算法设计与分析python版期末复习笔记-押题版
目录
?
每个题目可能的问题是(九个大题?那我乱押!):
- 代码的输入和输出分别是什么
- 代码选用的数据结构是什么
- 代码选用的算法设计策略是什么?
- 请用自然语言描述求解步骤。
- 算法的功能是什么
- 算法的设计策略是什么?
- 请根据算法,写出递归关系式(包括递归方程和停止条件,缺一不可)(一般是DP题)
- 解出该题的最优值和最优解、(一般是DP题)
- 写出该算法策略的思想
- 分析算法的时间复杂度和空间复杂度(问题:递归的时候 如何分析时间和空间复杂度?递推的时候 只需要看最长的那个循环)
- 写出所用的求解方法
- 描述该方法求解的步骤
- 给出求解过程
- 给出求解结果
- 请定义问题的解空间(回溯法的问题)
- 写出解空间的组织结构(回溯法的问题)
- 写出约束条件和限界条件。(回溯法的问题 如果有约束和限界条件就写 比如就需要一种结果的 但是像全排列啥的 就没有这两个条件);
算法概述
递归方程的求解方法
- 迭代法
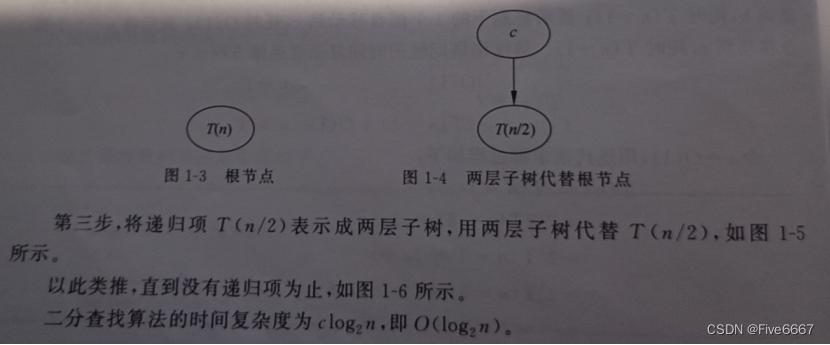
汉诺塔问题 时间复杂度O(2^n)


- 递归树
二分查找 时间复杂度O(log2n):
?


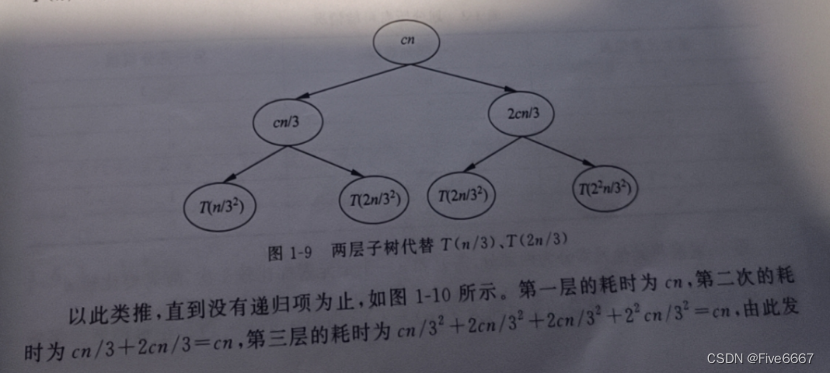
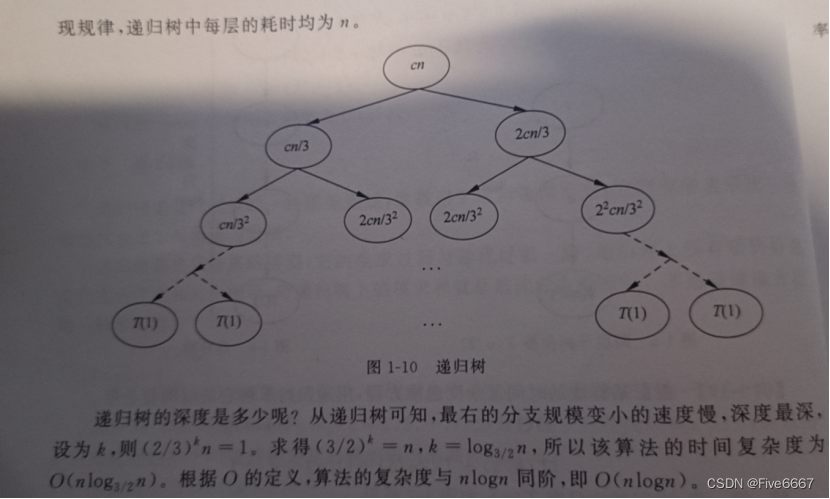
- 差消法
看不懂,跳过!
- 主方法
如图!

?
贪心算法
- 活动安排问题
def activity_selection(start, finish):
????n = len(start)
????# 创建一个活动列表
????activities = []
????for i in range(n):
????????activities.append((start[i], finish[i]))
????# 将活动按照结束时间排序
????activities.sort(key=lambda x: x[1])
????selected_activities = [activities[0]] ?# 第一个活动一定会被选中
????for i in range(1, n):
????????# 如果当前活动的开始时间晚于上一个选中活动的结束时间,则将该活动添加到选中列表中
????????if activities[i][0] >= selected_activities[-1][1]:
????????????selected_activities.append(activities[i])
????return selected_activities
# 示例数据
start_time = [1, 3, 0, 5, 8, 5]
finish_time = [2, 4, 6, 7, 9, 9]
# 调用函数进行活动选择
selected_activities = activity_selection(start_time, finish_time)
# 输出选中的活动
print("选中的活动:")
for activity in selected_activities:
????print("开始时间:", activity[0], "结束时间:", activity[1])1. 代码的输入是活动开始时间和结束时间的列表,例如`start_time = [1, 3, 0, 5, 8, 5]`和`finish_time = [2, 4, 6, 7, 9, 9]`。代码的输出是选中的活动列表,以开始时间和结束时间的形式展示。
2. 代码选用的数据结构是列表(list)和元组(tuple)。
3. 代码选用的算法设计策略是贪心算法。
4. 求解步骤如下:
???- 首先,将活动的开始时间和结束时间存储在一个活动列表中,即将开始时间和结束时间作为一个元组,并按照结束时间对活动进行排序。
???- 然后,选取第一个活动作为被选中的活动。
???- 接下来,从第二个活动开始遍历排序后的活动列表,如果当前活动的开始时间晚于上一个选中活动的结束时间,则将该活动添加到选中的活动列表中。
???- 最后,返回选中的活动列表。
5. 算法的功能是从一组活动中选出最大数量的不相交活动,即找到一组活动,使得它们的时间段没有重叠,并且选出的活动数量最大。
6. 算法的设计策略是贪心算法,在每一步都做出当前最优的选择,即选取当前结束时间最早的活动,以保证后续能够选择更多的活动。
9. 贪心算法的思想是通过每一步的局部最优选择,希望最终能够得到全局最优解。在该算法中,在每一次选择活动的过程中,选择结束时间最早的活动,这样可以最大化活动的数量。
10. 时间复杂度为O(nlogn),其中n是活动的数量,因为需要对活动列表进行排序。空间复杂度为O(n),因为需要创建一个列表来存储活动的开始时间和结束时间的元组。
11. 该算法采用直接求解的方法,通过对活动的结束时间进行排序,然后根据贪心策略选择活动。没有采用递归或递推的方式求解。
- 单源最短路径问题
def dijkstra(graph, start):
????# 初始化距离字典,用于存储从起点到每个顶点的最短路径距离
????distance = {vertex: float('inf') for vertex in graph}
????# 起点距离设为0
????distance[start] = 0
????# 创建一个集合存储已经找到最短路径的顶点
????visited = set()
????while len(visited) < len(graph):
????????# 在未访问的顶点中,找到距离最小的顶点
????????min_distance = float('inf')
????????min_vertex = None
????????for vertex in graph:
????????????if vertex not in visited and distance[vertex] < min_distance:
????????????????min_distance = distance[vertex]
????????????????min_vertex = vertex
????????# 将该顶点标记为已访问
????????visited.add(min_vertex)
????????# 更新从起点到所有相邻顶点的最短距离
????????for neighbor in graph[min_vertex]:
????????????new_distance = distance[min_vertex] + graph[min_vertex][neighbor]
????????????if new_distance < distance[neighbor]:
????????????????distance[neighbor] = new_distance
????return distance
# 示例图的邻接表表示
graph = {
????'A': {'B': 2, 'C': 4},
????'B': {'C': 1, 'D': 4},
????'C': {'D': 1, 'E': 3},
????'D': {'E': 1},
????'E': {}
}
# 起点为A,调用函数找到最短路径距离
shortest_distances = dijkstra(graph, 'A')
# 输出最短路径距离
print("最短路径距离:")
for vertex, distance in shortest_distances.items():
????print("顶点", vertex, "距离起点的最短距离为", distance)1. 代码的输入是表示图的邻接表和起始顶点, 例如:
???```python
???graph = {
???????'A': {'B': 2, 'C': 4},
???????'B': {'C': 1, 'D': 4},
???????'C': {'D': 1, 'E': 3},
???????'D': {'E': 1},
???????'E': {}
???}
???start_vertex = 'A'
???```
???代码的输出是从起始顶点到图中其他顶点的最短路径距离。
2. 代码选用的数据结构是字典(dict),用于表示图的邻接表;集合(set)用于存储已经找到最短路径的顶点;距离字典(dict)用于存储从起点到每个顶点的当前最短路径距离。
