机器学习概述
最近在学习机器学习的基础知识,在此记录一下
目前最火的机器学习框架是Scikit-Learn和pytorch,因此,之后的一段时间会使用这两种框架搭建机器学习的模型,相应的学习资源也会开源,希望可以学习到很多知识。
简单介绍机器学习的概念和应用:
机器学习:指利用计算机的机器通过统计学等算法知识,对大量收集到的历史数据进行学习和分析,进而利用生成的经验模型指导相关的业务,例如我们生活中常见的金融风险预测、股票预测、送餐时间预测、电影推荐系统、垃圾邮件过滤、预测蛋白子的三维结构、检查皮肤癌等等。同时机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。因此,数学知识的积累是学习机器学习必不可少的一部分。同时,机器学习被用于专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构,使之不断改善自身的性能。所以,机器学习一直都是人工智能的中不可或缺的一部分。
我们生活中一个数据极为充沛的时代,使用机器学习算法可以将数据转换为知识。
应用:
1.图像识别
2.医疗诊断
3.自然语言处理
4.医疗健康
5.推荐系统
6.语音识别
7.能源管理
8.计算机视觉
9.智能家居
10.预测
11.社交媒体分析
12.商品图片分类
13.自动语言翻译
14.智能客服
15.在线欺诈检测
16.金融风险
一.机器学习的几个子领域
1.1三种机器学习类型
1.1.1预测未来的监督学习
监督学习的目的在于从有标签的训练数据中学习一个模型,并使用这一模型预测未知或未来无标签数据。监督学习又被誉为有标签的学习。
训练:处理数据->使用机器学习算法训练模型->预测模型
测试:新数据->预测模型->预测标签
预测离散数值标签的分类任务
预测连续数值标签的回归任务
在给定一组数据的特征变量x和一个目标变量y,为该数据拟合一条直线,使数据点和拟合直线之间的距离(局方距离,平均平方距离等)最小。
简单的举个例子
比如给定一组数据来预测学生的成绩:x=(0,200,89),y=76
其中0表示性别,200表示做题目的数量,89表示上次的成绩
给定这样的大量数据,从而预测y(最终学生的学习成绩)
这样的一组数据就是有监督的数据。
当然,可能存在多个标签,比如预测的y是成绩和性格等,此处只是只是简单的举个例子,并不一定x和y之间的关系是正确的。
1.1.2解决交互问题的强化学习
