集合高级知识点
集合高级
1. HashSet 底层原理
HashSet 的特点:
- HashSet 实现了 Set 接口
- HashSet 底层实质上是 HashMap
- 可以存放 null 值,但是只能有一个 null
- HashSet 不保证元素是有序的,取决于 hash 后,再确定索引的结果,即不保证存放元素的顺序和取出顺序一致
- 不能有重复元素 / 对象
底层机制简述
HashSet 底层是 HashMap,HashMap 底层 Java8 后是(数组 + 链表 + 红黑树)
- 先获取元素的哈希值(hashcode 方法)
- 对哈希值进行运算,得出一个索引值即为要存放在哈希表中的位置号
- 如果该位置上没有其他元素,则直接存放,如果该位置上有其他元素,则需要进行 equals 判断,如果相等,则不再添加,如果不相等,则以链表的方式添加
- Java8 以后,如果一条链表中的元素个数到达 TREEIFY_THRESHOLD(默认是 8),并且 table 的大小 >=MIN_TREEIFY_CAPACITY(默认 64),就会进行数化(红黑树)
注意:详细的底层可以参考 HashMap 部分知识,此处不再赘述。
2. ArrayList 底层原理
ArrayList 是用数组实现的,并且它是动态数组,也就是它的容量是可以自动增长的,看下面的类声明可知它实现了众多接口,比如 List,RandomAccess,Serializable,Cloneable
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable

- 实现 RandomAccess 接口:所以 ArrayList 支持快速随机访问,本质上是通过下标序号随机访问
- 实现 Serializable 接口:使 ArrayList 支持序列化,通过序列化传输
- 实现 Cloneable 接口:使 ArrayList 能够克隆
下面通过底层代码分析,看看 ArrayList 是如何工作的。
2.1 初始化数据
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;// 默认容量
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};// 空数组
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // ArrayList 底层本质上是一个数组,用该数组来保存数据。
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;// 数组大小

2.2 构造方法
/**
* 默认构造方法,构造一个初始容量为 0 的列表
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个具有指定初始容量的空列表
*/
public ArrayList(int initialCapacity) {
if (initialCapacity> 0) {
// 如果初始化容量大于零,则新建一个数组容量为 initialCapacity
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 如果初始化容量等于零,则新建一个数组容量为空
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 小于零时报异常
throw new IllegalArgumentException("Illegal Capacity:"+
initialCapacity);
}
}
/**
* 创建一个包含 collection 的 ArrayList,返回的元素是按照该 collection 的迭代器在返回它们的顺序排列的 * (具体是在 Collection 的 toArray() 方法中)
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 如果数组长度不等于 0(就是有数据)
if (elementData.getClass() != Object[].class)
// 复制 elementData 数组,截取或用 null 填充(如有必要),以使副本具有指定的长度,并返回 Object[] 类
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}

2.3 扩容方法
ArrayList 每次新增元素都会进行容量大小检测判断,若新增的后元素的个数会超过 ArrayList 的容量,就会进行扩容满足新增元素的需求。
// 扩容方法
public void ensureCapacity(int minCapacity) {
// 默认构造情况下,elementData 是空的,所以 minExpand 为 10
int minExpand = (elementData != EMPTY_ELEMENTDATA) ? 0 : DEFAULT_CAPACITY;
if (minCapacity> minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureExplicitCapacity(int minCapacity) {
/** 数据结构发生改变,和 fail-fast 机制有关,在使用迭代器过程中,只能通过迭代器的方法(比如迭代器中 * add,remove 等),修改 List 的数据结构,如果使用 List 的方法(比如 List 中的 add,remove等), * 修改 List 的数据结构,会抛出 ConcurrentModificationException
*/
modCount++;
if (minCapacity - elementData.length> 0)
// 当前数组容量大小不足时,才会调用 grow 方法,自动扩容
grow(minCapacity);
}

问:这里为什么不直接判断是否需要扩容,而是使用 modCount 进行辅助进行二次判断呢?
答:是因为?fail-fast 机制。
实际上扩容的方法 grow()
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 新的容量大小 = 原容量大小的 1.5 倍,右移 1 位并相加本身近似于 1.5 倍
int newCapacity = oldCapacity + (oldCapacity>> 1);
if (newCapacity - minCapacity < 0)
// 溢出判断
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE> 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}

