如何排查线上问题的?
其他系列文章导航
文章目录
前言
在当今的互联网时代,线上问题对企业的业务连续性和用户体验产生的影响越来越大。无论是网站崩溃、应用性能下降,还是服务中断,这些问题都可能对企业的声誉和用户满意度造成严重影响。因此,快速、准确地排查并解决线上问题变得至关重要。
本文将介绍一些高效的线上问题排查方法,帮助您在面对线上问题时,迅速定位并解决问题。我们将在接下来的内容中详细讨论如何利用日志分析、监控系统、代码审查等手段,以及如何制定有效的应急预案。通过这些策略的实施,您将能够提高线上问题的解决速度,减少对业务的影响,并提高用户满意度。
请继续阅读,以了解更多关于如何排查线上问题的详细信息。
本文是链式风格,循序渐进!
一、预警层面
1.1 做好监控告警
如果线上出现了问题,我们更多的是希望由监控告警发现我们出了线上问题,而不是等到业务侧反馈。所以,我们需要对核心接口做好监控告警的功能。
如下图所示:
1.2 定位报警层面?
如果是业务代码层面的监控报警,那我们应该是可以很快地定位出是哪儿的问题,毕竟告警逻辑都是我们写的嘛。如果是服务器资源/所依赖的中间件告警,那我们可能就要花点时间去排查啦。
二、近期版本
2.1 判断最近有没有发版本
不管怎么样,无论是系统告警还是是业务侧反馈系统或者接口出了问题,我们要想想在近期有没有发布过系统,如果近期发布过系统,判断能不能立马回滚到上一个版本,恢复系统平稳正常运行(在线上环境下,可用性是相当重要的)。
回滚的时候要考虑接口有无依赖性,是否需要跟业务侧同步此次的回滚以及做相关的配合。
2.2?回归最近的版本
因为线上大多数的问题都来源于系统的变更,可能我们只是变更了很少的代码,但只要有一丝的逻辑没留意到,就真的很可能会导致出现问题,回滚很可能是最快能恢复线上正常运行的办法。
 ?
?
三、日志告警
3.1?追踪日志
如果近期都没发布过系统,是系统告的警,那追踪下告警和报错日志,应该是可以很快地就能定位出问题。

3.2?业务侧告警
如果不是系统告的警,是业务侧反馈出了问题,那这时候需要业务侧明确是哪个具体的功能/接口出了问题,有没有保留请求入参,有没有返回错误的信息,有何现象。
四、排查经验
4.1 我的经验
知道了问题的现象之后,就需要根据经验排查可能是哪块出了问题了。
我的经验一般是:先查存储侧有没有瓶颈(MySQL 的CPU有没有飙高,主从同步延迟是否很大,有没有慢SQL。Redis是不是内存满了,走了淘汰策略。搜索引擎有没有慢Query),把该服务所依赖的中间件的指标看一遍,这个过程中也要去看看服务接口的QPS/RT相关的监控。
一些相关代码如下:?
检查MySQL的CPU使用情况:
SHOW PROCESSLIST;检查主从同步延迟:
SHOW SLAVE STATUS\G;查找慢SQL:
SHOW FULL PROCESSLIST;检查Redis内存使用情况:
redis-cli info memory;
如果有某项指标不对劲,那顺着写入逻辑也应该很快能看出来。
4.2?定位到问题
一般到这里,大多数的问题都能查出来。可能是逻辑本身的问题,可能是请求入参导致慢查询,可能是中间件的网络抖动,可能是突发或者异常请求的问题。
4.3 走投无路,回归本质
如果都不是,回归到应用和机器本身的监控:应用GC的表现、机器本身的网络/磁盘/内存/CPU 各种的指标有没有发现异常的情况。这里可能是需要运维侧一起配合看看有没有做过改动。
4.4 上大招复现
要是还定位不出来,看能不能复现,能复现都好说,肯定是能解决的。
4.5 日志版debug
要是不能复现,只能在怀疑的地方打上详细的日志再好好观察(问题定位不出来,很多时候就是日志不够详细,而日志在正常情况下也不应该打太多)
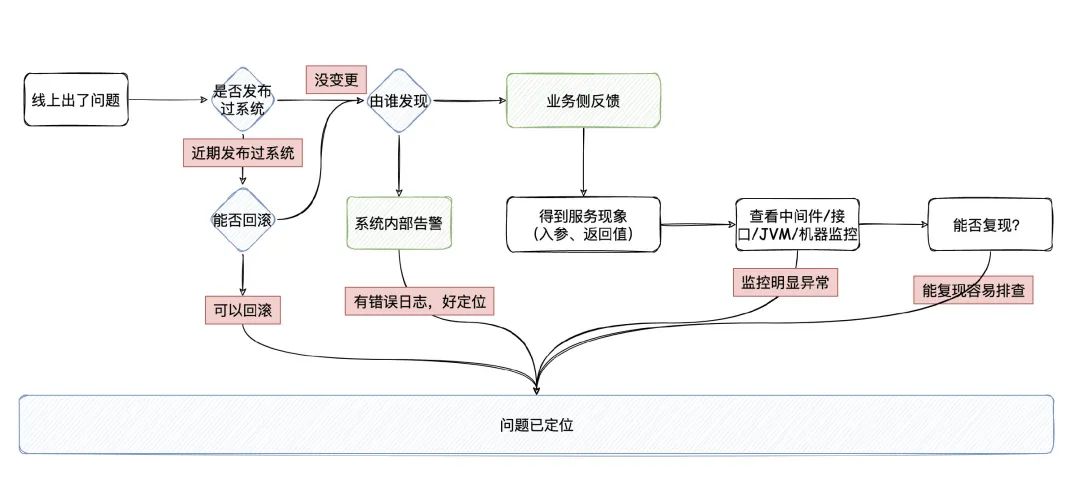
这个我估摸想要考察的是看看你平时是怎么去定位问题的,定位问题的思路是什么,自己有没有方法论之类的。
话虽如此,这也只是我这几年的定位问题的模式,也未必对,也不知道有没有缺少了哪一个重要的环节。
五、总结
线上问题排查是运维人员的重要职责之一,它涉及到对系统性能、稳定性、安全性等方面的监控和排查。通过问题定位、分析、解决和预防等步骤的实践经验总结出一些有效的排查方法。同时需要不断学习和提升自己的技能水平以更好地应对各种线上问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!