【Storm实战】1.2 图解Storm的架构及其组件
0. 前言
上一章节,我们为了好理解,将storm中的抽象概念 通过画了一个水力发电系统的工作模式,相信大家一定可以直观地理解Storm中的流 (Stream) 、拓扑 (Topology)、Spout、Bolt、任务(Task)和工作者 (Worker)是如何协同工作处理数据的。
我们将流 (Stream) 比作河流,拓扑 (Topology)想象成是一个水力发电系统,Spout可以视为水力发电系统中的水轮机,它不断从河流(外部数据源)中截取水流。
Bolt就像是沿着水轮机的齿轮和发动机,它们接收从水轮机传来的动力(元组tuple),执行各种操作(处理数据),比如研磨谷物或发电。在Storm中,Bolts可以执行多种数据转换操作,如过滤、聚合、写入数据库等。
任务(Task)可以想象成是工人在水轮机和发电机之间的每个环节上工作。如果这个系统需要处理更多的水流(数据),我们就需要更多的工人(任务)。
在Storm中,增加任务的数量可以提高系统处理数据的能力。工作者 (Worker)看作是整个水力发电系统的工作站或工厂。在这些工作站里,每个工人(任务)负责操作一套齿轮与发动机(执行Spout和Bolt的逻辑)。工厂越多,系统的处理能力就越强。在Storm中,我们可以增加工作者(进程)的数量来扩展拓扑的处理能力。
1. 图解架构及其组件
本章节,我们着重来看下Storm的架构及其组件。还是老样子,我们以类比图解的方式讲解,我画了一个图,

我们想象一下一个水电站系统,这个系统的任务是利用水流来发电。在这个类比中,
Storm的架构及其组件可以借助上面的图这样理解
-
Nimbus(控制中心):这就像是水电站的控制室,负责监控整个系统的运行,确保所有的水轮机(Spout)和发电机(Bolt)正常工作。如果某个设备出了问题,控制中心会及时派出人员去修理或替换。
-
Supervisor(转换站):这就像是电站的变压器,接收来自控制中心的指令并确保电力(任务)送到正确的地点。
-
Worker进程(发电机组):每个Worker就是一个包含多台发电机的发电机组,实际上转动产生电力。在Storm中,Worker进程运行在JVM中,执行实际的处理任务。
