python爬虫进阶篇:scrapy爬虫框架的依赖库搭建和项目创建
2023-12-20 07:25:29
一、前言
上篇我们记录了Scrapy的各个组件功能,这篇我们来动手scrapy爬虫框架的依赖库搭建和项目创建,开始进入进阶实战。
二、环境搭建
- 安装依赖库
pip install lxml==4.9.2
pip install parsel==1.6.0
pip install Twisted==21.2.0
pip install pyOpenSSL==19.1.0
pip install cryptography==2.8
pip install Scrapy==1.6.0
以上依赖库是必须要安装的,否则启动Scrapy会报依赖包不存在的错;Scrapy的依赖包对版本要求比较严格,不同版本的依赖包经常会冲突,上面这些依赖包是测试过没有问题的。
三、创建Scrapy项目
- 创建一个爬虫项目文件夹scrapy_demo01
- 命令行进入此文件夹,执行命令:
scrapy startproject scrapy_demo
- 将第一层scrapy_demo文件夹设置为根目录(pycharm中右键此文件夹,Mark directory as Sources Root)

- 创建个spider_main.py文件,用于执行启动爬虫的命令
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl demo_spider".split())
- 最后的项目结构如下
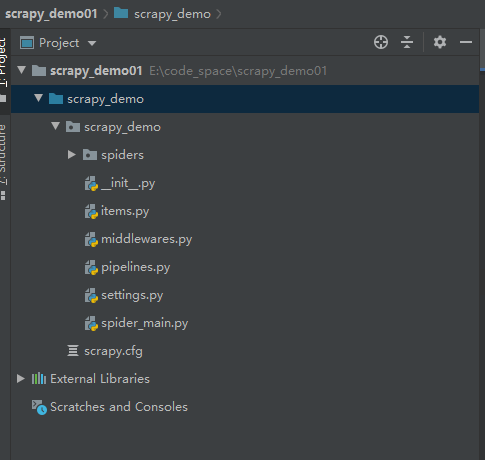
四、测试结果
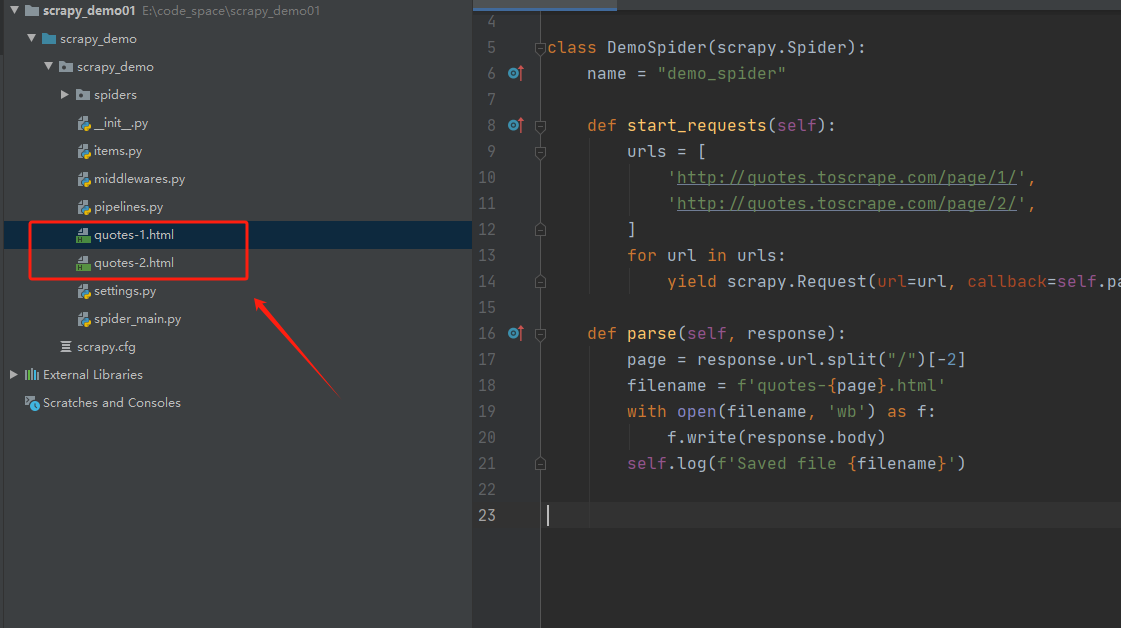
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo_spider"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')
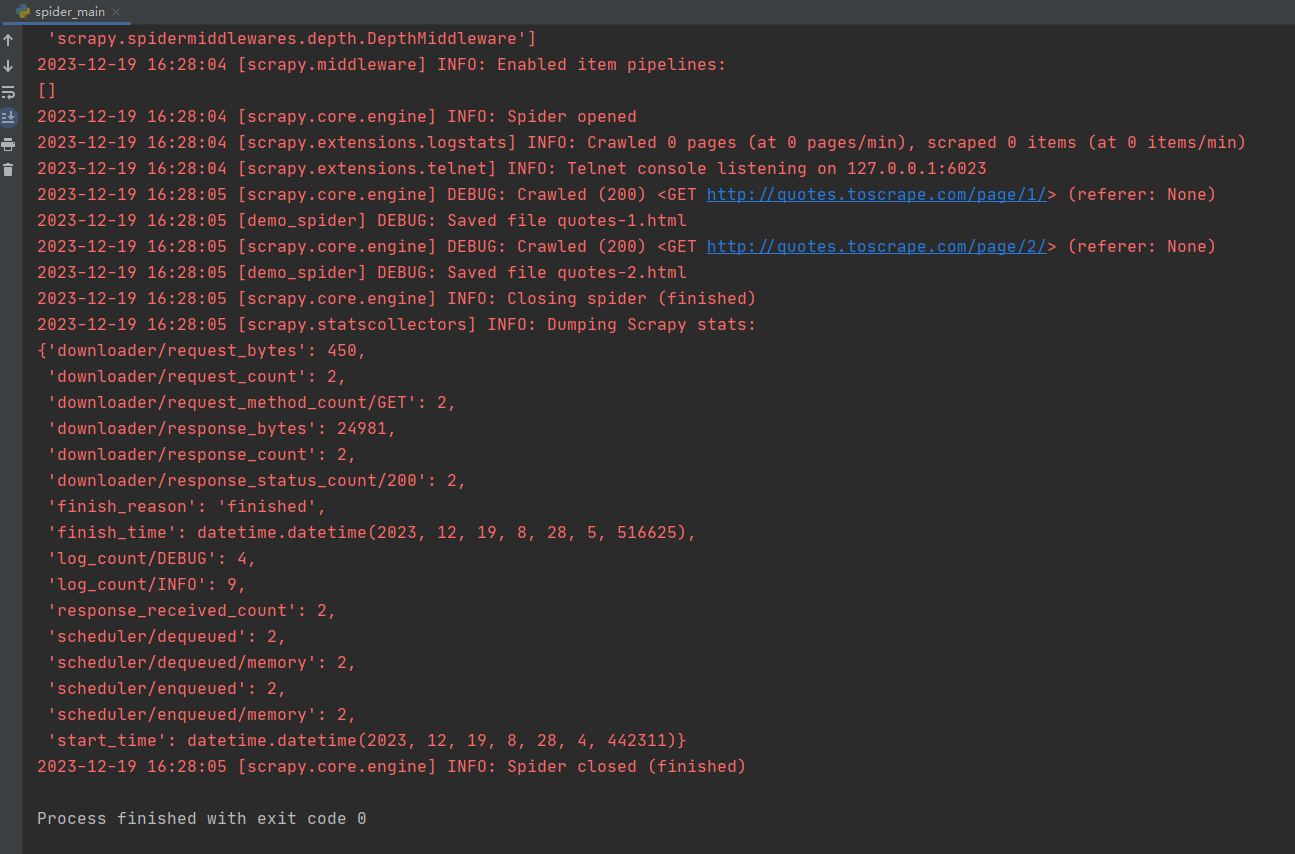
文章来源:https://blog.csdn.net/qq_23730073/article/details/135067499
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!