3. 代码选用的算法设计策略是贪心算法中的 Dijkstra 算法。
4. 求解步骤描述:
???- 初始化起点到各个顶点的最短距离为无穷大,起点的距离设为0。
???- 在未访问的顶点中选择距离起点最近的顶点,并将其标记为已访问。
???- 更新起点到所有相邻顶点的最短距离。
???- 以上步骤重复,直到所有顶点都被标记为已访问。
5. 算法的功能是求解从单个源顶点出发到其余各顶点的最短路径距离。
6. 算法的设计策略是以贪心的思想每次选择当前最优的顶点进行松弛操作,并逐步确定从原点到其它各个顶点的最短路径。
9. Dijkstra 算法利用了贪心的思想,通过选择当前最优解的方式求解最短路径,即每次都选择当前距离起点最近的顶点进行松弛操作。
10. 时间复杂度为O(V^2),其中V为顶点的数量。空间复杂度为O(V),需要额外空间用于存储距离字典以及已访问的顶点集合。
11. 代码使用的是 Dijkstra 算法进行求解。
- 哈夫曼编码
import heapq
from collections import defaultdict
def huffman_coding(freq):
????heap = [[weight, [symbol, ""]] for symbol, weight in freq.items()]
????heapq.heapify(heap)
????while len(heap) > 1:
????????lo = heapq.heappop(heap)
????????hi = heapq.heappop(heap)
????????for pair in lo[1:]:
????????????pair[1] = '0' + pair[1]
????????for pair in hi[1:]:
????????????pair[1] = '1' + pair[1]
????????heapq.heappush(heap, [lo[0] + hi[0]] + lo[1:] + hi[1:])
????return sorted(heapq.heappop(heap)[1:], key=lambda p: (len(p[-1]), p))
# 示例输入,字母的频率
freq = {'a': 5, 'b': 9, 'c': 12, 'd': 13, 'e': 16, 'f': 45}
# 调用哈夫曼编码函数
huffman_code = huffman_coding(freq)
# 输出哈夫曼编码结果
print("符号 ??词频 ??哈夫曼编码")
for p in huffman_code:
????print("%s ????%d ?????%s" % (p[0], freq[p[0]], p[1]))1. 代码的输入是表示字符频率的字典,例如:
???```python
???freq = {'a': 5, 'b': 9, 'c': 12, 'd': 13, 'e': 16, 'f': 45}
???```
???代码的输出是对每个字符的哈夫曼编码,以及它们对应的频率。
2. 代码选用的数据结构是最小堆(使用 Python 的 heapq 模块)和列表(List)。
3. 代码选用的算法设计策略是贪心算法中的哈夫曼编码算法。
4. 求解步骤描述:
???- 首先,将每个字符和其频率构成的频率字典转化为初始的最小堆。
???- 然后,不断从堆中取出权重最小的两个节点,并合并为一个新的节点,直到堆中只剩下一个节点。
???- 在合并的过程中,对每个新节点分配编码,左子节点编码为'0',右子节点编码为'1'。
???- 最后,对编码进行排序,得到每个字符的哈夫曼编码。
5. 算法的功能是对给定的字符频率进行哈夫曼编码,以便进行数据的压缩和解压缩。
6. 算法的设计策略是利用贪心算法,每次合并权重最小的两个节点,通过不断累积得到最优的编码方案。
9. 哈夫曼编码的思想是通过对出现频率较高的字符赋予较短的编码,来达到对数据进行压缩的目的。在每一步中都选择权重最小的两个节点进行合并,以保证整体编码的最优性。
10. 时间复杂度为 O(nlogn),其中n为字符的数量。空间复杂度取决于最小堆的大小,为O(n)。
11. 代码使用的是贪心算法中的哈夫曼编码算法来求解。
- 最小生成树-Prime?
import sys
def min_key(key, mst_set):
????min_val = sys.maxsize
????min_index = -1
????for v in range(len(key)):
????????if key[v] < min_val and mst_set[v] == False:
????????????min_val = key[v]
????????????min_index = v
????return min_index
def prim_mst(graph):
????V = len(graph)
????key = [sys.maxsize] * V
????parent = [None] * V
????key[0] = 0
????mst_set = [False] * V
????parent[0] = -1
????for _ in range(V):
????????u = min_key(key, mst_set)
????????mst_set[u] = True
????????for v in range(V):
????????????if graph[u][v] > 0 and mst_set[v] == False and key[v] > graph[u][v]:
????????????????key[v] = graph[u][v]
????????????????parent[v] = u
????return parent[1:]
# 使用示例
graph = [[0, 2, 0, 6, 0],
?????????[2, 0, 3, 8, 5],
?????????[0, 3, 0, 0, 7],
?????????[6, 8, 0, 0, 9],
?????????[0, 5, 7, 9, 0]]
print("Edge \tWeight")
mst = prim_mst(graph)
for i in range(1, len(mst) + 1):
print(f"{mst[i-1]} - {i}\t{graph[i][mst[i-1]]}")1. 代码的输入是一个表示图的邻接矩阵,其中每个元素表示两个顶点之间的权重。代码的输出是一个数组,表示最小生成树中每个顶点的父节点。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是贪心算法中的 Prim 算法。
4. 求解步骤描述:
???- 首先,初始化一个关键字列表 key,用于记录每个顶点到最小生成树的距离,将所有距离初始化为无穷大(代表不可达)。
???- 接着,初始化一个父节点列表 parent,用于记录每个顶点在最小生成树中的父节点,将所有父节点初始化为 None。
???- 然后,选择一个起始顶点,将其关键字设为0,表示将该顶点作为最小生成树的起始节点。
???- 进行 n 次循环(n 为图中顶点的数量),每次循环中:
?????- 选取当前不在最小生成树中且具有最小关键字的顶点 u。
?????- 将顶点 u 添加到最小生成树中,将其关键字标记为已访问。
?????- 遍历与顶点 u 相邻的顶点 v,如果顶点 v 不在最小生成树中且与 u 的边权重小于 v 的关键字,则更新 v 的关键字和父节点。
???- 最后,返回最小生成树的父节点数组。
5. 算法的功能是找到一个连通图的最小生成树,即连接所有顶点的一棵带权重的树,使得总权重最小。
6. 算法的设计策略是贪心算法,在每一步中都选择具有最小关键字的顶点,并通过更新关键字和父节点的方式构建最小生成树。
9. Prim 算法的思想是通过贪心策略,不断选择具有最小关键字的顶点,并将其添加到最小生成树中。在每一次选择过程中,只关注当前的局部最优解,而不考虑全局最优解。
10. Prim 算法的时间复杂度为 O(V^2),其中 V 是顶点的数量。空间复杂度为 O(V),主要是为了存储关键字和父节点的数组。
11. 代码使用 Prim 算法来求解图的最小生成树。
- 最小生成树-Kruskal?