为什么选择 1.5 倍?**因为一次性扩容太大 (例如 2.5 倍) 可能会浪费更多的内存 **
1.5 倍:最多浪费 33% 2.5 倍:最多会浪费 60% 3.5 倍:则会浪费 71%
但是一次性扩容太小,需要多次对数组重新分配内存,对性能消耗比较严重。所以 1.5 倍刚刚好,既能满足性能需求,也不会造成很大的内存消耗。
3. Vector 底层原理
Vector 作为 List 的另外一个典型实现类,完全支持 List 的全部功能,Vector 类也封装了一个动态的,允许在分配的 Object[] 数组,Vector 是一个比较古老的集合,Java1.0 就已经存在,建议尽量不要使用这个集合,替代方案:可以使用 Collections.synchronizedList();得到一个线程安全的 ArrayList。
**初始化数据 **
protected Object[] elementData; // 存放元素的数组
protected int elementCount; // 已经放入数组的元素个数
protected int capacityIncrement; // 数组的增长系数

构造方法
// 构造方法,提供初始大小,和增长系数
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity:"+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
// 构造方法,提供初始大小,增长系数为零
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
// 无参构造方法
public Vector() {
this(10);
}
// 构造方法,将指定的集合元素转化为 Vector
public Vector(Collection<? extends E> c) {
elementData = c.toArray();
elementCount = elementData.length;
// 判断 c.toArray 是否是 Object[] 类型
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}

可以看出同 ArrayList 不同,Vector 可以提供增长系数。
扩容方法
// 扩充容量
public synchronized void ensureCapacity(int minCapacity) {
if (minCapacity> 0) {
modCount++;
ensureCapacityHelper(minCapacity);
}
}
// 扩充容量帮助函数
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length> 0)
grow(minCapacity);
}
// 最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 扩充容量执行方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 根据 capacityIncrement 进行判断,capacityIncrement> 0 增加 capacityIncrement 个容量,否则容量扩充当前容量的一倍
int newCapacity = oldCapacity + ((capacityIncrement> 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE> 0)
newCapacity = hugeCapacity(minCapacity);
// 扩容操作,生成已给新的数组,容量为 newCapacity, 并将 elementData 中的元素全部拷贝到新数组中,并将新生成的数组在赋值给 elementData
elementData = Arrays.copyOf(elementData, newCapacity);
}

通过上面的代码可以看出,若是指定了扩容系数则按增长系数扩容,若是没有指定则 2 倍扩容。
其他方法
// 得到索引为 index 的元素
public synchronized E get(int index) {
if (index>= elementCount)
throw new ArrayIndexOutOfBoundsException(index);
return elementData(index);
}
// 设置 index 位置的元素为 element
public synchronized E set(int index, E element) {
// 省略...
}
// 添加方法
public synchronized boolean add(E e) {
// 省略...
}

