()); // 收集到set,避免重复
System.out.println(suitablePersonNames);
}
private static boolean ageGt18AndFromNingbo(Person person) {
return person.getAge() > 18 && "宁波".equals(person.getAddress());
}是不是逻辑清晰、代码量又少?还是那句话,尽量别给爱你的同事强行喂屎...
当然,Java8可不止Stream API,还有很多好用的新增方法,比如Map的computeIfPresent()、Collection的removeIf()等,使用得当可以帮我们简化一部分冗余的代码:
public class StreamTest {
private static List<Person> personList = Lists.newArrayList(
new Person("i", 18, "杭州", 999.9),
new Person("am", 19, "温州", 777.7),
new Person("iron", 21, "杭州", 888.8),
new Person("iron", 17, "宁波", 888.8)
);
public static void main(String[] args) {
// 可以避免并发修改异常
boolean removed = personList.removeIf(person -> "杭州".equals(person.getAddress()));
System.out.println(personList);
}
}最后需要说明的是,在一定条件下(开启并行流或者大数据量)Stream的效率确实要优于普通for/foreach,而一般编程场景中普通for/foreach可能效率更好些。但是,我仍推荐使用Java8,因为可读性是最重要的,而且内存计算0.x毫秒的差距是微不足道的,与其争这点时间,不如多注意网络IO(一次数据库访问是100ms左右)。