def find(parent, i):
????if parent[i] == i:
????????return i
????return find(parent, parent[i])
def union(parent, rank, x, y):
????root_x = find(parent, x)
????root_y = find(parent, y)
????if rank[root_x] < rank[root_y]:
????????parent[root_x] = root_y
????elif rank[root_x] > rank[root_y]:
????????parent[root_y] = root_x
????else:
????????parent[root_y] = root_x
????????rank[root_x] += 1
def kruskal_mst(graph):
????V = len(graph)
????result = []
????graph = sorted(graph, key=lambda item: item[2])
????parent = [i for i in range(V)]
????rank = [0] * V
????e = 0
????i = 0
????while e < V - 1:
????????u, v, w = graph[i]
????????i += 1
????????x = find(parent, u)
????????y = find(parent, v)
????????if x != y:
????????????e += 1
????????????result.append([u, v, w])
????????????union(parent, rank, x, y)
????return result
# 使用示例
graph = [[0, 1, 10],
?????????[0, 2, 6],
?????????[0, 3, 5],
?????????[1, 3, 15],
?????????[2, 3, 4]]
mst = kruskal_mst(graph)
print("Edge \tWeight")
for u, v, w in mst:
????print(f"{u} - {v}\t{w}")1. 代码的输入是一个表示图的边集合,每条边由两个顶点和权重组成。代码的输出是最小生成树的边集合,每条边由两个顶点和权重组成。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是贪心算法中的 Kruskal 算法。
4. 求解步骤描述:
???- 首先,将图的边按照权重从小到大进行排序,得到一个有序的边集合。
???- 接着,创建一个并查集(disjoint-set)来记录顶点的连通情况。
???- 然后,初始化一个空的边集合 result。
???- 依次遍历有序的边集合,对于每条边 (u, v, w):
?????- 如果顶点 u 和顶点 v 不在同一个连通分量中,则将该边加入 result,并将顶点 u 和顶点 v 合并到同一个连通分量中。
???- 最后,返回 result,即最小生成树的边集合。
5. 算法的功能是找到一个连通图的最小生成树,即连接所有顶点的一棵带权重的树,使得总权重最小。
6. 算法的设计策略是贪心算法,通过选择权重最小的边,以逐步构建最小生成树。在每一步中,选择不会导致环形成的边,并确保最后形成的树是连通的。
9. Kruskal 算法的思想是通过贪心策略,每次选择权重最小的边,并保证选择的边不会构成环,直到最小生成树形成。
10. Kruskal 算法的时间复杂度为 O(ElogE),其中 E 是边的数量。空间复杂度为 O(V),主要是为了存储并查集的数据结构和结果的列表。
11. 代码使用 Kruskal 算法来求解图的最小生成树。
- 背包问题
def knapsack_greedy(values, weights, capacity):
????# 计算物品的价值密度
????value_density = [v / w for v, w in zip(values, weights)]
????# 将物品按照价值密度进行排序
????sorted_items = sorted(zip(values, weights, value_density), key=lambda x: x[2], reverse=True)
????total_value = 0
????remaining_capacity = capacity
????selected_items = []
????for item in sorted_items:
????????v, w, _ = item
????????if w <= remaining_capacity:
????????????selected_items.append(item)
????????????total_value += v
????????????remaining_capacity -= w
????return total_value, selected_items
# 使用示例:
values = [60, 100, 120]
weights = [10, 20, 30]
capacity = 50
total_value, selected_items = knapsack_greedy(values, weights, capacity)
print("Total value:", total_value)
print("Selected items:", selected_items)1. 代码的输入是物品的价值列表、重量列表和背包的容量。代码的输出是背包中物品的总价值和被选择的物品列表。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是贪心算法。
4. 求解步骤描述:
????- 首先,计算每个物品的价值密度(价值除以重量)。
????- 然后,对物品按照价值密度从高到低进行排序。
????- 初始化背包的总价值为0,剩余容量为背包的容量,以及一个空的被选择的物品列表。
????- 逐个遍历排序后的物品,对于每个物品:
????????- 如果该物品的重量不超过背包的剩余容量,则将该物品放入背包,同时更新背包的总价值和剩余容量。
????????- 否则,不将该物品放入背包。
????- 返回背包中物品的总价值和被选择的物品列表。
5. 算法的功能是在给定背包容量的情况下,选择若干个物品放入背包,使得背包中物品的总价值最大化。
6. 算法的设计策略是贪心算法,根据每个物品的价值密度,从高到低选择物品放入背包,使得背包中物品的总价值尽可能大。
9. 贪心算法的思想是按照某种规则或者优先级,每次选择当前状态下局部最优解,进而得到全局最优解的一种算法思想。在背包问题中,通过选择价值密度最高的物品放入背包,以期望获得最高的总价值。
10. 这个贪心算法的时间复杂度为 O(nlogn),其中 n 是物品的数量。这个复杂度主要由物品的排序操作决定。空间复杂度为 O(n),用于存储排序后的物品列表。
11. 代码使用贪心算法解决背包问题。通过计算物品的价值密度,并按照价值密度对物品进行排序,再根据排序后的顺序依次判断物品是否能够放入背包。选择能够放入的物品并更新背包的总价值和剩余容量,直到不能放入物品为止。最后返回背包中物品的总价值和被选择的物品列表。
分治算法
- 二分查找
def binary_search(arr, target):
????if not arr:
????????return -1
????left = 0
????right = len(arr) - 1
????while left <= right:
????????mid = (left + right) // 2
????????if arr[mid] == target:
????????????return mid
????????elif arr[mid] < target:
????????????left = mid + 1
????????else:
????????????right = mid - 1
????return -1
# 使用示例:
arr = [2, 5, 8, 12, 16, 23, 38, 56, 72, 91]
target = 23
index = binary_search(arr, target)
if index != -1:
????print("找到目标元素,索引为", index)
else:
print("未找到目标元素")1. 代码的输入是一个已排序的数组(arr)和目标元素(target),输出是目标元素在数组中的索引(如果找到的话)或者 -1(如果未找到)。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是分治思想,具体应用是二分查找算法。
4. 求解步骤描述:
???- 首先,确定要查找的数组的左边界 `left` 和右边界 `right`,初始时分别为数组的第一个和最后一个元素的索引。
???- 然后,在每次迭代中,找到区间的中间位置 `mid`,将中间位置的元素与目标元素进行比较,如果相等,则返回中间位置的索引;如果目标元素较大,则更新左边界为 `mid + 1`;如果目标元素较小,则更新右边界为 `mid - 1`。重复执行这个过程,直到找到目标元素或者区间为空。如果最终没有找到目标元素,则返回 -1。
5. 算法的功能是在一个有序数组中查找特定元素,如果找到则返回其索引,如果未找到则返回 -1。
6. 算法的设计策略是利用分治思想,通过将查找区间一分为二,在每次迭代中排除一半的元素,从而逐步逼近目标元素,降低了查找的时间复杂度。
9. 该算法的思想是通过将查找区间不断减半来逐步逼近目标元素,从而降低查找的时间复杂度。因为数组是有序的,所以可以通过比较中间位置的元素与目标元素的大小关系来决定下一步向哪个方向进行查找。
10. 这个二分查找算法的时间复杂度是 O(logn),其中 n 是数组的长度。每次迭代都将查找区间减半,因此时间复杂度是对数级别的。空间复杂度是 O(1),只需要常数级别的额外空间来保存变量。
11. 二分查找算法采用迭代的方法,在每次迭代中根据中间元素与目标元素的大小关系,更新查找区间的边界,最终找到目标元素或确定其不存在。
- 选第二大元素
def find_second_largest(arr):
????if len(arr) < 2:
????????return "数组元素个数不足"
????def divide_and_conquer(arr, left, right):
????????if left == right:
????????????return (arr[left], arr[left])
????????mid = (left + right) // 2
????????left_max, left_second_max = divide_and_conquer(arr, left, mid)
????????right_max, right_second_max = divide_and_conquer(arr, mid + 1, right)
????????if left_max > right_max:
????????????if left_second_max > right_max:
????????????????return (left_max, left_second_max)
????????????else:
????????????????return (left_max, right_max)
????????else:
????????????if right_second_max > left_max:
????????????????return (right_max, right_second_max)
????????????else:
????????????????return (right_max, left_max)
????max_num, second_max = divide_and_conquer(arr, 0, len(arr) - 1)
????return second_max
# 使用示例:
arr = [3, 8, 2, 5, 1, 9, 4, 7, 6]
result = find_second_largest(arr)