可以看到所有的操作方法都添加了 synchronized 关键字,表示这些方法都是线程安全的。
**Vectory 和 ArrayList 的区别 **:
- Vector 是同步的,因此开销就比 ArrayList 大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制。
- Vector 每次扩容为其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
- Vector 提供构造方法可以设置扩容系数,ArrayList 则不可以。
4. HashMap 底层原理
HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap 最多只允许一条记录的键为 null,允许多条记录的值为 null。
HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
4.1 Java7 实现(数组 + 链表)
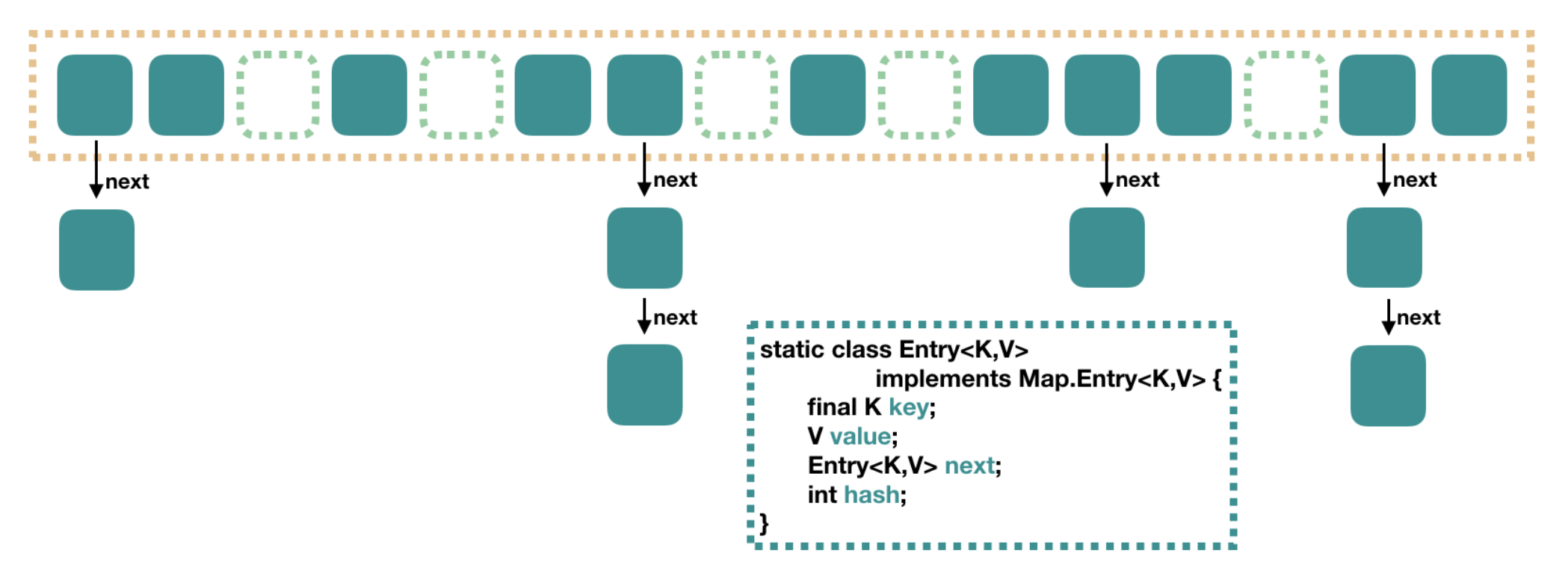
从上图可以看出,在 Java7 中 HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
- capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
- loadFactor:负载因子,默认为 0.75。
- threshold:扩容的阈值,等于 capacity * loadFactor
4.1.1 负载因子详解
有序数组存储数据,对数据的索引效率都很高,但是插入和删除就会有性能瓶颈(回忆 ArrayList),链表存储数据,要依次比较元素来检索出数据,所以索引效率低,但是插入和删除效率高(回忆 LinkedList),两者取长补短就产生了哈希散列这种存储方式,也就是 HashMap 的存储逻辑。
HashMap 的底层结构是哈希表 ,是以键值对形式存储的。在向 HashMap 存放数据的过程中,首先会通过 hash() 方法计算出哈希值才能知道数据要存储在哈希表中的某个位置。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}

*但是这样的存储有问题
存储数据时先通过哈希算法计算出要存储的位置,但是有可能该位置已经有数据存储了,这时候就会产生哈希冲突的问题。如果为了避免哈希冲突,而增大数组容量来减少哈希冲突问题,有可能会导致数组空间浪费或者空间过小的问题。而负载因子就是决定 HashMap 的数据密度。
公式:初识化容量(initailCapacity)* 负载因子(loadFactor)= HashMap 的容量。
HashMap 有三个构造函数,可以选用有参构造函数设置初始化容量和负载因子。官方的建议是 initailCapacity 设置成 2 的 n 次幂,laodFactor 根据业务需求,如果迭代性能不是很重要,可以设置大一些。
也可以选用无参构造函数,不进行设置,此时会使用默认值,分别是 16 和 0.75。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;

4.2 Java8 实现(数组 + 链表 + 红黑树)

从上图可以看出,Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由?数组 + 链表 + 红黑树?组成。
根据 Java7 HashMap 的讲解可以知道,HashMap 在查找数据的时候,根据 hash 值我们能够快速定位到数组的 具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到需要的数据,这样时间复杂度就取决于链表的长度,为 O(n)。
为了降低这部分的开销,在 Java8 中,当链表中的?元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
总结一下就是:链表取元素是从头结点一直遍历到对应的结点,时间复杂度是 O(N) ,红黑树基于二叉树结构,时间复杂度为 O(logN) ,所以当元素个数过多时,用红黑树存储可以提高搜索的效率。但是单个树节点需要占用的空间大约是普通节点的两倍,所以使用树和链表是时空权衡的结果。
4.2.1 树化详解
下面通过 HashMap 的源代码来分析一下:

这里三个值分别代表:树化阈值 = 8 ,反树化阈值 = 6,hash 表中最小数据值 = 64。

由这段代码可以看出,当链表长度大于 TREEIFY_THRESHOLD = 8 时,会进行树化。
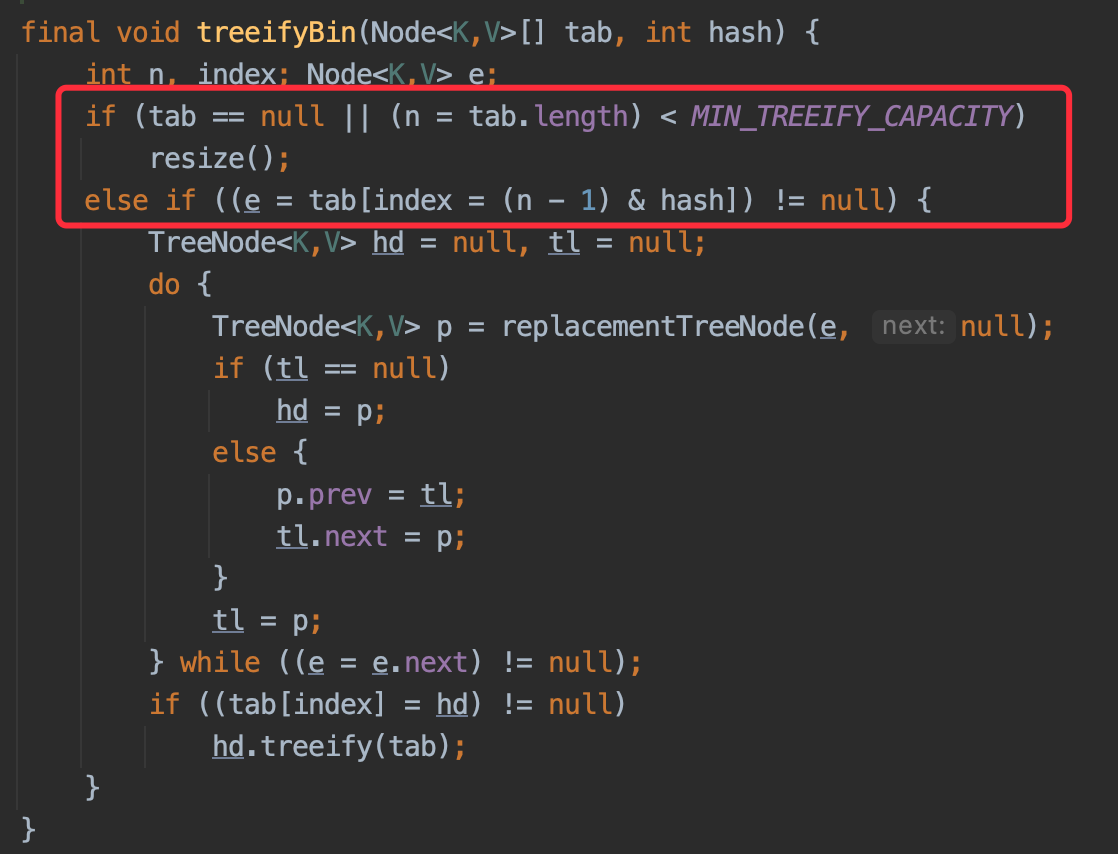
这里可以看出,当进行树化操作时的第一个判断就是哈希数组的容量是否大于 MIN_TREEIFY_CAPACITY = 64,如果小于,进行扩容操作,而不是树化操作。
所以综上所述,HashMap 进行树化的条件其实有两个:
- 链表长度大于 TREEIFY_THRESHOLD
- 哈希数组的长度大于 MIN_TREEIFY_CAPACITY
4.2.2 树化阀值为什么是 8
HashMap 文档有这么一段描述。大体意思是,哈希桶上的链表节点数量呈现?泊松分布。
Ideally, under random hashCodes, the frequency of?> ** nodes in bins follows a Poisson distribution* > ** (http://en.wikipedia.org/wiki/Poisson_distribution) with a* > ** parameter of about 0.5 on average for the default resizing* > ** threshold of 0.75, although with a large variance because of* > ** resizing granularity. Ignoring variance, the expected* > ** occurrences of list size k are (exp(-0.5) * pow(0.5, k) /* *_ factorial(k)). The first values are:_
** 0: 0.60653066* > ** 1: 0.30326533* > ** 2: 0.07581633* > ** 3: 0.01263606* > ** 4: 0.00157952* > ** 5: 0.00015795* > ** 6: 0.00001316* > ** 7: 0.00000094* > ** 8: 0.00000006* *_ more: less than 1 in ten million_
什么是?泊松分布?
泊松分布就是描述某段时间内,事件具体的发生概率。柏松分布可以通过平均数估算出某个事件的出现概率。公式如下,此处对泊松分布不做详解,有兴趣的同学自行百度。