记得打日志
很多新手程序员,特别是从外包或者小公司出来的同学,都不太喜欢打日志。究其原因,大致有两点考量:
- 以前的项目很小,发现bug可以直接本地打断点排查,直接System.out.println()即可,久而久之养成了不打日志的“好习惯”
- 担心日志会拖慢性能,能不打就不打
实际上很多大型的项目,比如电商系统,一般来说本地是无法启动的,无论是问题排查还是个人测试,都是直接在预发环境做的,专门去打断点比较浪费时间(公司提供了远程调试,但还是比较麻烦)。退一步讲,线上出现个问题,你难道要和产品说:等我一下,我拉个分支本地去打断点?
至于说打日志会降低性能,大可不必...log的性能损耗微乎其微。
通常来说,自己负责的业务出现问题时,心里基本能猜个八九不离六的,更多时候你只需要验证和排除可能存在的问题。我的习惯是直接打开公司的ELK,搜索代码中的日志关键字,看看出入参,基本就能知道是什么问题。实在定位不了问题,才会拉分支远程调试。
比如产品反馈某个页面的数据没了:
那么排查过程是怎样的呢?
先定责:客户端/前端的问题,还是后端接口的问题?抓包发现接口数据确实为空,所以是接口问题。
查看具体接口,发现有日志,于是上ELK查看数据:
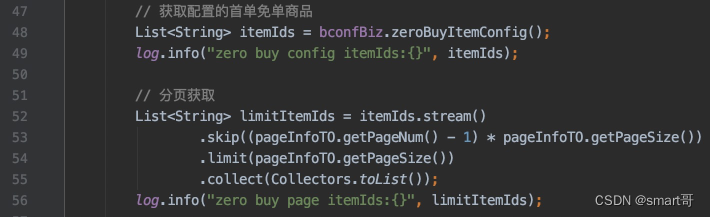
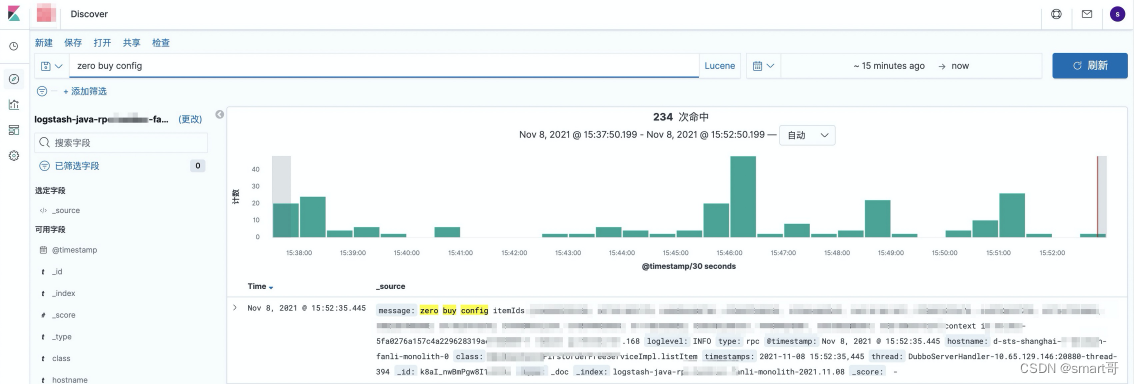
发现两个log都是有数据的,但是最终返回却没有数据,于是继续往下游追溯:
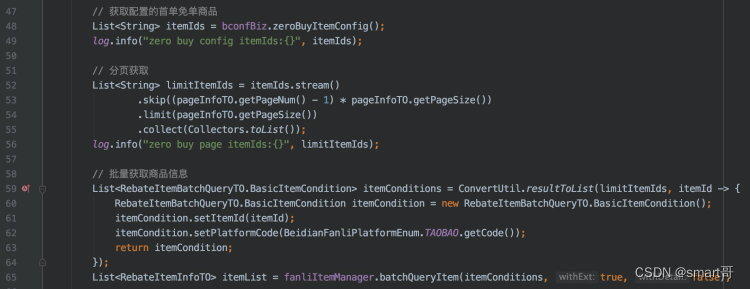
RPC调用后返回emptyList,那么问题肯定在batchQueryItem接口:

哦,原来是因为下游出于性能考虑限制了批量请求的数量,而前端并没有按规定分页,直接传了pageSize=100。
所以最后让前端加上分页条件,顺利解决。日志在本次排查中发挥了关键作用 !
性能