print("数组中第二大的元素为: ", result)1. 代码的输入是一个整数数组(arr),输出是数组中的第二大元素(如果存在)或者相应的提示信息(如果数组元素个数不足)。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是分治思想,通过将数组分成左右两部分,分别求出各自的最大值和第二大值,然后将左右两部分的结果进行合并比较,最终得出整个数组的最大值和第二大值。
4. 求解步骤描述:
???- 首先,判断数组的长度,如果小于2,则返回 "数组元素个数不足" 提示信息。
???- 然后,将数组分成左右两部分,分别递归调用 `divide_and_conquer` 函数,得到左右两部分的最大值和第二大值。
???- 最后,对左右两部分的最大值和第二大值进行比较,如果左边最大值大于右边最大值,则判断左边第二大值和右边最大值的大小,取较大的作为整个数组的第二大值;如果右边最大值大于左边最大值,则判断右边第二大值和左边最大值的大小,取较大的作为整个数组的第二大值。
5. 算法的功能是在一个整数数组中找出第二大的元素。
6. 算法的设计策略是利用分治思想,将数组分成左右两部分分别求出最大值和第二大值,然后根据左右两部分的结果比较求出整个数组的最大值和第二大值。
9. 该算法的思想是将数组分成左右两部分,分别求出各自的最大值和第二大值,然后将左右两部分的结果进行合并比较,最终得出整个数组的最大值和第二大值。因为数组的大小是可分解的,所以可以利用分治思想来逐步求解。
10. 这个算法的时间复杂度是 O(n),其中 n 是数组的长度。因为在每次递归调用时,数组的长度减半,所以递归的时间复杂度是 O(logn)。空间复杂度取决于递归的深度,也就是递归调用的栈空间,是 O(logn) 级别的。
11. 该算法使用了递归的方式实现。利用分治思想将数组分为左右两部分,然后递归调用函数求解左右两部分的最大值和第二大值,最后将左右两部分的结果进行比较得到整个数组的最大值和第二大值。
- 循环赛日程表
def generate_schedule(n):
????if n <= 0:
????????return "参赛队伍数量必须大于0"
????teams = list(range(1, n+1))
????schedule = []
????def divide_and_conquer(teams):
????????if len(teams) == 2:
????????????schedule.append((teams[0], teams[1]))
????????????return
????????mid = len(teams) // 2
????????# 分成两组进行比赛
????????group1 = teams[:mid]
????????group2 = teams[mid:]
????????# 按照分治策略进行循环调度
????????for i in range(mid):
????????????for j in range(mid):
????????????????match1 = (group1[i], group2[j])
????????????????match2 = (group2[j], group1[i])
????????????????schedule.append(match1)
????????????????schedule.append(match2)
????????# 对剩余的队伍进行继续分治
????????divide_and_conquer(group1)
????????divide_and_conquer(group2)
????divide_and_conquer(teams)
????return schedule
# 使用示例:
team_num = 4
result = generate_schedule(team_num)
print("循环赛日程表: ", result)1. 代码的输入是参赛队伍的数量 n(整数),输出是循环赛的日程表,其中包含每场比赛的参赛队伍编号组合。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是分治思想。通过将参赛队伍一分为二,然后使用分治策略对每个组的队伍进行循环调度比赛,逐步构建整个循环赛日程表。
4. 求解步骤描述:
???- 首先,判断参赛队伍数量是否大于0,然后将所有的队伍按照编号放入一个列表中。
???- 然后,定义递归函数 `divide_and_conquer`,如果队伍数量为2,直接将两个队伍构成一个比赛组合加入日程表。
???- 否则,将队伍一分为二,分别形成两个组。然后对每个组的队伍进行循环调度比赛,生成相应的比赛组合加入日程表。最后,递归调用 `divide_and_conquer` 函数,对每个组的队伍进行继续分治。
5. 算法的功能是生成循环赛的日程表,其中包含每场比赛的参赛队伍编号组合。
6. 算法的设计策略是利用分治思想,将参赛队伍一分为二,然后使用分治策略对每个组的队伍进行循环调度比赛。这样逐步构建起整个循环赛日程表。
9. 该算法的思想是利用分治思想,将参赛队伍一分为二,然后使用分治策略对每个组的队伍进行循环调度比赛,逐步构建整个循环赛日程表。
10. 这个算法的时间复杂度是 O(n log n),其中 n 是参赛队伍的数量。在递归调用的时候,每次都将队伍数量减半,因此时间复杂度符合分治法的 Master 定理。空间复杂度是 O(n),用于存储循环赛日程表。在递归的时候,空间复杂度取决于递归调用的深度,最多为 O(log n)。
11. 求解方法是使用分治思想,逐步将参赛队伍一分为二,然后对每个组的队伍进行循环调度比赛,并逐步构建起整个循环赛日程表。
- 合并排序
def merge_array(left,right):
????l,r=0,0
????ans=[]
????while l<len(left) and r <len(right):
????????if left[l]<right[r]:
????????????ans.append(left[l])
????????????l+=1
????????else:
????????????ans.append(right[r])
????????????r+=1
????ans+=left[l::]
????ans+=right[r::]
????return ans
def merge_sort(a):
????if len(a)<=1:
????????return a
????else:
????????mid=len(a)//2
????????left=merge_sort(a[:mid])
????????right=merge_sort(a[mid:])
????????return merge_array(left,right)
n=int(input())
a=[int(i) for i in input().split()]
print(merge_sort(a))1. 代码的输入包括两部分:第一行是数组的长度 n(整数),第二行是 n 个整数表示的待排序数组。输出是经过归并排序后的数组。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是归并排序。归并排序是一种分治的排序算法,通过先递归地将数组分成两部分,分别对这两部分排序,然后将排好序的子数组合并来完成整个数组的排序。
4. 求解步骤描述:
???- 对输入的数组进行递归地二分,直到子数组的长度为1(即子数组已经排好序)。
???- 然后通过 `merge_array` 函数合并两个有序数组,最终完成整个数组的排序。
5. 算法的功能是对输入的数组进行归并排序,最终得到升序排列的数组。
6. 算法的设计策略是采用分治的思想,将数组递归地一分为二,分别对左右两部分进行排序,然后合并两部分以得到排好序的整个数组。
9. 该算法的思想是利用分治思想对数组进行排序。首先将数组一分为二,然后对每个子数组进行递归排序,最后将排好序的子数组合并起来。
10. 归并排序的时间复杂度为 O(nlogn),空间复杂度为 O(n)。在递归的时候,每次将数组一分为二,因此是对数级别的操作,时间复杂度符合分治法的 Master 定理。空间复杂度取决于递归调用的深度,最多为 O(log n)。
11. 求解方法是使用归并排序的算法。首先对数组进行递归地二分,直到子数组的长度为1,然后通过合并两个有序数组完成整个数组的排序。
- 快速排序
n=int(input())
a=[int(i) for i in input().split()]
def qsort(a):
????l,r=[],[]
????if len(a)<=1:
????????return a
????else:
????????key=a[len(a)//2]
????????a.remove(key)
????????for i in a:
????????????if ???i<key:
????????????????l.append(i)
????????????else:
????????????????r.append(i)
????????return qsort(l)+[key]+qsort(r)
print(qsort(a))1. 代码的输入包括两部分:第一行是数组的长度 n(整数),第二行是 n 个整数表示的待排序数组。输出是经过快速排序后的数组。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是快速排序。快速排序是一种分治的排序算法,通过将数组分成较小和较大两个子数组,然后递归地对子数组进行排序。
4. 求解步骤描述:
???- 对输入的数组进行递归排序,直到数组长度为1(即数组已经排好序)。
???- 选择一个基准元素(一般选择数组中间的元素),然后将数组中小于基准的元素放在左边,大于基准的元素放在右边。
???- 对左右两部分分别递归进行快速排序。
???- 最后通过递归合并左右两部分得到整个数组的排序结果。
5. 算法的功能是对输入的数组进行快速排序,最终得到升序排列的数组。
6. 算法的设计策略是采用分治的思想,通过选择基准元素将数组划分成较小和较大两部分,然后对子数组进行递归排序,最后合并左右两部分以得到排好序的整个数组。
9. 该算法的思想是利用分治思想对数组进行排序。选取基准元素,将数组根据基准元素进行划分,然后对划分后的子数组进行递归排序,最后合并子数组得到整个数组的排序结果。
10. 快速排序的时间复杂度取决于划分的平衡性,最好情况下(每次划分都能均匀划分),时间复杂度为 O(nlogn),最坏情况下(每次划分都选择最大或最小元素),时间复杂度为 O(n^2)。在递归的时候,每次将数组划分为两部分,因此递归调用的次数为 O(logn)。空间复杂度取决于递归调用的深度,最多为 O(logn)。
11. 求解方法是使用快速排序的算法。首先选择基准元素,然后根据基准元素将数组划分成较小和较大两部分,递归对子数组进行快速排序,最后合并子数组得到整个数组的排序结果。
- 线性时间选择-找第k小问题
#找出数组中第 k 个小的元素
n,k=map(int,input().split())
a=[]
for i in range(n):
????a.append(int(input()))
def get_min(a):
????if len(a)==1:
????????return a[0]
????else:
????????left=get_min(a[:len(a)//2])
????????right=get_min(a[len(a)//2:])
????????return min(left,right)
ans=[]
temp=0
for i in range(k):
????temp=get_min(a)
????a.remove(temp)
????ans.append(temp)
print('第5小的元素是{}'.format(ans[-1]))1. 代码的输入为包括两部分的内容:第一行包括两个整数 n 和 k(表示数组长度和要寻找的第 k 小的数),接下来 n 行是数组中的 n 个整数。输出为数组中第 k 个小的元素。
2. 代码选用的数据结构是列表(List)。
3. 代码选用的算法设计策略是递归查找。
4. 求解步骤描述:
???- 输入数组 a 和要寻找的第 k 小的数。
???- 定义递归函数 `get_min`,用于递归查找数组中的最小值。
???- 在主程序中,利用 `get_min` 函数找到第 k 个小的元素,并将其添加到结果列表中。
5. 算法的功能是找出给定数组中的第 k 个小的元素。
6. 算法的设计策略是利用递归查找数组中的最小值,并将其移除直到找到第 k 个小的元素。
9. 该算法的策略是将数组的查找任务分解为递归地查找数组中的最小值,并在主程序中持续地递归查找和移除,直到找到第 k 个小的元素。