强化学习是一个可以和学习环境交互提高系统性能的智能体。通过相应的激励信号给与一定的反馈,但是提供的反馈信息往往不一定是正确的标签,而是奖励函数对智能体动作做出的奖励,用于衡量动作的正确程度。一般来说强化学习是一种试错机制,使用动态规划的方法或探索性的试错方法学习到一系列的动作,最大化环境提供的奖励。
1.1.3发现数据中隐藏规律的无监督学习
无需知道数据的变量或结构未知的数据或奖励的函数,通过聚类的方式挖掘数据结构性信息或数据间关系的方法,这些信息之间具有一定的相似性或差距。
例如给定一组客户的兴趣数据,然后发现特定的兴趣的客户群,从而可以指定有效的营销计划,那么如何使用机器学习的方式将其进行聚类,发现其中的规律,并制定相应的营销计划。
无监督学习还有一个作用,就是如何用于降为压缩数据。
如何将一个高维的数据进行降为,还可以保存相应的特征?这便是无监督数据的另外一个研究方向。这个研究方向一般被应用于特征预处理,去除数据中的噪声,但是一般降维会降低机器学习算法的预测性能。数据降维会在保留数据大部分信息的前提下,将数据从高维子空间压缩到低维子空间。
1.2基本术语与符号
符号:小写加粗x一般表示向量,大写加粗X表示矩阵,R表示实数
术语
训练样例:数据集中的每一行,与观察、记录、实例、样本同义。
训练:模型拟合。类似于参数估计。
特征:缩写为x,数据表格或数据矩阵的一列。与预测变量、变量、输入、属性、协变量定义。
目标:缩写为y,与结果、输出、响应变量、因变量、标签、真实值同义。
损失函数:通常与代价函数同义,有时也称为误差函数,有些文献中的损失指单个数据的损失值,而代价是整个数据集的损失值。
二.实现典型机器学习的基本步骤
2.1数据预处理-让数据可用
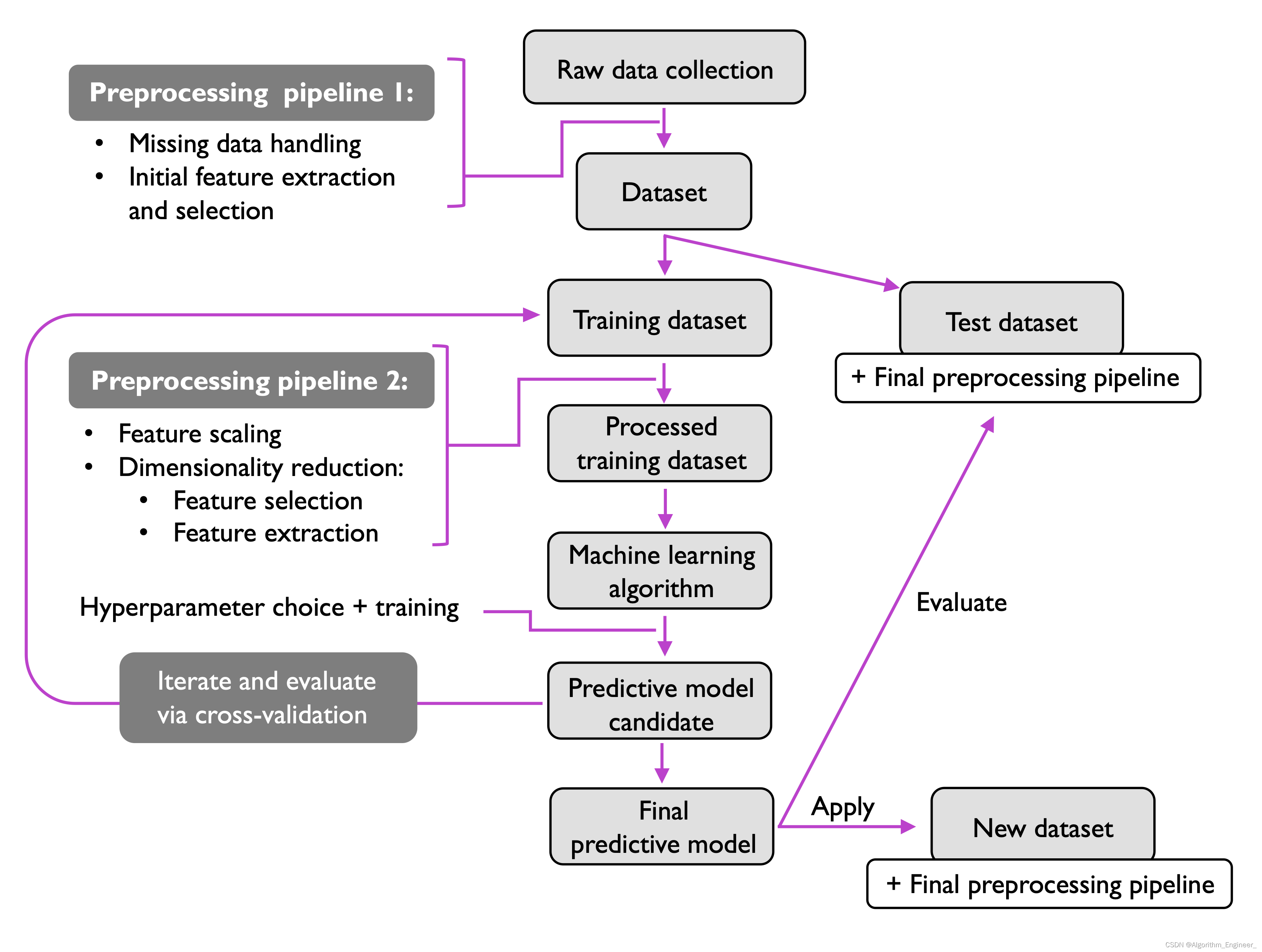 这里给出了机器学习的流程图!
这里给出了机器学习的流程图!
一般在数据预处理的过程中,需要去除空值和不相关的特征值(噪声),特征归一化等操作。
2.2训练和选择预测的模型
在实践过程中,需要使用训练集数据集训练模型,然后使用测试集测试模型的性能,一般会使用多种不同的模型进行训练,然后选择最好的模型,在比较不同的模型之前,需要考虑使用哪种评估指标。
在机器学习中,一般使用交叉验证将数据集划分为相应的子集,以便用于评估模型的泛化性。
一般在训练的过程中,需要调参数,可以学习一下元学习的知识,可以自动让模型学习最优的参数。
2.3评估
一般利用测试集进行评估,在训练集训练完成模型后,需要使用新的数据验证模型的性能,从而预估所谓的泛化误差。
在处理训练集和测试集合的过程中,需要使用相同的操作,不然会导致高估模型的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!