机器学习实践
1.波士顿房价预测
????????波士顿房屋的数据于1978年开始统计,共506个数据点,涵盖了波士顿不同郊区房屋的14种特征信息。
????????在这里,选取房屋价格(MEDV)、每个房屋的房间数量(RM)两个变量进行回归,其中房屋价格为目标变量,每个房屋的房间数量为特征变量。将数据导入进来,并进行初步分析。
1.1 数据集解析
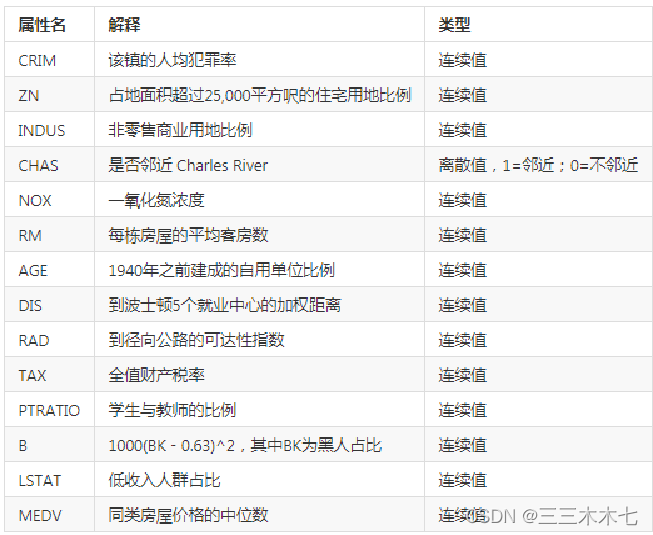
数据集共506行,每行14列
前13列用来描述房屋的各种信息 ,最后一列为该类房屋价格中位数
1.2 流程
准备数据→配置网络→训练网络→模型评估→模型预测?
训练网络:
1. ?网络正向传播计算网络输出和损失函数。
2. ?根据损失函数进行反向误差传播,将网络误差从输出层依次向前传递, 并更新网络中的参数。
3. ?重复1~2步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
1.3 代码
🍄准备数据集
🍥导入数据并查看
# 导入数据并做相关转换
import matplotlib.pyplot as plt #导入matplotlib库
import numpy as np #导入numpy库
import pandas as pd #导入pandas库
from sklearn.datasets import load_boston #从sklearn数据集库导入boston数据
boston=load_boston() #将读取的房价数据存储在boston变量中
print(boston.keys()) #打印boston包含元素
print(boston.feature_names) #打印boston变量名
在波士顿房屋价格数据集中,data即为特征变量,target为目标变量,选取data中的RM、target中的MEDV变量进行单变量线性回归。
【其中房屋价格为目标变量,每个房屋的房间数量为特征变量。】
🍥简单查看一下数据
# data特征变量的前五行数据
bos = pd.DataFrame(boston.data) #将data转换为DataFrame格式以方便展示
print(bos.head()) #一共五行数据,该代码是输出每行数据
print(bos) #输出全部数据,共有505行每一行有13列
print (bos[5].head()) #data的第6列数据为RM 这个代码是输出每一行的下标为5的数据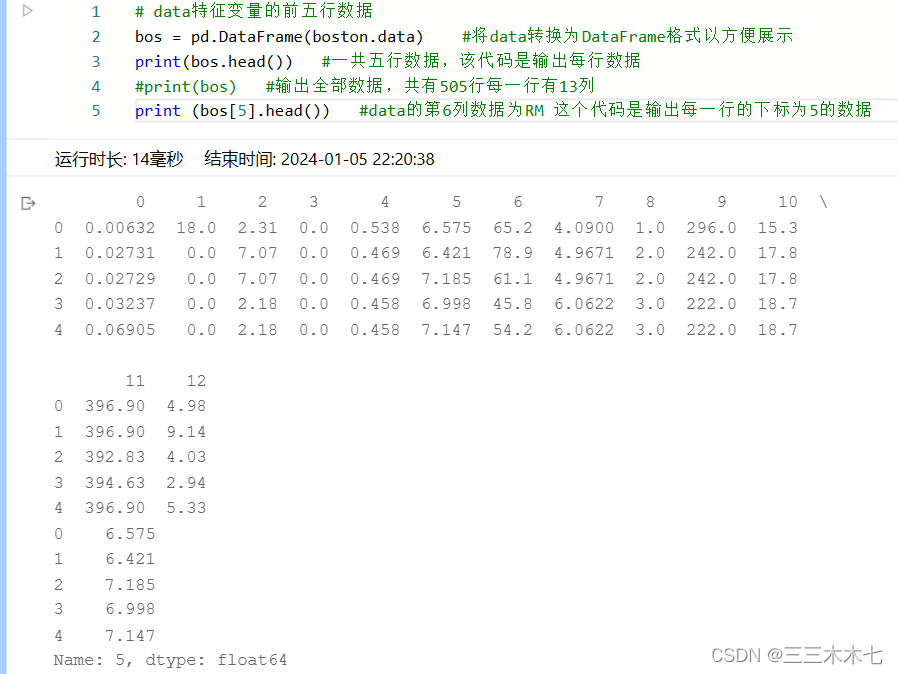
# 把target打印出来
bos_target = pd.DataFrame(boston.target) #将target转换为DataFrame格式以方便展示 前5组的target
print(bos_target)
print(bos_target.head()) #head函数是取前5个
🍥绘制房屋价格(MEDV)、每个房屋的房间数量(RM)的散点图。