-
Task(单独的发电机):每个发电机都是发电机组的一部分,负责生成电力。在Storm中,每个任务都是处理流数据的最小工作单元。
-
Topology(发电网络):整个发电站的电网,确保电力能够从水流经过各种设备最终供到用户。Storm中的拓扑定义了数据流向和处理的逻辑结构。
-
Stream(水流):水电站中的水流就像Storm中流动的数据,水流的动力是发电的来源。
-
Spout(水轮机):水轮机是起始点,它抓住水流的动力并开始转化为电能。在Storm中,Spout从外部数据源捕获数据,生成元组流,是数据流开始的地方。
-
Bolt(发电机):发电机负责接收水轮机的动力并转换成电能。在Storm中,Bolt会处理Spout发送的元组,执行计算操作,可能还会将结果发送到下一个Bolt或存储起来。
通过这个类比,你可以更容易地理解Storm的组件是如何协同工作的,以及它们在数据处理流程中各自扮演的角色。
2. Storm的主要架构组件
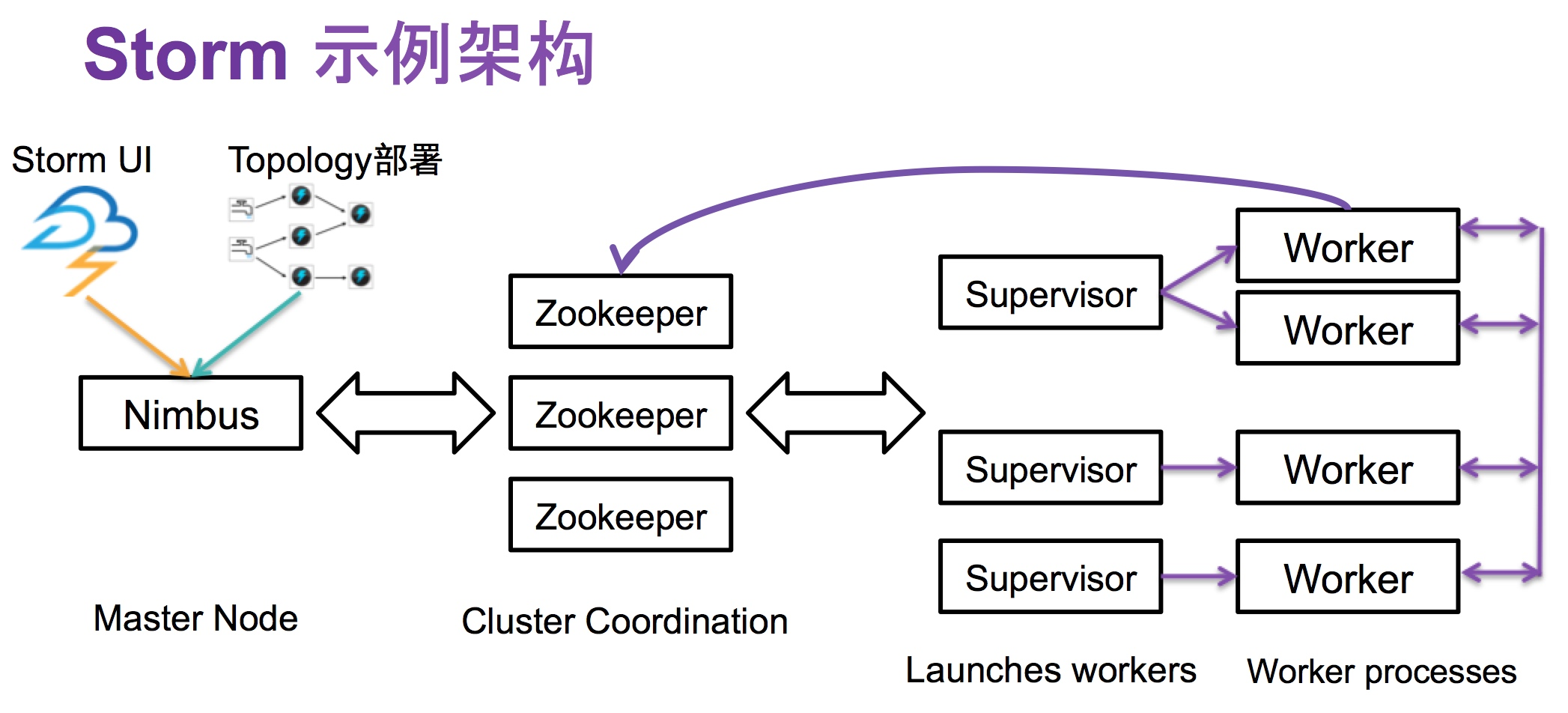
-
Nimbus:这是Storm集群的主节点,负责分发代码,分配任务给Supervisor,监视失败的任务并重新分配。
-
Supervisor:运行在各工作节点上,负责接收从Nimbus分配的任务,然后把任务分配给这个节点的Worker进程。
-
Worker进程:运行在Supervisor节点下,负责执行具体的任务。每个任务都会运行在一个单独的JVM进程中。
-
Task:实际运行的工作单元,一个Worker进程可以运行一个或者多个Task。
-
Topology:Storm中处理逻辑的封装。
-
Stream:数据流,Storm中的主要数据结构,由多个tuple组成。
-
Spout:数据源,负责从数据源获取数据,转换为tuple发送给Bolt。
-
Bolt:数据处理的主要组件,可以接收数据、处理数据以及发送数据。
Storm的架构设计得非常合理,可以适应各种规模的实时处理任务,从而在大数据处理领域得到了广泛应用。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!