很多人以为,代码性能优化很神秘,其实就我个人的体会来说,大部分所谓的性能优化,归根结底就两个原则:
- 要么减少IO
- 要么减小IO
其中,大部分时候我们会选择减少IO(网络IO)。
避免循环嵌套
大家平时可能会尽量避免在Service方法中多次调用DAO方法:
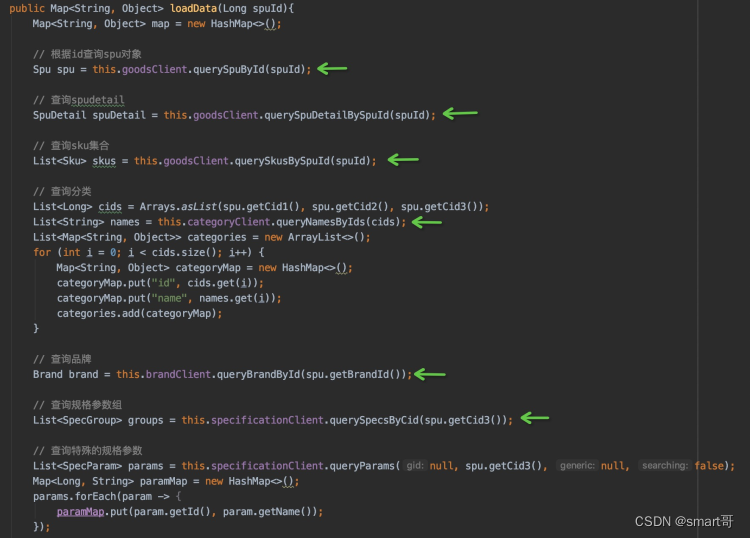
这种肉眼可见的网络调用,大部分人往往一眼就能看出来。然而,一旦把它们塞到循环语句中,很多人就不敏感了。
举一个实际工作中遇到的案例。有一天测试过来找我,说客户端反应有个素材接口偶尔会超时,导致页面不展示数据。我排查了一下,原来是同事在代码里循环调用了当前素材的分享数:
List<Material> list = listMaterial();
list.foreach(material->{
Integer shareCount = getShareCount(material.getId()); // 循环调用了分享次数统计SQL
});于是我对这个接口进行了优化:
List<Material> list = listMaterial();
List<Long> materialIds = list.stream().map(Material::getId).collect(Collectors.toList());
// 批量获取素材对应的分享数
Map<Long, Integer> materialIdWithShareCount = getShareCount(materialIds);
list.foreach(material->{
// 循环里只做数据匹配,不进行网络调用
Integer shareCount = materialIdWithShareCount.getOrDefault(material.getId(), 0);
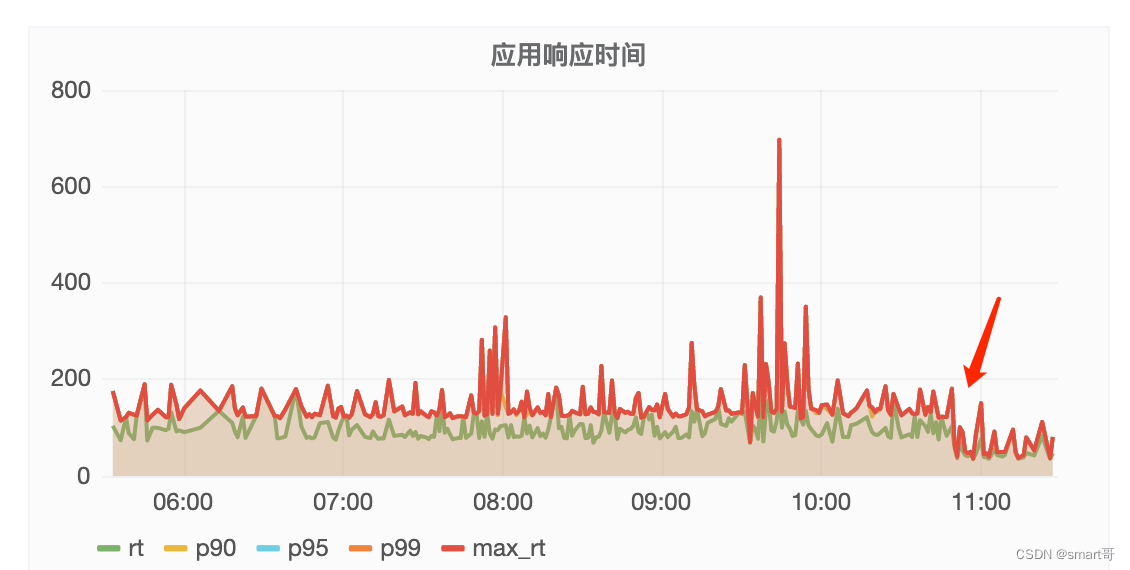
});最终接口耗时降了100ms:
同样地,类似双层for循环调用dao啥的,就更该避免了...