# 绘制房屋价格(MEDV)、每个房屋的房间数量(RM)的散点图
X = bos.iloc[:,5:6] #选取data中的RM变量
print(X.head()) #每一组数据的第6列数据,也就是每组数据的RM值
y = bos_target #设定target为y
print(y.head()) #每一组数据的target值
plt.scatter(X, y) #绘制散点图
plt.xlabel(u'RM') #x轴标签
plt.ylabel(u'MEDV') #y轴标签
plt.title(u'The relation of RM and PRICE') #标题
plt.show()
通过散点图可以看出,房屋价格(MEDV)、每个房屋的房间数量(RM)存在着一定的线性变化趋势,即每个房屋的房间数量越多,房屋价格越高。
下面就可以用单变量线性回归算法进一步进行拟合与预测。
🍄数据集划分
数据集的划分可以采用Scikit-learn库中的model-selection程序包来实现。
# 数据集划分
from sklearn.model_selection import train_test_split #导入数据划分包
# 把X、y转化为数组形式,以便于计算
X = np.array(X)
y = np.array(y)
# 以25%的数据构建测试样本,剩余作为训练样本
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25)
X_train.shape,X_test.shape,y_train.shape,y_test.shape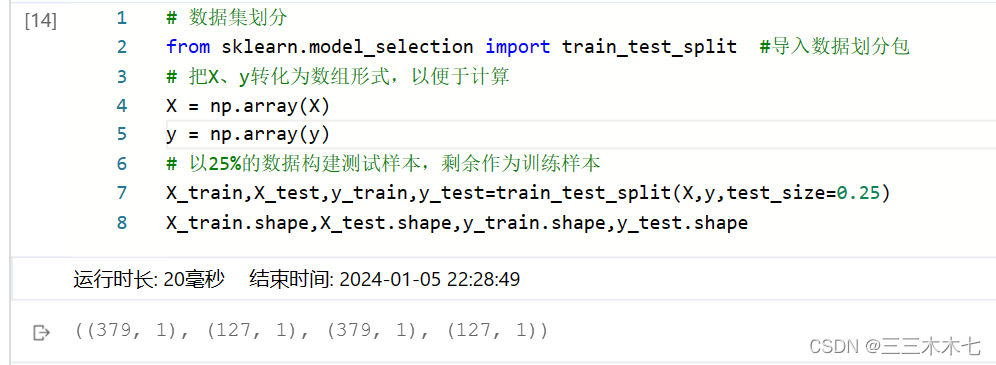
🍄模型训练
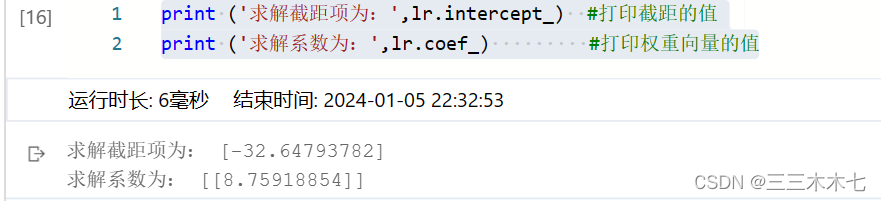
from sklearn.linear_model import LinearRegression #使用LinearRegression库
lr=LinearRegression() #设定回归算法
lr.fit(X_train,y_train) #使用训练数据进行参数求解
print ('求解截距项为:',lr.intercept_) #打印截距的值
print ('求解系数为:',lr.coef_) #打印权重向量的值
输出的是LinearRegreesion()中的相关参数的设置。
fit_intercept:表示是否对训练数据进行中心化,若为false,则表示输入的数据已经进行了中心化处理,下面的过程里将不需要在进行中心化处理。
normalize:默认为False,表示是否对数据进行标准化处理。
copy_X:默认为True,表示是否对X复制。如果选择False,则直接对原数据进行覆盖,即经过中心化、标准化后,是否把新数据覆盖到原数据上。
n_jobs:默认为1,表示计算时设置的任务个数。如果选择-1,则代表使用所有的CPU。
🍄模型预测?
