【机器学习基础】支持向量机
🚀个人主页:为梦而生~ 关注我一起学习吧!
💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学!
?特别提醒:针对机器学习,特别开始专栏:机器学习python实战 欢迎订阅!本专栏针对机器学习基础专栏的理论知识,利用python代码进行实际展示,真正做到从基础到实战!
💡往期推荐:
【机器学习基础】机器学习入门(1)
【机器学习基础】机器学习入门(2)
【机器学习基础】机器学习的基本术语
【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式)
【机器学习基础】一元线性回归(适合初学者的保姆级文章)
【机器学习基础】多元线性回归(适合初学者的保姆级文章)
【机器学习基础】对数几率回归(logistic回归)
【机器学习基础】正则化
【机器学习基础】决策树(Decision Tree)
【机器学习基础】K-Means聚类算法
【机器学习基础】DBSCAN
💡本期内容:支持向量机(Support Vector Machine,SVM)是一种按监督学习方式对数据进行二元分类的广义线性分类器。其决策边界是对学习样本求解的最大边距超平面。SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器。SVM可以通过核方法进行非线性分类,是常见的核学习方法之一。
文章目录
1 间隔与支持向量
1.1 回顾线性模型
- 在样本空间中寻找一个超平面, 将不同类别的样本分开

- 将训练样本分开的超平面可能有很多, 哪一个好呢?

- 应选择”正中间”, 容忍性好, 鲁棒性高, 泛化能力最强
1.2 超平面方程

- 为什么上述分类问题都可以表示成上图的形式呢?
任意超平面可以用下面这个线性方程来描述:

二维空间点 (𝑥, 𝑦)到直线 𝐴𝑥 + 𝐵𝑦 + 𝐶 = 0的距离公式是:

扩展到 𝑛 维空间后,点 𝑥 = (𝑥1, 𝑥2 … 𝑥𝑛) 到超平面𝑤𝑇𝑥 + 𝑏 = 0 的距离为
其中


如图所示,根据支持向量的定义我们知道,支持向量到超平面的距离为 𝑑,其他点到超平面的距离大于 𝑑。
每个支持向量到超平面的距离可以写为:

2 对偶问题
2.1 最大间隔
假设两个隔离边缘平面分别为

- 最大间隔: 寻找参数 ω \omega ω和 b b b, 使得 γ \gamma γ最大.

这里可以思考一下它的几何意义是什么
2.2 拉格朗日乘子法
在支持向量机(SVM)中,拉格朗日乘子法主要用于解决约束优化问题。其基本思想是通过引入拉格朗日乘子,将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。
拉格朗日乘数背后的数学意义是约束方程梯度线性组合中每个向量的系数。具体来说,在SVM中,我们使用拉格朗日乘子法来解决优化问题。通过引入拉格朗日乘子,将原始问题转化为一个对偶问题,然后通过求解对偶问题得到原始问题的最优解。
- 第一步:引入拉格朗日乘子
α
i
≥
0
\alpha_i\geq0
αi?≥0得到拉格朗日函数

- 第二步:令
L
(
ω
,
b
,
α
)
L(\omega,b,\alpha)
L(ω,b,α)对
ω
\omega
ω和
b
b
b的偏导为零可得

- 第三步:回代


再把max问题转成min问题:

得到最优解
解出后,代入超平面模型也就是:

以上为SVM对偶问题的对偶形式
2.3 解的稀疏性
最终模型:

KKT条件:

支持向量机解的稀疏性: 训练完成后, 大部分的训练样本都不需保留, 最终模型仅与支持向量有关
- 求解方法 - SMO
基本思路:不断执行如下两个步骤直至收敛
- 第一步:选取一对需更新的变量 α i \alpha_i αi?和 α j \alpha_j αj?.
- 第二步:固定 α i \alpha_i αi?和 α j \alpha_j αj?以外的参数, 求解对偶问题更新 α i \alpha_i αi?和 α j \alpha_j αj?.
仅考虑
α
i
\alpha_i
αi?和
α
j
\alpha_j
αj?时, 对偶问题的约束变为
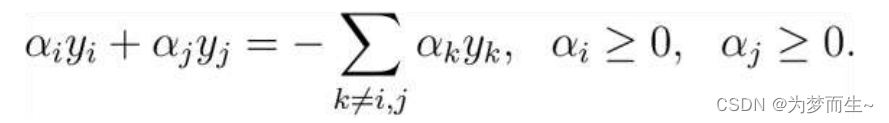
用一个变量表示另一个变量, 回代入对偶问题可得一个单变量的二次规划, 该问题具有闭式解.
偏移项 :通过支持向量来确定 b b b
3 核函数
3.1 线性不可分
- 若不存在一个能正确划分两类样本的超平面, 怎么办?

答:将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特征空间内线性可分.
- 核技巧
在低维空间计算获得高维空间的计算结果,满足高维,才能在高维下线性可分。 我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行,即用核函数来替换当中的内积。

- 用核函数来替换原来的内积

即通过一个非线性转换后的两个样本间的内积。具体地,𝐾(𝑥, 𝑧)是一个核函数,或正定核,意味着存在一个从输入空间到特征空间的映射,对于任意空间输入的𝑥, 𝑧 有:

3.2 核支持向量机
设样本
x
x
x映射后的向量为
?
(
x
)
\phi(x)
?(x), 划分超平面为

原始问题:

对偶问题:

预测:

3.3 核函数
基本想法:不显式地设计核映射, 而是设计核函数

Mercer定理(充分非必要):只要一个对称函数所对应的核矩阵半正定, 则它就能作为核函数来使用
- 常用核函数:

4 软间隔与正则化
现实中, 很难确定合适的核函数使得训练样本在特征空间中线性可分; 同时一个线性可分的结果也很难断定是否是有过拟合造成的.