注意,上面问题的根结是网络IO次数,而不是循环的次数。如果本身不涉及IO,只是内存数据的处理,其实双层for效率也没有差很多(特别是一般分页只有10条)。
时刻注意非空判断
空指针是我们一生的宿敌,这个我们后面再说。
考虑使用缓存
在合适的地方,考虑使用缓存。而一旦使用缓存,就要做好觉悟:能否接受一定程度的更新延迟,也就是缓存脏读问题。
@Service
public class ItemServiceImpl implements ItemService {
@Resource
private CacheClient cacheClient;
private static final String ITEM_CACHE_PREFIX = "item:detail:";
/**
* 查询商品
*
* @param itemId 商品id
* @param useCache 是否使用缓存
* @return
*/
public Item getItem(Long itemId, boolean useCache) {
if (!useCache) {
return this.doGetItem(itemId);
}
String cacheKey = ITEM_CACHE_PREFIX + itemId;
String itemJson = cacheClient.get(cacheKey);
if (itemJson != null && !"".equals(itemJson)) {
// parse and return
return JSON.parseObject(itemJson, Item.class);
}
// the data is not cached, then query DB and store it
Item item = this.doGetItem(itemId);
// in case the result is null, put an empty Object into the cache
item = Optional.ofNullable(item).orElse(this.createEmptyItem(itemId));
cacheClient.cache(cacheKey, item, 60, TimeUnit.SECONDS);
return item;
}
private Item doGetItem(Long itemId) {
// query DB
return null;
}
private Item createEmptyItem(Long itemId) {
// create an empty item Object
return null;
}
}为常用的SQL添加索引
参考小册SQL优化章节。
设计
最后聊一下代码设计。
结构化编程与面向对象
上面提到过,代码多了抽取到方法,方法多了抽取到对象,这是符合一般常识的做法。但是,把方法抽取到对象中就算面向对象编程了吗?个人觉得,面向对象的精髓是多态,也正因为有了多态,才让Java等面向对象的语言具备更多的可玩性,也让代码具备抽象性,更趋于稳定。
比如,原本工程中有个查询外部商品的接口:
@Service
public class ItemService {
@Resource
private TaobaoClient taobaoClient;
@Resource
private PddClient pddClient;
public Item queryItem(String itemId, Integer platform, boolean useCache){
// 判断是否使用缓存
...
if(PlatformEnum.TAOBAO.getCode().equals(platform)) {
// 调用淘宝接口
} else if(PlatformEnum.PDD.getCode().equals(platform)) {
// 调用拼多多接口
}
// 缓存商品信息
...
}
}随着对接的第三方平台越来越多,代码开始膨胀(这个Service内部会有两个几乎相同逻辑的外部接口调用流程),于是我们把淘宝和拼多多抽取到对应的类中:
@Service
public class TaobaoItemService {
@Resource
private TaobaoClient taobaoClient;
public Item queryItem(String itemId){
// 省略具体代码
}
}
@Service
public class PddItemService {
@Resource
private PddClient pddClient;
public Item queryItem(String itemId){
// 省略具体代码
}
}一个魔术,最难的不是怎么把东西变没,而是如何把消失的东西变回来。现在淘宝和拼多多被我们拆成两个服务,而我们期望的代码是:
@Service
public class ItemService {
public Item queryItem(String itemId, Integer platform, boolean useCache){
// 判断是否使用缓存
...
// 调用第三方服务(不关心具体的类型)
Item item = thirdpartyItemService.queryItem(itemId, platform);
// 缓存商品信息
...
}
}所以,怎么把它们合起来呢?比较可行的处理方案是:
// 抽取接口
public interface ThirdPartyItemDetailService {
Item queryItem(String itemId);
}
@Service("taobaoItemService")
public class TaobaoItemServiceImpl implements ThirdPartyItemDetailService {
@Resource
private TaobaoClient taobaoClient;
@Override
public Item queryItem(String itemId){
// 省略具体代码
}
}
@Service("pddItemService")
public class PddItemServiceImpl implements ThirdPartyItemDetailService {
@Resource
private PddClient pddClient;
@Override
public Item queryItem(String itemId){
// 省略具体代码
}
}现在策略是有好多种了,怎么用呢?难道还是这样?