基于对参数的求解结果,对测试集进行预测。

🍄模型评估?
对拟合与预测结果进行效果评价,以判断求解结果是否良好。
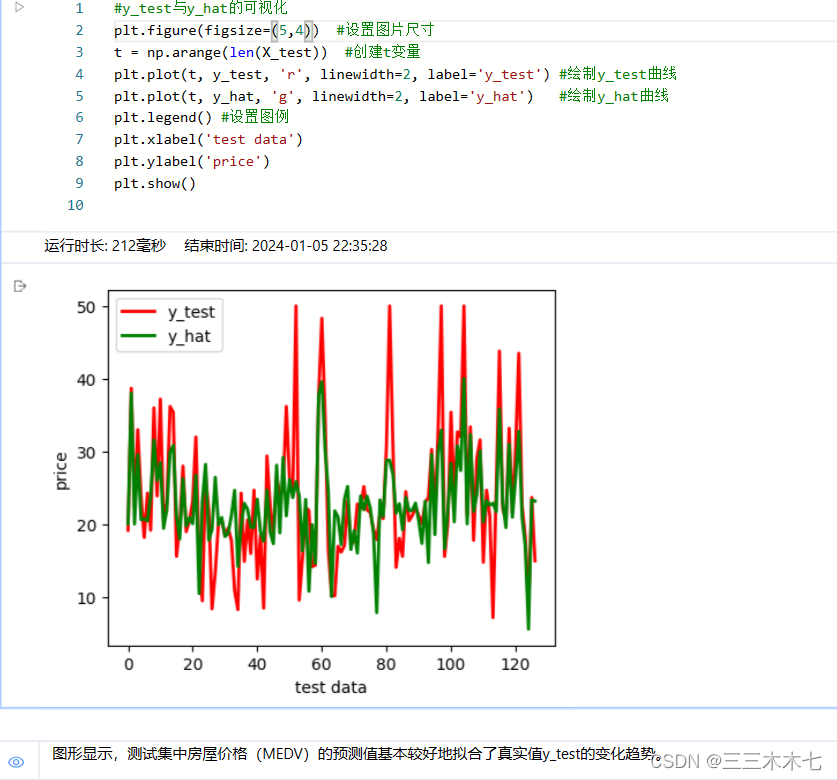
#y_test与y_hat的可视化
plt.figure(figsize=(5,4)) #设置图片尺寸
t = np.arange(len(X_test)) #创建t变量
plt.plot(t, y_test, 'r', linewidth=2, label='y_test') #绘制y_test曲线
plt.plot(t, y_hat, 'g', linewidth=2, label='y_hat') #绘制y_hat曲线
plt.legend() #设置图例
plt.xlabel('test data')
plt.ylabel('price')
plt.show()plt.plot(t, y_test, 'r', linewidth=2, label='y_test') #绘制y_test曲线
解析参数:
x轴的值、y轴的值、折线宽度、线的名称?
🍥散点图?
plt.figure(figsize=(10,6)) #绘制图片尺寸
plt.plot(y_test,y_hat,'o') #绘制散点
plt.plot([-10,60],[-10,60], color="red", linestyle="--", linewidth=1.5)
#这条线为什么是[-10,60],[-10,60],衡量的是预测值和真实值,我们期望它是1:1的
plt.axis([-10,60,-20,70])
plt.xlabel('ground truth') #设置X轴坐标轴标签
plt.ylabel('predicted') #设置y轴坐标轴标签
plt.grid() #绘制网格线 ?这段代码的解释如下
?这段代码的解释如下

🍥损失函数?
from sklearn import metrics
from sklearn.metrics import r2_score
# 拟合优度R2的输出方法一
print ("r2:",lr.score(X_test, y_test)) #基于Linear-Regression()的回归算法得分函数,来对预测集的拟合优度进行评价
# 拟合优度R2的输出方法二
print ("r2_score:",r2_score(y_test, y_hat)) #使用metrics的r2_score来对预测集的拟合优度进行评价
# 用scikit-learn计算MAE
print ("MAE:", metrics.mean_absolute_error(y_test, y_hat)) #计算平均绝对误差
# 用scikit-learn计算MSE
print ("MSE:", metrics.mean_squared_error(y_test, y_hat)) #计算均方误差
# # 用scikit-learn计算RMSE
print ("RMSE:", np.sqrt(metrics.mean_squared_error(y_test, y_hat))) #计算均方根误差?
补充知识点:
列表切片 左闭右开,详细可参考?python-list、tuple_python list tuple-CSDN博客

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!