普通二叉树和右倾斜二叉树--LeetCode 111题《Minimum Depth of Binary Tree》
本文将以解释计算二叉树的最小深度的思路为例,致力于用简洁易懂的语言详细描述普通二叉树和右倾斜二叉树在计算最小深度时的区别。通过跟随作者了解右倾斜二叉树的概念以及其最小深度计算过程,读者也将对左倾斜二叉树有更深入的了解。这将为解决LeetCode 111题《Minimum Depth of Binary Tree》提供有力支持。最终,本文将提供LeetCode 111的解题代码。
题目内容-- Leetcode111. Minimum Depth of Binary Tree
Given a binary tree, find its minimum depth. The minimum depth is the number of nodes along the shortest path from the root node down to the nearest leaf node. Note: A leaf is a node with no children.
例子1??: ?例子2??
?例子2??
输入:root = [3,9,20,null,null,15,7]? ? ? ? ? ? ? ?? ? ?输入:root = [2,null,3,null,4,null,5,null,6]
输出:2? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 输出:5
解题思路分析
-
普通二叉树
- 理解问题:首先,理解问题的要求。问题要求找到给定二叉树的最小深度,即从根节点到最近的叶子节点的最短路径上的节点数。
- 考虑特殊情况:考虑特殊情况,比如空树或只有一个节点的树。对于这些情况,最小深度分别为0或1。
- 使用递归:采用递归的方式来解决问题。从根节点开始,递归地计算左子树和右子树的最小深度。然后,最小深度是左右子树最小深度的较小值加上1。
- 处理叶子节点:在递归过程中,需要特别注意处理叶子节点的情况。叶子节点的最小深度是1。
? ? ? ? ? ? 下面是可能实现的伪代码:? ? ? ? ? ?
def minDepth(root):
# 处理空树的情况
if root is None:
return 0
# 处理叶子节点的情况
if root.left is None and root.right is None:
return 1
# 计算左右子树的最小深度
left_depth = minDepth(root.left)
right_depth = minDepth(root.right)
# 返回最小深度
return min(left_depth, right_depth) + 1
因此,这个递归算法通过适当的处理,可以灵活地应对不同形态的二叉树,包括右倾斜二叉树和普通二叉树。? ? ? ? ? ? ? ??
-
右倾斜二叉树
- 定义:右倾斜二叉树(Right-skewed binary tree)是一种特殊的二叉树结构,其中每个非叶子节点只有右子节点,而没有左子节点。这导致树的形状是向右倾斜的,呈现出一种链表的形式。
- 右倾斜二叉树的特点包括:(1)每个非叶子节点最多右一个子节点,且该子节点是右子节点。(2)左子树为空,右子树可能为空或者不为空。(3)从根节点到任意叶子节点的路径都只包含右子节点。
- 对于右倾斜二叉树,树中的每个节点都只有右子树,递归的方式可以稍微修改一下。在递归计算最小深度时,我们需要考虑到只有右子树的情况。以下的代码可以处理三种情况:(1)普通二叉树;(2)右倾斜二叉树;(3)以右倾斜二叉树开头+普通二叉树的混合结构。
def minDepth(root): # 处理空树的情况 if root is None: return 0 # 递归计算右子树的最小深度 right_depth = minDepth(root.right) # 如果左子树为空,说明只有右子树,返回右子树的最小深度加上1 if root.left is None: return right_depth + 1 # 如果左右子树都存在,返回左右子树最小深度的较小值加上1 return min(minDepth(root.left), right_depth) + 1这样的实现考虑了右倾斜二叉树的情况,递归过程会一直沿着右子树向下进行,直到找到叶子节点。同样,返回的最小深度是左右子树最小深度的较小值加上1。
-
以上代码之所以能够处理普通二叉树和右倾斜二叉树的情况,是因为在递归计算最小深度的过程中,代码会考虑每个节点的左右子树情况,从而综合考虑了整个树的结构。分布解释为什么会有效:
-
递归基准:在递归函数中,首先处理了空树的情况,如果树为空,则返回深度0。
-
递归右子树:对于每个非空节点,递归计算右子树的最小深度。这是为了处理右倾斜二叉树,因为在右倾斜二叉树中,节点的左子树可能为空,而右子树不能为空。
-
处理只有右子树的情况:在右子树的计算过程中,如果发现左子树为空,那么说明该节点只有右子树,此时返回右子树的最小深度加上1。这是为了处理右倾斜二叉树中,只有右子树的情况。
-
处理左右子树都存在的情况:如果左右子树都存在,返回左右子树的最小深度的较小值加上1。这是为了处理普通二叉树的情况。因此,这个递归算法通过适当的处理,可以灵活地应对不同形态的二叉树,包括右倾斜二叉树和普通二叉树。
-
- 右倾斜二叉树示例:
1 \ 2 \ 3 \ 4在这个例子中,每个节点都只有右子节点,形成了一个向右倾斜的结构。这种树的高度等于节点的数量,因为每个节点都沿着右子节点一直向下。
- 混合结构的二叉树:以右倾斜二叉树开头 + 普通二叉树结构:如左图,混合结构二叉树的最小深度为6。使用上述代码计算最小深度时,它将递归计算右倾斜二叉树部分的深度,即节点数为4。然后,它将递归计算二叉树部分的深度,考虑到左右子树的情况,返回左右子树的最小深度的较小值加上 1。同理,右侧为9。


-
左倾斜二叉树
- 为了通过Leetcode 111. Minimum Depth of Binary Tree所有的测试样例,提供能够处理普通二叉树和右倾斜二叉树的最小深度的方案还是不够,还需要能够处理左倾斜二叉树,以及左倾斜二叉树+普通二叉树的混合结构,
- 示例样例如下:root=[1,2]。
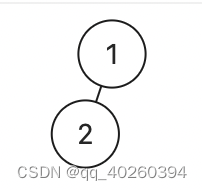
- 为此,我们参照右倾斜二叉树的定义和实现方式,得出来关于左倾斜二叉树的伪代码,如下:
def minDepth(root): # 处理空树的情况 if root is None: return 0 # 递归计算左子树的最小深度 left_depth = minDepth(root.left) # 如果右子树为空,说明只有左子树,返回左子树的最小深度加上1 if root.right is None: return left_depth + 1 # 如果左右子树都存在,返回左右子树最小深度的较小值加上1 return min(left_depth, minDepth(root.right)) + 1
-
整合思路和代码结果
- 将以上思路整合起来,我们能得到一个可以解决以下7??个方面的算法,并且能够解决LeetCode 111题《Minimum Depth of Binary Tree》。
- 普通二叉树
- 右倾斜二叉树
- 左倾斜二叉树
- 右倾斜二叉树开头+普通二叉树的混合结构
- 左倾斜二叉树开头+普通二叉树的混合结构?