引入”软间隔”的概念, 允许支持向量机在一些样本上不满足约束
4.1 0/1损失函数
基本想法:最大化间隔的同时, 让不满足约束的样本应尽可能少

其中
l
0
/
1
l_{0/1}
l0/1?是”0/1损失函数”

存在的问题:0/1损失函数非凸、非连续, 不易优化!
替代损失:
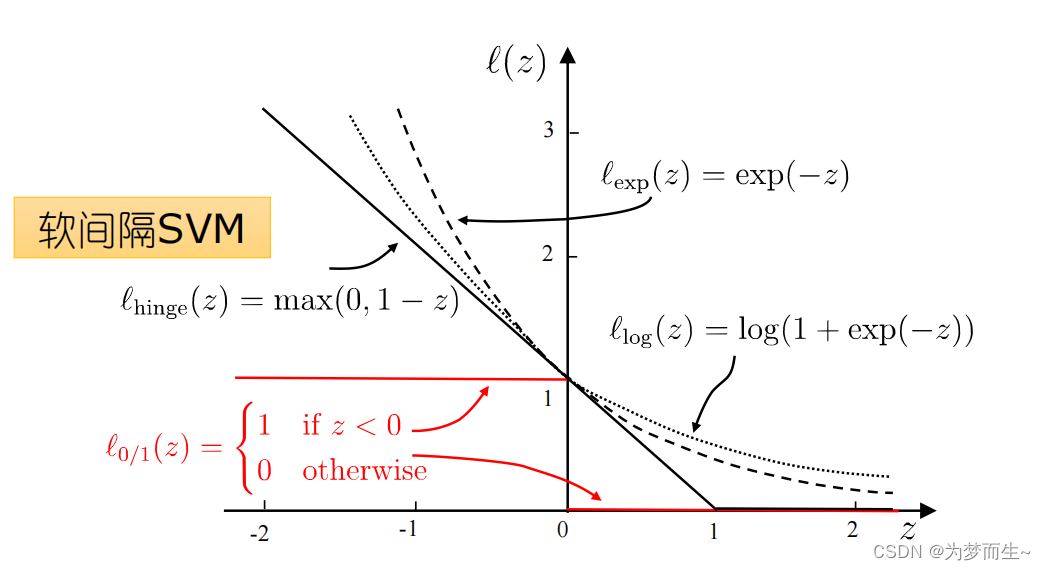
替代损失函数数学性质较好, 一般是0/1损失函数的上界
原始问题:

对偶问题:

根据KKT条件可推得最终模型仅与支持向量有关, 也即hinge损失函数依然保持了支持向量机解的稀疏性.
4.2 软间隔支持向量机
若数据线性不可分,则可以引入松弛变量 𝜉 ≥ 0 ,使函数间隔加上松弛变量大于等于1 ,
则目标函数:

对偶问题:

𝐶为惩罚参数, 𝐶 值越大 ,对分类的惩罚越大。跟线性可分求解的思路一致,同样这里先用拉格朗日乘子法得到拉格朗日函数,再求其对偶问题。

4.3 正则化
支持向量机学习模型的更一般形式:

通过替换上面两个部分, 可以得到许多其他学习模型
- 对数几率回归(Logistic Regression)
- 最小绝对收缩选择算子(LASSO)
5 支持向量回归
模型特点: 允许模型输出和实际输出间存在
2
?
2\epsilon
2?的偏差

损失函数:
落入中间
2
?
2\epsilon
2?间隔带的样本不计算损失, 从而使得模型获得稀疏性.

原始问题:

对偶问题:

预测:

6 核方法
6.1 表示定理
支持向量机:

支持向量回归:

- 结论:
无论是支持向量机还是支持向量回归, 学得的模型总可以表示成核函数的线性组合
更一般的结论(表示定理): 对于任意单调增函数
Ω
\Omega
Ω和任意非负损失函数
l
l
l, 优化问题

的解总可以写为:

6.2 核线性判别分析
通过表示定理可以得到很多线性模型的”核化”版本
- 核LDA:
先将样本映射到高维特征空间, 然后在此特征空间中做线性判别分析
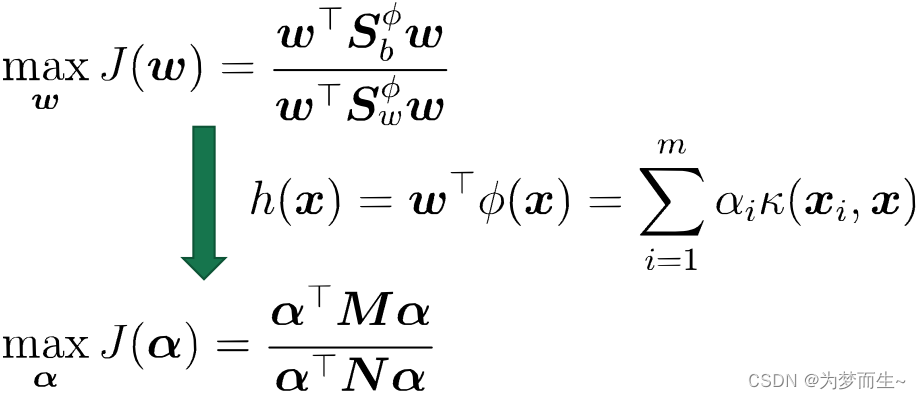
7 成熟的SVM软件包
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!