if(PlatformEnum.TAOBAO.getCode().equals(platform)) {
// 调用淘宝
return taobaoItemService.queryItem(itemId);
} else if(PlatformEnum.PDD.getCode().equals(platform)) {
// 调用拼多多
return pddItemService.queryItem(itemId);
}这不就走回头路了嘛...其实Spring可以帮我们。
很多人都知道@Autowired/@Resource能帮我们自动注入Bean,但实际上Spring不仅能帮我们自动注入单个Bean,还能帮我们注入BeanList、BeanMap。
比如:
@Autowired
private List<ItemService> itemServiceList;Spring会把项目中所有实现了ItemService接口的类的实例汇聚到itemServiceList中(不仅实现接口,继承类也行),在我们的案例中,itemServiceList将会包含TaobaoItemService、PddItemService。
如果使用Map注入:
@Autowired
private Map<String, ItemService> itemServiceMap;那么itemServiceMap也会被注入,大概是这样:
{
"taobaoItemService": 淘宝商品服务实例对象,
"pddItemService": 拼多多商品服务实例对象,
}Map的key就是Bean实例的名字(大家可以回到上面看看,我特地在定义TaobaoItemServiceImpl时指定了bean name)。
所以,刚才的案例可以优化为:
@Slf4j
@Component
public class ItemFactory {
// 第一步:Spring帮我们收集了所有实现了ThirdPartyItemDetailService接口的bean
@Resource
private Map<String, ThirdPartyItemDetailService> itemDetailServiceMap;
public Item queryItem(String itemId, Integer platformCode) {
// 第二步:根据platformCode获取PlatformEnum(Enum里定义了taobao、pdd字符串)
PlatformEnum platform = PlatformEnum.getSourceKeyByCode(platformCode);
// 第三步:拼凑出正确的bean name,比如 taobao+ItemService => taobaoItemService
String serviceName = platform.getSourceKey() + "ItemService";
// 第四步:从Map中得到对应的service bean
ThirdPartyRecommendItemService thirdPartyItemDetailService = itemDetailServiceMap.get(serviceName);
// 查询商品
return thirdPartyItemDetailService.queryItem(itemId);
}
}最终暴露出去的接口:
@Service
public class ItemService {
@Resource
private ItemFactory itemFactory;
public Item queryItem(String itemId, Integer platform, boolean useCache){
// 判断是否使用缓存
...
// 获取商品(不关心具体平台)
Item item = itemFactory.queryItem(itemId, platform);
// 缓存商品信息
...
}
}
上面的结构看起来好像比原先if else要麻烦很多,但整体设计思路已经发生了质的改变,后面有新的平台接入时,只需要新建一个XxxItemServiceImpl并实现接口即可,做到了“以增量的方式应对变化的需求”,是符合好的设计原则的(开闭原则)。
这才是面向对象,核心是多态。
掌握常用的几种设计模式
部分同学可能不认为上面使用的是工厂模式,但我想说的是,是什么模式不重要,能解决问题就行。很多人,对各种设计模式如数家珍,但实际开发却总是在编写“扁平的代码”,所有的逻辑平铺直叙,拥挤在一个大类中,职责划分不清,各种业务逻辑相互纠缠、盘根错节。
这个时候,我们需要回归设计模式的本质,即:为什么要使用设计模式?
首先,设计模式其实只是对特定语言缺陷的一种补救措施,比如对于Java早期版本来说,策略模式是很有必要的,但随着Lambda表达式的引入,策略模式也慢慢失去了原有的意义(不再需要补救),对于JS等脚本语言来说,干脆天然就支持传递Function(从一开始就不需要补救)。
其次,设计模式的根本目的,其实还是抵御变化,或者减少变化带来的影响。好的设计模式能够阻止或者延缓迭代过程中代码的腐败,让软件的生命周期更加长久。就好比上面的ItemFactory,后面如果对接京东的商品服务,我们只需要另外写一个JdItemService实现ThirdPartyItemDetailService即可。也就是以增量的方式来应对变化的需求,进而达到较为理想的软件管理(符合开闭原则)。
实际开发最常用的设计模式无非策略模式、模板方法模式、工厂模式、责任链模式,反正绝对不会23种都用得上(实际上也不止23种),平时可以多了解一些有用的、常用的。但还是那句话,是什么模式不重要,能解决问题就行。有些模式是不好区分的,也没必要区分。
小结
今天看似洋洋洒洒说了很多,其实总结起来就是:要对自己的代码负责,为他人着想。写完代码后自己看一遍,是否通俗易懂。自己都看不懂,别人就更加云里雾里了。总之,不要强行喂人吃屎,话糙理不糙。
对了,文章里提到的很多注意事项,其实装个IDEA插件就能得到提示。人啊,还是要靠外在约束。有时屁事一多,真的很想就这么拉了算了,别人爱吃不吃...阿弥陀佛,罪过罪过。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!