- 左倾斜和右倾斜的混合结构
- 左倾斜或右倾斜二叉树开头+普通二叉树树+左倾斜或右倾斜二叉树混合结构
- 将以上代码整合成能求解右倾斜,左倾斜和普通二叉树结构的最小树深度的伪代码如下:整合思路和代码结果:
def minDepth(self, root): # 处理空树的情况 if root is None: return 0 # 递归计算右子树的最小深度 right_depth = self.minDepth(root.right) left_depth = self.minDepth(root.left) # 如果左子树为空,说明只有右子树,返回右子树的最小深度加上1 if root.left is None: return right_depth + 1 # 如果右子树为空,说明只有左子树,返回左子树的最小深度加上1 if root.right is None: return left_depth + 1 # 如果左右子树都存在,返回左右子树最小深度的较小值加上1 return min(left_depth, right_depth)+1 -
时间和空间复杂度
计算二叉树的复杂度涉及两个主要方面:时间复杂度和空间复杂度。这两个复杂度是对算法执行时间和所需内存的度量。
时间复杂度
时间复杂度表示算法执行所需的时间,通常以大O表示法表示。对于二叉树的操作,例如遍历、搜索或修改节点,时间复杂度通常取决于树的高度和节点数量。
在一般情况下:
- 平均时间复杂度: 对于平均情况下的树,可以考虑使用平均深度和平均节点数来估算。
- 最坏时间复杂度: 对于最坏情况下的树,通常考虑树的最大深度和节点数。
例如,对于二叉搜索树(BST),查找一个节点的平均时间复杂度为O(logn), 其中n是节点数。在最坏的情况下,树是不平衡的,时间复杂度可能为O(n),其中n是节点树。
空间复杂度
空间复杂度表示算法执行所需的内存空间,也通常以大O表示法表示。对于二叉树,空间复杂度主要取决于递归调用、栈的使用和其他额外数据结构的空间开销。
-
递归的空间复杂度:在递归遍历二叉树时,递归调用栈的深度影响空间复杂度。平衡二叉树的递归深度通常为O(log n), 而不平衡二叉树的深度可能为O(n)。
-
其他数据结构的空间复杂度:如果在算法执行中使用了其他数据结构(如队列、堆栈等),则需要考虑这些数据结构的空间开销。
综合考虑递归深度、节点数以及其他数据结构的使用,可以得到二叉树的总体空间复杂度。
需要注意的是,二叉树的具体操作和算法会影响复杂度的具体数值。在分析复杂度时,通常使用大 O 表示法来表示算法的渐进复杂度,即在输入规模趋于无穷大时的复杂度。
二叉树中的堆栈
在二叉树的操作和遍历中,堆栈(stack)通常用于以下几种情况:
- 递归(recursive)的实现:二叉树的深度优先搜索(DFS)通常使用递归来实现。递归函数的调用本质上就是使用了堆栈。在递归过程中,每一次递归调用都会将当前状态的信息(比如当前节点、访问过的节点等)压入堆栈,而递归返回时会从堆栈中弹出这些信息,使得递归能够回到上一层。
- 非递归的深度优先搜索:除了递归实现,深度优先搜索也可以使用显示的堆栈来模拟递归过程。在迭代版本的深度优先搜索中,通过维护一个堆栈,可以手动模拟递归调用的过程,将当前状态信息入栈、出栈、实现深度遍历。
- 迭代(iteration)的广度优先搜索:广度优先搜索(BFS)通常使用队列,但有时也可以使用堆栈,特别是在反向遍历的情况下。在迭代的BFS中,每层的节点可以按照逆序压入堆栈,使得出栈的顺序满足反向的BFS要求。
- 中序遍历的非递归实现:在二叉树的中序遍历中的左子树、根节点、右子树的顺序访问。
在这些情况下,堆栈的主要作用是在算法的执行过程中保存状态信息,以便在需要时能够回溯到之前的状态。这对于深度优先搜索、中序遍历等操作是非常有用的。在实际编程中,堆栈的使用可以显示的创建一个堆栈数据结构,也可以使用编程语言自身的调用栈来实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!