10. 该算法的时间复杂度分析:
???- 查找最小值的递归过程会将数组一分为二,因此时间复杂度为 O(nlogn),n 表示数组的长度。
???- 空间复杂度为 O(n),递归调用的深度最多为 n。
11. 求解方法是通过递归查找数组中的最小值,并在主程序中持续递归地查找和移除,直到找到第 k 个小的元素。
动态规划算法
- 矩阵连乘问题
def matrix_chain_order(p):
????n = len(p) - 1 ?# 矩阵个数
????m = [[0 for _ in range(n)] for _ in range(n)] ?# 保存最优值的表
????s = [[0 for _ in range(n)] for _ in range(n)] ?# 保存最优断点的表
????for l in range(2, n + 1): ?# 子问题规模
????????for i in range(n - l + 1):
????????????j = i + l - 1
????????????m[i][j] = float('inf')
????????????for k in range(i, j):
????????????????q = m[i][k] + m[k+1][j] + p[i] * p[k+1] * p[j+1]
????????????????if q < m[i][j]:
????????????????????m[i][j] = q
????????????????????s[i][j] = k
????return m, s
def print_optimal_parens(s, i, j):
????if i == j:
????????print(f"A{i+1}", end='')
????else:
????????print("(", end='')
????????print_optimal_parens(s, i, s[i][j])
????????print_optimal_parens(s, s[i][j] + 1, j)
????????print(")", end='')
# 测试
matrix_sizes = [30, 35, 15, 5, 10, 20, 25]
m, s = matrix_chain_order(matrix_sizes)
print_optimal_parens(s, 0, len(matrix_sizes) - 2)1. 代码的输入是一个矩阵的维度数组 `matrix_sizes`,输出是最优的矩阵相乘顺序。
2. 代码选用的数据结构是二维表(二维数组)。
3. 代码选用的算法设计策略是动态规划。
4. 求解步骤描述:
???- 输入矩阵的维度数组 `matrix_sizes`。
???- 定义 `matrix_chain_order` 函数,使用动态规划计算最优的矩阵相乘顺序。
???- 在 `matrix_chain_order` 函数中,使用两个二维表 `m` 和 `s` 分别保存最优值和最优断点的信息。
???- 迭代计算不同规模下的最优值,并保存相关的断点信息。
???- 返回最优值和最优断点的表。
???- 定义 `print_optimal_parens` 函数,根据最优断点信息递归地输出最优的加括号顺序。
???- 在测试部分,给定矩阵的维度数组 `matrix_sizes`,调用 `matrix_chain_order` 计算最优值和最优断点,并通过 `print_optimal_parens` 输出最优的加括号顺序。
5. 算法的功能是计算给定矩阵维度数组下的最优矩阵相乘顺序。
6. 算法的设计策略是动态规划,通过将问题拆解为子问题并保存中间结果,依次求解子问题得到最优解。
7. 递归关系式:
????- 递归方程:m[i][j] = min(m[i][k] + m[k+1][j] + p[i] * p[k+1] * p[j+1]),其中 i ≤ k < j
????- 停止条件:当 l = 2 时,直接计算最小乘法次数,不需要递归。
8. 该题的最优值是最少的矩阵相乘次数,最优解是最优的加括号顺序。
10. 该算法的时间复杂度为 O(n^3),空间复杂度为 O(n^2)。递归的时间复杂度和空间复杂度都取决于子问题的数量和递归深度。
11. 求解方法是使用动态规划,自底向上地计算不同规模下的最优值,并保存最优断点信息。
13. 求解过程是先计算较小规模的子问题,再根据子问题解得到规模更大的子问题的解,直到求解最终的问题。
14. 求解结果是最优的加括号顺序,即最优的矩阵相乘顺序。
- 凸多边形最优三角剖分
def compute_cost(points, i, j, k):
????# 计算三角形的权重,可以根据实际需求设计
????return 0
def minimum_cost_triangulation(points):
????n = len(points)
????dp = [[0] * n for _ in range(n)]
????for gap in range(2, n):
????????for i in range(n - gap):
????????????j = i + gap
????????????dp[i][j] = float('inf')
????????????for k in range(i + 1, j):
????????????????cost = dp[i][k] + dp[k][j] + compute_cost(points, i, j, k)
????????????????if cost < dp[i][j]:
????????????????????dp[i][j] = cost
????return dp[0][n-1]
# 测试
points = [(0, 0), (1, 0), (2, 1), (1, 2), (0, 1)]
result = minimum_cost_triangulation(points)
print('最优三角剖分的最小成本为:', result)1. 代码的输入是凸多边形的顶点坐标数组 `points`,输出是凸多边形的最优三角剖分的最小成本。
2. 代码选用的数据结构是二维表(二维数组)`dp` 用于保存动态规划的中间结果。
3. 代码选用的算法设计策略是动态规划。
4. 求解步骤描述:
???- 输入凸多边形的顶点坐标数组 `points`。
???- 定义 `compute_cost` 函数,根据实际情况计算三角形的权重。
???- 定义 `minimum_cost_triangulation` 函数,使用动态规划求解凸多边形的最优三角剖分的最小成本。
???- 在 `minimum_cost_triangulation` 函数中,创建二维表 `dp` 用于保存动态规划的中间结果。
???- 通过迭代计算不同规模下的最小成本,并保存在表格 `dp` 中。
???- 返回最优的三角剖分的最小成本。
???- 在测试部分,给定凸多边形的顶点坐标数组 `points`,调用 `minimum_cost_triangulation` 计算最优的三角剖分的最小成本。
5. 算法的功能是计算给定凸多边形的最优三角剖分,使得剖分后各三角形权重之和达到最小。
6. 算法的设计策略是动态规划,通过保存中间结果来避免重复计算,从而求解凸多边形的最优三角剖分。
7. 递归关系式:
???- 递归方程:dp[i][j] = min(dp[i][k] + dp[k][j] + compute_cost(points, i, j, k)),其中 i < k < j
???- 停止条件:当 gap = 2 时,直接计算最小成本,不需要递归。
8. 该题的最优值是凸多边形的最优三角剖分的最小成本,最优解是实现最小成本的三角剖分的具体方式。
10. 该算法的时间复杂度为 O(n^3),空间复杂度为 O(n^2)。递归的时间复杂度和空间复杂度取决于子问题的数量和递归深度。
11. 求解方法是使用动态规划,通过迭代计算不同规模下的最小成本,并保存在表格 `dp` 中。
13. 求解过程是自底向上地计算不同规模下的最小成本,并保存在表格 `dp` 中,直到求解出整个凸多边形的最优三角剖分的最小成本。
14. 求解结果是凸多边形的最优三角剖分的最小成本。
- 最长公共子序列问题
def longest_common_subsequence(str1, str2):
????m, n = len(str1), len(str2)
????dp = [[0] * (n + 1) for _ in range(m + 1)]
????for i in range(1, m + 1):
????????for j in range(1, n + 1):
????????????if str1[i-1] == str2[j-1]:
????????????????dp[i][j] = dp[i-1][j-1] + 1
????????????else:
????????????????dp[i][j] = max(dp[i-1][j], dp[i][j-1])
????return dp[m][n]
# 测试
str1 = "abcde"
str2 = "ac"
length = longest_common_subsequence(str1, str2)
print('最长公共子序列长度为:', length)1. 代码的输入是两个字符串 str1 和 str2,输出是这两个字符串的最长公共子序列的长度。
2. 代码选用的数据结构是二维表(二维数组)dp,用于保存动态规划的中间结果。
3. 代码选用的算法设计策略是动态规划。
4. 求解步骤描述:
???- 创建一个二维表 dp 用于保存动态规划的中间结果,维度为 (m+1) * (n+1),其中 m 和 n 分别为两个字符串的长度。
???- 使用两层循环遍历两个字符串,根据情况进行状态转移并填表。如果当前字符相同,则当前位置的值等于左上方值加 1;如果不相同,则取上方和左方的较大值。
???- 最终返回二维表右下角的值,即为最长公共子序列的长度。
5. 算法的功能是求解两个字符串的最长公共子序列的长度。
6. 算法的设计策略是利用动态规划,通过填表的方式保存中间结果,避免重复计算,从而求解最长公共子序列的长度。
7. 递归关系式:
???- 递归方程??dp[i][j] = dp[i-1][j-1] + 1 (if str1[i-1] == str2[j-1])
dp[i][j] = max(dp[i-1][j],
?dp[i][j-1]) (if str1[i-1] != str2[j-1])
???- 停止条件:i=0 或 j=0,此时最长公共子序列的长度为0。
8. 该题的最优值是两个字符串的最长公共子序列的长度,最优解是具体的最长公共子序列本身。
10. 该算法的时间复杂度为 O(m*n),其中 m 和 n 分别为两个字符串的长度,空间复杂度为 O(m*n)。
11. 求解方法是使用动态规划,通过填表的方式保存中间结果,避免重复计算,从而求解最长公共子序列的长度。
13. 求解过程是通过填表的方式计算两个字符串的最长公共子序列的长度。
14. 求解结果是两个字符串的最长公共子序列的长度。
- 加工顺序问题
- 0-1背包问题
n, m = map(int, input().split())
dp = [[0] * (m + 1) for _ in range(n + 1)]
v=[]
w=[]
for i in range(n):
????a, b = map(int, input().split())
????w.append(a)
????v.append(b)
for i in range(n):
????for j in range(m):
????????if j >= w[i]:
????????????dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[i]] + v[i-1])
????????else:
????????????dp[i][j] = dp[i-1][j]
print(dp[n-1][m-1])1. 代码的输入为首先输入两个整数 n 和 m,接着输入 n 对整数,表示每对物品的重量和价值。输出为一个整数,表示在背包容量为 m 的情况下可以获得的最大价值。
2. 代码选用的数据结构是二维列表 dp 以及两个一维列表 v 和 w,分别用来存储动态规划的状态、物品的价值和重量。
3. 代码选用的算法设计策略是动态规划。
4. 求解步骤描述:
????- 首先创建一个二维表 dp 用于保存动态规划的中间结果,维度为 (n+1) * (m+1)。
????- 接着使用两个一维列表 v 和 w 存储每个物品的价值和重量。