HashMap 默认负载因子为 0.75,所以每个桶的平均节点数量 0.5,代入柏松公式得到下面数据。
1 个桶中出现 1 个节点的概率: 0.3032653299 1 个桶中出现 2 个节点的概率: 0.0758163325 1 个桶中出现 3 个节点的概率: 0.0126360554 1 个桶中出现 4 个节点的概率: 0.0015795069 1 个桶中出现 5 个节点的概率: 0.0001579507 1 个桶中出现 6 个节点的概率: 0.0000131626 1 个桶中出现 7 个节点的概率: 0.0000009402 1 个桶中出现 8 个节点的概率: 0.0000000588
可以发现这就是 HashMap 官方给的描述数据。
树化?是哈希极度糟糕下不得已而为之的做法,官方将 TREEIFY_THRESHOLD = 8,此时一个链表中出现 8 个节点的概率不到千万分之一,概率已经非常低了,此时树化性价比会很高。既不会因为链表太长(8)导致复杂度加大,也不会因为概率太高导致太多节点树化。
5. ConcurrentHashMap 底层原理
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表 ” 部分 “ 或 ” 一段 “的意思,所以很多地方都会将其描述为分段锁。注意:很多地方用了“槽” 来代表一个 Segment。
线程安全:因为 Segment 继承 ReentrantLock 加锁
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
5.1 Java7 实现
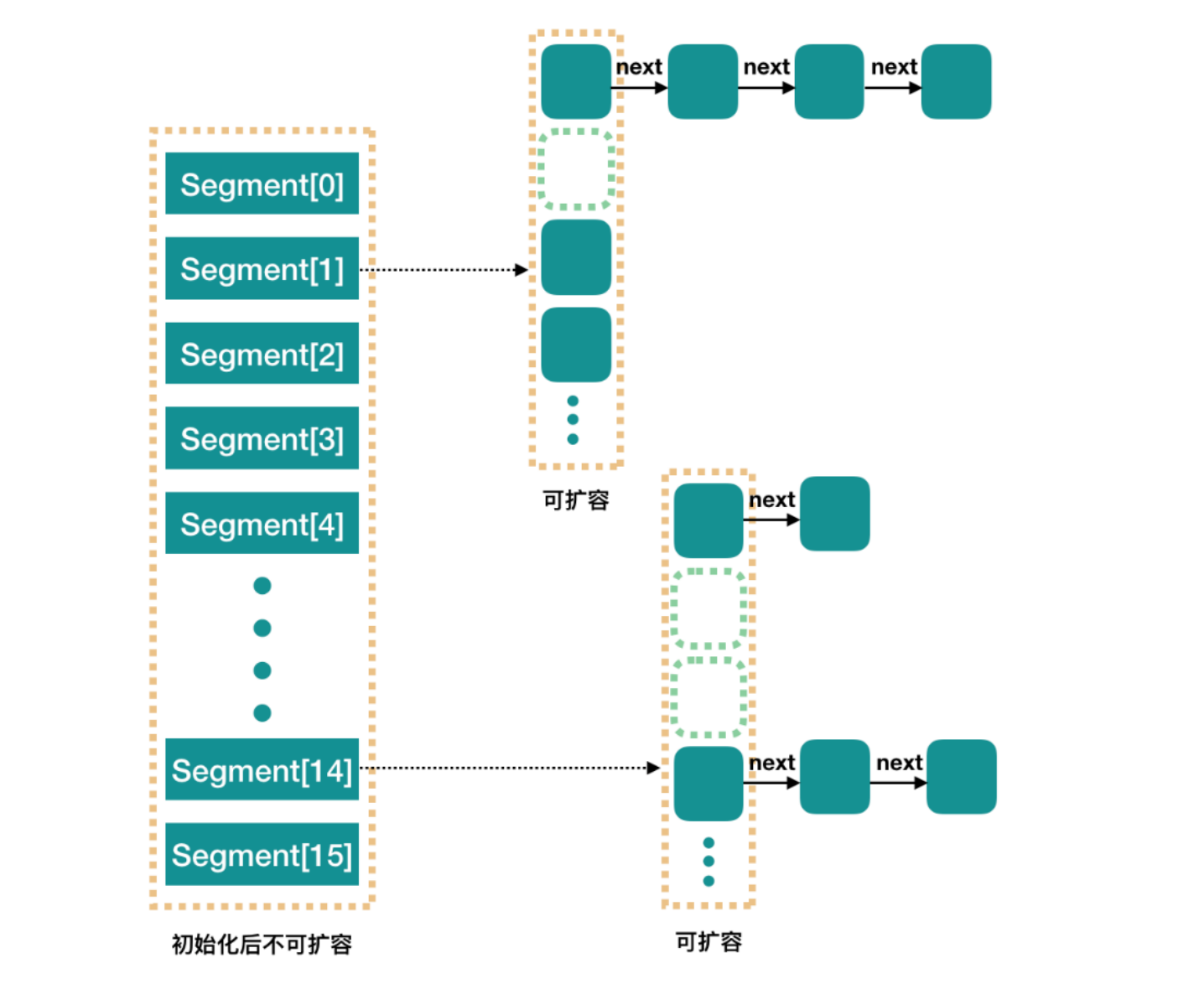
concurrencyLevel:并行级别、并发数、Segment 数,怎么翻译不重要。默认值是 16,也就是说?ConcurrentHashMap 有 16 个 Segments,所以理论上最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。
这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
5.1 Java8 实现
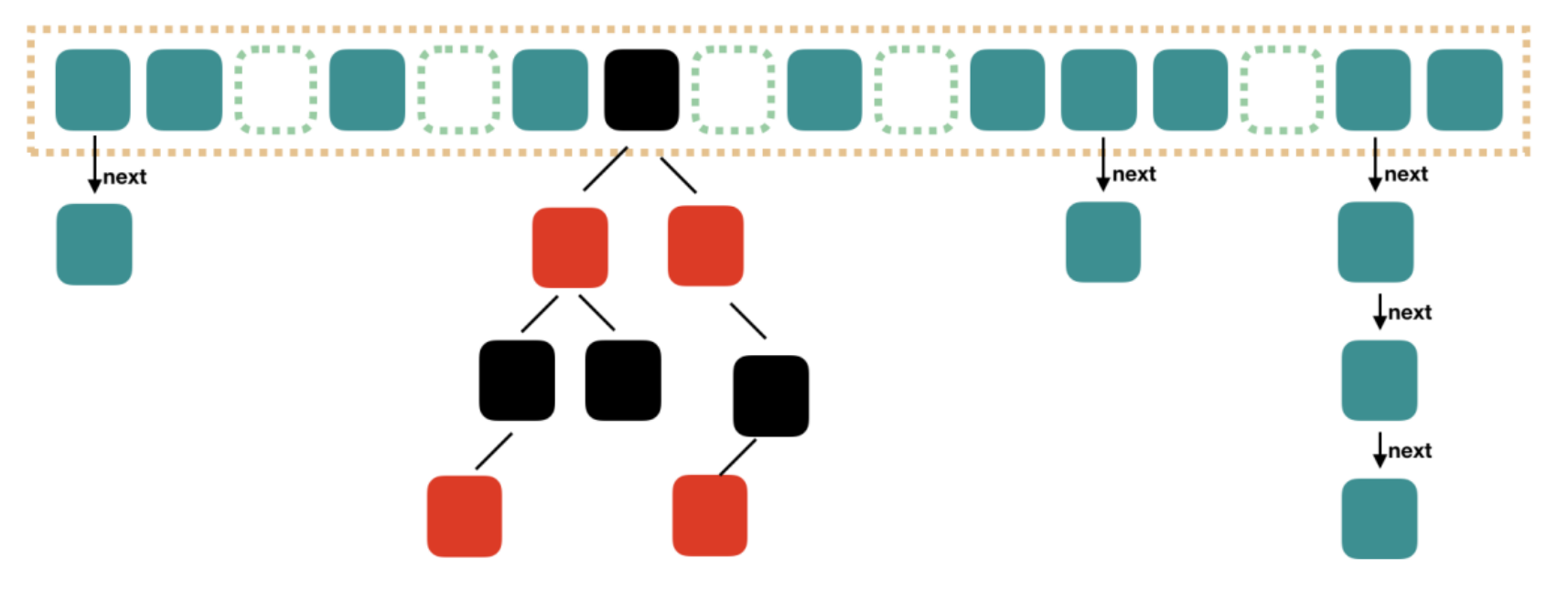
如上图所示,Java8 对 ConcurrentHashMap 进行了比较大的改动,Java8 也引入了红黑树。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!