机器学习之K-means聚类
2023-12-29 18:38:18
概念
K-means是一种常用的机器学习算法,用于聚类分析。聚类是一种无监督学习方法,它试图将数据集中的样本划分为具有相似特征的组(簇)。K-means算法的目标是将数据集划分为K个簇,其中每个样本属于与其最近的簇中心。
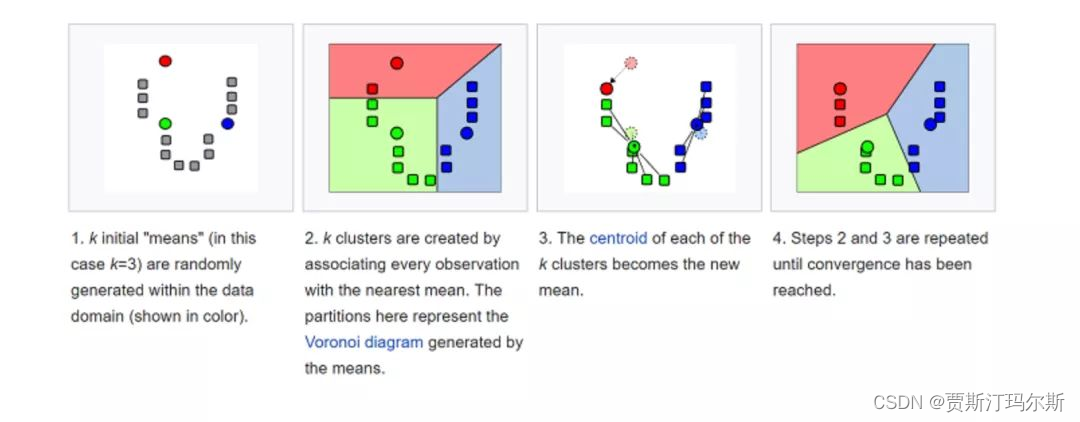
以下是K-means算法的基本步骤:
-
选择簇的数量(K值): 首先,需要选择要分割数据集的簇的数量。这通常需要一些先验知识或者通过尝试不同的K值并评估聚类性能来确定。
-
初始化簇中心: 随机选择K个样本作为初始簇中心,或者使用其他方法初始化。
-
分配样本到最近的簇中心: 对于每个样本,计算其与每个簇中心的距离,并将其分配给最近的簇。
-
更新簇中心: 对于每个簇,计算其成员样本的平均值,并将该平均值作为新的簇中心。
-
重复步骤3和4: 重复执行步骤3和4,直到簇中心不再发生显著变化,或者达到预定的迭代次数。
K-means算法的目标是最小化簇内样本的平方和与簇中心的距离,也就是最小化每个簇内样本到簇中心的平方距离之和。
过程模拟
下面我将为你提供一个简单的K-means算法的模拟过程,以便更好地理解该算法的执行步骤。这是一
文章来源:https://blog.csdn.net/u011095039/article/details/135296309
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!