????- 通过两层循环遍历每个物品和每个背包容量,并根据状态转移方程更新 dp 数组的值。
????- 最后返回 dp[n-1][m-1],即为背包容量为 m 时可以获得的最大价值。
5. 算法的功能是解决 0-1 背包问题,即在给定背包容量和每个物品的重量、价值情况下,求解可以获得的最大价值。
6. 算法的设计策略是动态规划,通过填表的方式保存中间结果,避免重复计算,从而求解背包问题的最优解。
7. 递归关系式:
???- 递归方程:dp[i][j] = max(dp[i-1][j], dp[i-1][j-w[i]] + v[i]) (当 j >= w[i]),dp[i][j] = dp[i-1][j] (当 j < w[i])
???- 停止条件:遍历完所有物品或者背包容量为0。
8. 该题的最优值是在背包容量为 m 的情况下可以获得的最大价值,最优解是具体的物品放入背包的方案。
10. 该算法的时间复杂度为 O(n * m),空间复杂度为 O(n * m)。
11. 求解方法是使用动态规划,通过填表的方式保存中间结果,避免重复计算,从而求解背包问题的最优解。
13. 求解过程是通过填表的方式计算背包容量为 m 时可以获得的最大价值。
14. 求解结果是在背包容量为 m 的情况下可以获得的最大价值。
- 最优二叉查找树
回溯法
- 经典的解空间结构
子集树、排序树、满m叉树
- 0-1背包问题-子集树
def backtrack(start, weight, value, capacity, max_value, curr_value):
????if weight <= capacity and curr_value > max_value[0]:
????????max_value[0] = curr_value
????if start == len(weight):
????????return
????for i in range(start, len(weight)):
????????if weight[i] + weight[start] <= capacity:
????????????backtrack(i+1, weight, value, capacity, max_value, curr_value + value[i])
????backtrack(start+1, weight, value, capacity, max_value, curr_value)
def knapsack_backtrack(weight, value, capacity):
????max_value = [0]
????backtrack(0, weight, value, capacity, max_value, 0)
????return max_value[0]
# 测试
weights = [2, 3, 4, 5]
values = [3, 4, 5, 6]
knapsack_capacity = 5
result = knapsack_backtrack(weights, values, knapsack_capacity)
print("在背包容量为", knapsack_capacity, "时可以获得的最大价值为", result)1. 代码的输入是物品的重量列表 `weight`、价值列表 `value` 和背包的容量 `capacity`,输出是在给定背包容量下可以获得的最大价值。
2. 代码选用的数据结构是列表来存储物品的重量和价值,整数变量来表示当前的总重量、总价值和最大价值。
3. 代码选用的算法设计策略是回溯法。
4. 求解步骤描述:
???- 首先定义一个回溯函数 `backtrack`,参数包括当前处理的物品索引 `start`、物品的重量列表 `weight`、价值列表 `value`、背包的容量 `capacity`、存储最大价值的列表 `max_value` 以及当前的总价值 `curr_value`。
???- 在回溯函数内部,首先判断当前的总重量是否小于等于背包总容量,并且当前的总价值是否大于之前的最大价值,如果满足条件则更新最大价值。
???- 然后对于每个物品,尝试将其放入背包并递归调用回溯函数,直到处理完所有的物品。
???- 最后,在退出递归之后,返回最大价值。
???- 在 `knapsack_backtrack` 函数中,调用回溯函数 `backtrack` 并返回最大价值。
5. 算法的功能是解决 0-1 背包问题,即在给定背包容量和每个物品的重量、价值情况下,求解可以获得的最大价值。
6. 算法的设计策略是回溯法,利用子集树的思想进行求解。通过遍历所有可能的物品放入背包的情况,找到可以获得最大价值的组合。
10. 该算法的时间复杂度是 O(2^n * n),其中 n 是物品的数量。由于使用了回溯法,需要遍历所有可能的组合,因此时间复杂度较高。空间复杂度为 O(n),主要是用于存储物品的重量和价值以及保存递归过程中的临时变量。
11. 使用回溯法进行求解 0-1 背包问题。
15. 解空间是所有合法的物品选择组合。
16. 解空间的组织结构是一个子集树,树的每个节点表示选择或不选择当前物品,通过遍历子集树中的所有节点来找到最优解。
17. 约束条件是背包容量不能超过预设的容量值,限界条件是根据当前的总重量和总价值,在继续递归遍历时进行剪枝,以避免搜索到不可能得到最优解的子树。
- 最大团问题-子集树
- 批处理作业调度问题-排列树、n皇后问题
n=int(input())
a=[-1]*n
ans=0
def check(k):
????for i in range(k):
????????if abs(i-k)==abs(a[i]-a[k]) or a[i]==a[k]:
????????????return False
????return True
def queen(t):
????global ans
????for i in range(n):
????????a[t]=i
????????if check(t):
????????????if t==n-1:
????????????????ans+=1
????????????????s=''
????????????????for i in range(n):
????????????????????for j in range(n):
????????????????????????if j==a[i]:
????????????????????????????s+='Q '
????????????????????????else:
????????????????????????????s+='* '
????????????????????s+='\n'
????????????????print(s)
????????????else:
????????????????queen(t+1)
queen(0)
print(f'{n}皇后问题共有{ans}种摆放方案')1. 代码的输入是一个整数 n(表示 n 皇后问题),输出是解的数量以及每种解的具体摆放方式。
2. 代码选用的数据结构是列表 a 用来存储每行皇后所在的列数,以及一个整数 ans 用来记录解的数量。
3. 代码选用的算法设计策略是递归回溯算法。
4. 求解步骤描述:
???- 首先定义一个 `check` 函数,用于检查当前位置是否可以放置皇后,避免皇后之间的冲突。
???- 定义一个 `queen` 函数进行递归搜索解空间。在每一行中,尝试将皇后放在每一列,然后递归处理下一行,直到放置完所有皇后或者不满足条件。
???- 在放置完所有皇后或者不满足条件时,打印出当前的解,同时将解的数量加一。
???- 最后输出 皇后问题的解的数量。
5. 算法的功能是解决 n 皇后问题,即找出在 n × n 的棋盘上所有合法的皇后摆放方式,以及统计解的数量。
6. 算法的设计策略是递归回溯算法,通过尝试每一种可能的摆放方式,并在满足条件时继续递归搜索下一行。
10. 该算法的时间复杂度是 O(n!),其中 n 是皇后的数量。在每一层递归中,需要遍历 n 个位置并递归调用下一层,因此时间复杂度为阶乘级别。空间复杂度取决于列表 a,为 O(n)。
11. 使用递归回溯算法进行求解 n 皇后问题。
15. 问题的解空间是在 n × n 的棋盘上所有合法的皇后摆放方式。
16. 解空间的组织结构是一个排列树,它由每一行皇后所在的列数所组成。
17. 约束条件是每个皇后不能在同一行、同一列或同一对角线上,限界条件在于需要找到所有合法的皇后摆放方式。
n=int(input())
q=[-1]*n
def check(k):
????for i in range(k):
????????if abs(q[i]-q[k])==abs(i-k) or q[i]==q[k]:
????????????return 0
????return 1
def queen(t):
????ans=0
????while(t>=0):
????????q[t]+=1
????????while(q[t]<n and check(t)==0):
????????????q[t]+=1
????????if q[t]<n:
????????????if t==n-1:
????????????????ans+=1
????????????????s=''
????????????????for i in range(n):
????????????????????for j in range(n):
????????????????????????if j==q[i]:
????????????????????????????s+='Q '
????????????????????????else:
????????????????????????????s+='* '
????????????????????s+='\n'
????????????????print(s)
????????????else:
????????????????t+=1
????????else:
????????????q[t]=-1
????????????t-=1
????return ans
out=queen(0)
print(f'{n}皇后问题共有{out}种摆放方案')1. 代码的输入是一个整数 n(表示 n 皇后问题),输出是解的数量以及每种解的具体摆放方式。
2. 代码选用的数据结构是列表 q 用来存储每行皇后所在的列数。
3. 代码选用的算法设计策略是迭代回溯算法。
4. 求解步骤描述:
???- 首先定义一个 `check` 函数,用于检查当前位置是否可以放置皇后,避免皇后之间的冲突。
???- 定义一个 `queen` 函数进行迭代搜索解空间。初始时设定一个计数器 `ans` 为 0,代表解的数量。
???- 通过循环,在每一行中尝试将皇后放在每一列,直到找到所有解或者全部搜索完。
???- 加入一个 while 循环节省回溯的时间,直到找到一个可行解或者进行回溯。
???- 在放置完所有皇后时,打印出当前的解,并将计数器 `ans` 加一。
???- 最后输出皇后问题的解的数量。
5. 算法的功能是解决 n 皇后问题,即找出在 n × n 的棋盘上所有合法的皇后摆放方式,以及统计解的数量。
6. 算法的设计策略是迭代回溯算法,通过循环尝试每一种可能的摆放方式,并在满足条件时继续搜索下一行。
10. 该算法的时间复杂度是 O(n!),其中 n 是皇后的数量。在每一层循环中,需要遍历 n 个位置并进行检查,循环的次数为阶乘级别。空间复杂度取决于列表 q,为 O(n)。
11. 使用迭代回溯算法进行求解 n 皇后问题。
15. 问题的解空间是在 n × n 的棋盘上所有合法的皇后摆放方式。
16. 解空间的组织结构是一个排列树,它由每一行皇后所在的列数所组成。
17. 约束条件是每个皇后不能在同一行、同一列或同一对角线上,无特殊的限界条件。
n=int(input())
a=[int(i) for i in range(n)]
result=0
def check(k):
????for i in range(k):
????????if abs(i-k)==abs(a[i]-a[k]):
????????????return False
????return True
def bfs(step):
????global result
????if step==n:
????????result+=1
????for j in range(step,n):
????????a[j],a[step]=a[step],a[j]
????????if check(step):
????????????bfs(step+1)
