吴恩达最新短课,知识很硬核,附中英字幕

吴恩达最新短课,知识很硬核,附中英字幕
简介
大家好我是老章,吴恩达老师忠实粉丝
之前刷过他的很多课程:
最近吴老师又限时免费开放了一个短课:《构建和评估高级 RAG 应用程序》

该课程由由 llama_index 和 truera_ai的 jerryjliu0和 datta_cs 教授主讲,门槛很低,有 Python 基础知识即可学习。
官网没有中文字幕,所以我用ai翻译并重新压制了中英文字幕版上传B站了
https://www.bilibili.com/video/BV1Cu4y1g7gG/

课程主题
本短课预计需要2个小时可以学完,内容包括:
-
学习句子窗口检索等方法。
-
了解评估最佳实践以简化流程,并迭代构建强大的系统。
-
深入研究 RAG 三元组来评估LLM回答的相关性和真实性:上下文相关性、接地性和答案相关性。
-
句子窗口检索和自动合并检索,不仅检索最相关的句子,还检索围绕该句子的句子窗口,以获得更高质量的上下文,将 RAG 管道的性能提高到基线以上。
-
自动合并检索,将文档组织成分层树结构,其中每个父节点的文本在其子节点之间分割。根据子节点与用户查询的相关性,这可以让您更好地决定是否应将整个父节点作为上下文提供给 LLM。
-
用于单独评估 RAG 关键步骤质量(上下文相关性、答案相关性、接地性)的评估方法,以便您可以执行错误分析,确定管道的哪一部分需要工作,并系统地调整组件。
课程配套完整的代码和视频讲解:

RAG是什么?
当前大模型的问题是其训练数据极其广泛,当我们让其完成特定领域的特定问题时,其回答可能存在事实不准确(幻觉)情况。针对特定问题进行微调可以一定程度上解决问题,但是成本高昂。检索增强生成(RAG)应运而生,RAG是为LLM提供来自外部知识源附加信息的概念,这使它们能够生成更准确和更符合上下文的答案,同时减少幻觉。
普通 RAG 工作流程如下图所示:
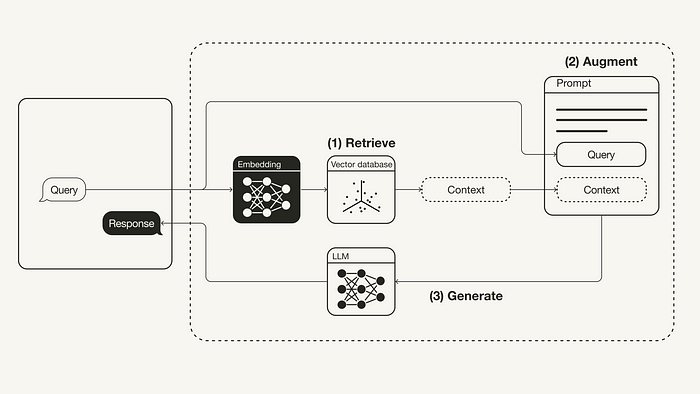
- **检索:**用户查询用于从外部知识源检索相关上下文。为此,使用嵌入模型将用户查询嵌入到与向量数据库中的附加上下文相同的向量空间中。这允许执行相似性搜索,并返回矢量数据库中最接近的前 k 个数据对象。
- **增强:**用户查询和检索到的附加上下文被填充到提示模板中。
- **生成:**最后,检索增强提示被馈送到 LLM。
开发RAG应用有多种技术路线,这个课程使用了OpenAI嵌入模型在 Python 中实现 RAG 管道,使用TruLens做语言模型应用评估,LlamaIndex做编排。四个章节,配套完整代码,一步一步实现RAG 应用程序。
有志于从事大模型开发的同学,学起来吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!