????????a[j],a[step]=a[step],a[j]
????#return result
bfs(0)
print(result)1. 代码的输入是一个整数 n(表示 n 皇后问题),输出是解的数量。
2. 代码选用的数据结构是列表 a,用于存储每个皇后的列数。
3. 代码选用的算法设计策略是回溯算法。
4. 求解步骤描述:
???- 首先定义一个 `check` 函数,用于检查当前皇后的放置是否满足约束条件,避免皇后之间的冲突。
???- 定义一个回溯函数 `bfs`,其中的参数 `step` 表示当前处理的行数。
???- 在回溯函数内部,遍历当前行 `step` 到 `n`,对每个位置与当前位置交换,并检查是否满足约束条件。
???- 如果满足约束条件,递归调用回溯函数继续处理下一行。
???- 当处理到最后一行时,说明找到了一组解,将结果数量 `result` 加一。
???- 最后,在主函数中调用回溯函数 `bfs` 来找到所有的解并输出结果数量。
5. 算法的功能是解决 n 皇后问题,即统计在 n × n 的棋盘上合法的皇后摆放方式的数量。
6. 算法的设计策略是回溯算法,通过深度优先搜索,在需要回退时进行回溯。
10. 该算法的时间复杂度是 O(n!),其中 n 是皇后的数量。在回溯的过程中,需要遍历每一行的剩余位置,因此时间复杂度为阶乘级别。空间复杂度取决于存储列数的列表 a,为 O(n)。
11. 使用回溯算法进行求解 n 皇后问题。
15. 问题的解空间是在 n × n 的棋盘上所有合法的皇后摆放方式。
16. 解空间的组织结构是一个排列树,每个节点表示在棋盘的某一行放置皇后的选择。
17. 约束条件是每个皇后不能在同一行、同一列或同一对角线上,无特殊的限界条件。
- 旅行商问题-排列树
- 图的m着色问题-满m叉树
def can_color(node, color, color_map):
????for child in node[1:]:
????????if color_map[child] == color:
????????????return False
????return True
def m_color_tree(root, m):
????color_map = {} ?# 存储节点的颜色映射
????def dfs(node):
????????if node in color_map:
????????????return True
????????for color in range(1, m+1):
????????????if can_color(node, color, color_map):
????????????????color_map[node] = color
????????????????success = True
????????????????for child in node[1:]:
????????????????????success = dfs(child)
????????????????????if not success:
????????????????????????break
????????????????if success:
????????????????????return True
????????????????del color_map[node]
????????return False
????result = dfs(root)
????if result:
????????print("满m叉树可以进行m着色")
????????print("着色结果:", color_map)
????else:
????????print("满m叉树无法进行m着色")
# 示例用法
root = (1, (2, ), (3, ), (4, )) ?# 树的表示方式
m = 3 ?# m 着色数
m_color_tree(root, m)1. 代码的输入是满 m 叉树的表示方式和 m 着色数,输出是判断满 m 叉树能否进行 m 着色以及着色结果(若满 m 叉树可以进行 m 着色)。
2. 代码选用的数据结构是元组(Tuple)作为树的表示方式,字典(Dictionary)用于存储颜色映射。
3. 代码选用的算法设计策略是深度优先搜索(DFS)。
4. 求解步骤描述:
???- 首先定义了一个 `can_color` 函数,用于检查给定节点的子节点是否存在和它有相同颜色的情况。
???- 然后定义了一个递归函数 `dfs`,用于进行深度优先搜索并进行着色判断。在搜索过程中,对每个节点进行着色,并通过递归处理其子节点。
???- 当节点已着色或满足约束条件时,继续递归调用 `dfs` 处理子节点。
???- 若成功完成着色,则返回 True;否则,删除节点的颜色映射并继续尝试其他颜色。
???- 在主函数中调用 `dfs`函数进行着色判断,并根据结果输出相应的信息。
5. 算法的功能是判断满 m 叉树是否可以进行 m 着色,并在可着色的情况下给出着色结果。
6. 算法的设计策略是深度优先搜索(DFS),通过递归地进行着色判断,并在遇到约束条件不满足时进行回溯。
10. 该算法的时间复杂度为 O(m^n),其中 n 是满 m 叉树的节点数量,m 是着色数。在每个节点处,需要尝试 m 种不同的颜色,而树的深度为 n,因此时间复杂度为 O(m^n)。空间复杂度取决于颜色映射的大小,即 O(n)。
11. 使用深度优先搜索(DFS)进行求解满 m 叉树的 m 着色问题。
15. 问题的解空间是满 m 叉树的所有可能的合法着色方式。
16. 解空间的组织结构是一个树状结构,每个节点表示树中的一个节点,通过递归地进行着色判断遍历整个树。
17. 无特定的约束条件和限界条件。在这个问题中,约束条件是子节点不能与父节点有相同的颜色,限界条件是在遇到约束条件不满足时及时回溯,尝试其他的颜色。
- 最小质量机器设计问题-满m叉树
分支限界法
- 0-1背包问题
def knapsack(items, max_weight):
????items.sort(key=lambda x: x[1] / x[0], reverse=True) ?# 按照单位重量价值从大到小排序
????best_value = 0
????n = len(items)
????stack = [(0, 0, 0)] ?# (当前层级, 当前重量, 当前价值)
????while stack:
????????level, weight, value = stack.pop()
????????if level == n:
????????????best_value = max(best_value, value)
????????????continue
????????if weight + items[level][0] <= max_weight:
????????????upper_bound = value + (max_weight - weight) * (items[level][1] / items[level][0]) ?# 计算上界
????????????if upper_bound <= best_value: ?# 如果上界小于等于最优值,则剪枝
????????????????continue
????????????stack.append((level + 1, weight + items[level][0], value + items[level][1])) ?# 选择当前物品
????????stack.append((level + 1, weight, value)) ?# 不选择当前物品
????return best_value
# 示例用法
items = [
????(2, 3),
????(3, 4),
????(4, 5),
????(5, 6)
]
max_weight = 8
result = knapsack(items, max_weight)
print("在给定的最大重量下,最大价值为:", result)1. 代码的输入是一个二元组列表 items,表示每个物品的重量和价值,以及一个整数 max_weight,表示背包的最大承重。输出是一个整数,表示在给定最大重量下能装入背包的物品的最大总价值。
2. 代码选用的数据结构是二元组列表来表示每个物品的重量和价值。
3. 代码选用的算法设计策略是分支限界法。
4. 求解步骤描述:
????- 首先对物品按照单位重量价值从大到小排序,以便在分支限界的过程中优先考虑单位重量价值高的物品。
????- 然后利用栈来追踪当前的状态,对每个状态进行判断是否放入当前物品,并计算上界进行剪枝。
????- 通过迭代控制栈的弹出和压入操作,直到遍历完所有的状态。
????- 返回最终的最优值。
5. 算法的功能是在给定最大重量下计算能装入背包的物品的最大总价值。
6. 算法的设计策略是利用贪心思想对物品按单位重量价值从大到小排序,并使用分支限界法进行状态的迭代和剪枝,以找到最优解。
9. 该算法策略的思想是通过不断地搜索状态空间,并利用上界进行剪枝,以排除一些明显不会产生最优解的分支,从而提高搜索效率,找到问题的最优解。
10. 该算法的时间复杂度为 O(2^n),其中 n 是物品的数量,因为在最坏情况下,需要遍历所有可能的状态。空间复杂度为 O(n),取决于栈的深度。
11. 使用分支限界法来求解 0-1 背包问题。
- 旅行商问题
import sys
from itertools import permutations
def tsp(graph):
????n = len(graph)
????min_distance = sys.maxsize
????def dfs(node, visited, distance):
????????nonlocal min_distance
????????if len(visited) == n and graph[node][0] > 0: ?# 所有节点都已经访问过,且最后返回起点
????????????min_distance = min(min_distance, distance + graph[node][0])
????????????return
????????for i in range(n):
????????????if i not in visited and graph[node][i] > 0:
????????????????visited.add(i)
????????????????dfs(i, visited, distance + graph[node][i])
????????????????visited.remove(i)
????dfs(0, {0}, 0) ?# 从节点 0 开始
????return min_distance
# 示例用法
graph = [
????[0, 2, 9, 10],
????[1, 0, 6, 4],
????[15, 7, 0, 8],
????[6, 3, 12, 0]
]
result = tsp(graph)
print("最短路径的长度为:", result)1. 代码的输入是一个带权重的有向图 graph,以邻接矩阵的形式给出。输出是一个整数,表示解决旅行商问题后的最短路径长度。
2. 代码选用的数据结构是邻接矩阵,使用二维列表来表示带权重的有向图。
3. 代码选用的算法设计策略是分治限界法。
4. 求解步骤描述:
????- 从起点出发,采用深度优先搜索(DFS)策略遍历可能的路径,计算路径长度。
????- 在搜索过程中,使用剪枝方式来限制搜索空间,以减少不必要的计算。
????- 记录访问过的节点,确保所有节点都被访问,并最终回到起点。
????- 记录最短路径的长度。
5. 算法的功能是解决旅行商问题,即求解带权重的有向图中使得旅行路径最短的路线。
6. 算法的设计策略是通过深度优先搜索(DFS)来遍历可能的路径,同时利用剪枝策略来限制搜索空间,以达到寻找最短路径的目的。
9. 该算法策略的思想是利用深度优先搜索(DFS)遍历所有可能的路径,通过不断更新最短路径的长度,并且在搜索过程中使用剪枝策略,排除不必要的计算。
10. 该算法的时间复杂度为 O(n!),其中 n 是节点的数量,因为需要遍历所有可能的路径。空间复杂度取决于函数调用栈的深度,最坏情况下为 O(n)。
11. 使用深度优先搜索(DFS)来求解旅行商问题,遍历可能的路径并记录最短路径的长度。
- 布线问题
线性规划问题和网络流
- 线性规划问题
1. 代码的输入是线性规划问题的模型参数,包括目标函数的系数、约束条件的系数矩阵和约束条件的上界/下界,输出是最优解的取值和最优目标函数值。
2. 代码选用的数据结构是数值型变量和矩阵。
3. 代码选用的算法设计策略是使用线性规划求解器进行求解,如使用PuLP库、Gurobi库或其他的线性规划求解工具。
4. 求解步骤描述:
???- 定义目标函数,包括各变量的系数和目标方向(最大化/最小化)。
???- 定义约束条件,包括变量的系数矩阵和约束条件的上界/下界。
???- 调用线性规划求解器进行求解,得到最优解的取值和最优目标函数值。
???- 输出最优解的取值和最优目标函数值。
5. 算法的功能是求解线性规划问题,找到使目标函数取得最大(或最小)值的变量取值。
6. 算法的设计策略是使用线性规划求解器,根据问题的模型参数和约束条件,将问题转化为数学表达式,然后使用求解器进行求解。
9. 该算法的策略思想是将线性规划问题转化为数学表达式,通过数学优化技术对目标函数进行最大化或最小化,找到使目标函数取得最大(或最小)值的决策变量取值。
10. 该算法的时间复杂度和空间复杂度取决于所采用的具体线性规划求解器的实现。通常情况下,大规模线性规划问题的时间复杂度为O(n^3)或更高,空间复杂度为O(n^2),其中n为问题的规模。
11. 所用的求解方法是使用线性规划求解器,具体的实现可以是基于线性规划的算法,如单纯形法、内点法等,或者是基于线性规划松弛问题的算法,如整数线性规划的分枝定界法。具体选择的求解方法取决于问题的性质和规模。
- 最大网络流
1. 代码的输入是一个有向图和源节点、汇节点的标识,输出是最大流量的值和流量分配情况。
2. 代码选用的数据结构是有向图,使用图的边和节点来表示网络流问题。
3. 代码选用的算法设计策略是使用最大流算法,如Ford-Fulkerson方法或Edmonds-Karp算法。
4. 求解步骤描述:
???- 创建一个有向图,并添加边和容量信息。
???- 调用最大流算法,传入有向图、源节点和汇节点,计算最大流。
???- 返回最大流量的值和流量分配情况。
5. 算法的功能是计算给定有向图中从源节点到汇节点的最大网络流量。
6. 算法的设计策略是基于最大流算法,通过不断寻找从源节点到汇节点的路径,并增加流过路径的流量,直到无法再增加为止。
9. 该算法的策略思想是从源节点开始,通过不断寻找增广路径来增加流量,直到无法再找到增广路径为止。在每次寻找增广路径时,可以使用深度优先搜索(DFS)或广度优先搜索(BFS)。
10. 最大流算法的时间复杂度为O(V * E * F),其中V为节点个数,E为边数,F为最大流量。空间复杂度为O(V^2),主要用于存储节点和边的信息。
11. 使用的求解方法是最大流算法。具体的实现可以是Ford-Fulkerson方法,通过不断在残余图中寻找增广路径,并更新流量来求解最大流问题;或者是Edmonds-Karp算法,基于广度优先搜索,每次寻找最短增广路径。这些算法都能够找到从源节点到汇节点的最大网络流量。
- 最小费用最大流
1. 代码的输入包括有向图、源节点、汇节点、每条边的容量和费用。输出是最小费用下的最大流量值和最小费用流。
2. 代码选用的数据结构包括有向图、节点、边以及相关的容量和费用信息。
3. 代码选用的算法设计策略是使用最小费用最大流算法,例如网络流问题中的Zkw算法、费用流问题中的Successive Shortest Path算法等。
4. 求解步骤描述:
???- 创建一个有向图,添加边的容量和费用信息。
???- 调用最小费用最大流算法,传入有向图、源节点和汇节点,计算最小费用下的最大流。
???- 返回最小费用下的最大流量值和最小费用流。
5. 算法的功能是在给定有向图中计算出最小费用下的最大流量值,并给出相应的流分配方案。
6. 算法的设计策略是基于网络流算法,同时考虑了边的容量和费用,以求得在满足容量限制的情况下最小化总费用,并获得最大流量。
9. 该算法的策略思想是通过不断寻找最小费用路径来增加流量,并利用最短增广路或SPFA等方法,直到无法再找到最小费用路径为止。在一些变体的算法中,会利用负环的思想来不断进行费用的调整和路径的更新。
10. 最小费用最大流算法的时间复杂度为 O(min(E * V * f, V^2 * U)), 其中E为边数,V为顶点数,f为最大流量,U为最大费用。空间复杂度主要用于存储图的结构,一般为O(V^2)。
11. 使用的求解方法包括Zkw算法、Successive Shortest Path算法等,这些算法能够找到在满足容量限制的情况下最小化总费用,同时获得最大流量。
随机化算法
应该只会考阅读题
- 数值随机化算法
计算Π值
import random
def approx_pi(n):
????num_points_inside_circle = 0
????num_points_inside_square = 0
????for _ in range(n):
????????x = random.uniform(0, 1)
????????y = random.uniform(0, 1)
????????distance = x**2 + y**2
????????if distance <= 1:
????????????num_points_inside_circle += 1
????????num_points_inside_square += 1
????pi = 4 * num_points_inside_circle / num_points_inside_square
????return pi
# 示例用法
n = 1000000 ?# 迭代次数
approximation = approx_pi(n)
print("π的近似值为:", approximation)1. 代码的输入是一个整数n,表示迭代的次数。输出是一个浮点数,表示近似的π值。
2. 代码使用了基本的数学运算和一维变量来存储迭代过程中的计数。
3. 代码选用的算法设计策略是数值随机化算法,利用随机采样的点来近似计算π值。
4. 求解步骤描述:
????- 生成n个在单位正方形内随机分布的点,每个点的坐标为(x, y),其中x和y的取值范围为[0, 1]。
????- 对于每个点,计算点到原点的距离,即 x^2 + y^2。
????- 统计落在单位圆内的点的数量,即距离小于等于1的点的数量。这一步可以使用欧几里得距离公式进行计算。
????- 通过统计的数量,利用比例关系计算π的近似值。
5. 算法的功能是利用随机采样的点来近似计算圆周率π的值。
6. 算法的设计策略是通过生成大量的随机样本,利用单位圆和单位正方形的面积比例关系来近似计算π的值。
9. 该算法的策略思想是利用随机采样的方法,通过统计单位圆内的点数量与总采样点数量的比例来近似计算π的值。这是一种使用概率统计的方法进行数值计算的策略。
10. 该算法的时间复杂度为O(n),其中n为迭代次数,空间复杂度为O(1)。在这里,时间复杂度是由迭代次数决定的,因为每次迭代都需要生成一个随机点并进行统计。空间复杂度则是常数级的,因为只需要存储一些变量来记录计数。
11. 所用的求解方法是数值随机化算法,通过随机采样单位正方形内的点来近似计算π的值。
计算定积分
- 蒙特卡洛算法
主元素问题
import random
def majority_element(nums):
????n = len(nums)
????threshold = n // 2
????count = 0
????for _ in range(10000): ?# 迭代次数,可根据实际情况进行调整
????????index = random.randint(0, n-1)
????????if nums[index] == nums[random.randint(0, n-1)]:
????????????count += 1
????????if count >= threshold:
????????????return nums[index]
????return None ?# 没有找到主元素
# 示例用法
nums = [1, 2, 3, 2, 2] ?# 输入的列表
result = majority_element(nums)
print("主元素是:", result)1. 代码的输入是一个列表nums,表示输入的数据。输出是一个元素,表示估算得到的主元素,如果不存在主元素则输出None。
2. 代码选用的数据结构是列表。
3. 代码选用的算法设计策略是蒙特卡洛算法,利用随机采样的方式进行估算。
4. 求解步骤描述:
???- 首先计算需要的阈值threshold,即大于等于这个阈值的次数才能视为主元素。
???- 通过随机选取列表中的元素,进行相等性比较。
???- 如果选取的两个元素相等,则计数器count加一。
???- 如果count的值大于等于阈值threshold,则说明找到了主元素,返回该元素。
???- 如果迭代了一定次数后仍未找到主元素,则返回None表示没有找到。
5. 算法的功能是估算给定列表中的主元素,即出现次数超过一半的元素。
6. 算法的设计策略是蒙特卡洛算法,通过随机采样和比较的方式来进行估算。在迭代一定次数后,统计满足条件的次数,从而估算得到主元素。
9. 该算法的策略思想是通过随机采样和比较的方式来进行估算。通过大量的随机比较,可以近似估算主元素的出现次数,从而确定是否存在主元素。
10. 算法的时间复杂度为O(k),其中k表示迭代次数。因为要进行k次随机采样和比较操作。空间复杂度为O(1),只需要几个变量来记录计数和阈值。
11. 所用的求解方法是蒙特卡洛算法,通过随机采样和比较的方式来进行估算主元素。蒙特卡洛算法是一种利用随机采样和统计的方法来解决问题的策略。
素数测试
- 拉斯维加斯算法
整数因子分解
import random
def pollard_rho(n):
????if n % 2 == 0:
????????return 2
????x = random.randint(1, n-1)
????y = x
????c = random.randint(1, n-1)
????d = 1
????def gcd(a, b):
????????while b != 0:
????????????a, b = b, a % b
????????return a
????while d == 1:
????????x = (x**2 + c) % n
????????y = (y**2 + c) % n
????????y = (y**2 + c) % n
????????d = gcd(abs(x - y), n)
????if d == n:
????????return pollard_rho(n) ?# 递归调用直到找到因子
????else:
????????return d
def factorization(n):
????factors = []
????while n > 1:
????????factor = pollard_rho(n)
????????factors.append(factor)
????????n //= factor
????return factors
# 示例用法
number = 8051 ?# 需要分解因子的整数
result = factorization(number)
print("整数", number, "的因子分解结果为:", result)1. 代码的输入是一个待分解因子的整数n。输出是一个列表,包含了n的所有因子。
2. 代码选用的数据结构是列表。
3. 代码选用的算法设计策略是拉斯维加斯算法中的Pollard Rho方法,结合了随机化和迭代的思想进行整数因子分解。
4. 求解步骤描述:
???- 如果n是偶数,则返回2作为因子。
???- 否则,使用Pollard Rho算法中的迭代过程,选择随机起始点x,并初始化y、c和d。
???- 通过迭代计算的方式,尝试找出n的因子d。
???- 如果找到的因子d为n本身,则递归调用Pollard Rho算法直到找到真正的因子。
???- 对找到的因子进行因子分解,同时不断更新n的值。
5. 算法的功能是对给定整数进行因子分解,找出该整数的所有因子。
6. 算法的设计策略是拉斯维加斯算法中的Pollard Rho方法,结合了随机化和迭代的思想进行整数因子分解。通过随机选择起始点、迭代计算的方式,尝试找出整数的因子。
9. 该算法的策略思想是利用随机化和迭代的方法进行整数因子分解。通过不断迭代计算和随机选择起始点,尝试找出整数的因子,从而实现因子分解的目的。
10. 该算法的时间复杂度为O(sqrt(n)),空间复杂度为O(1)。在分析递归的时间和空间复杂度时,通常考虑递归栈的深度以及递归函数本身的计算复杂度。在这种情况下,由于递归调用的次数是随机的,因此难以准确估计其时间复杂度。而空间复杂度则取决于递归栈的深度。
11. 所用的求解方法是拉斯维加斯算法中的Pollard Rho方法,结合了随机化和迭代的思想进行整数因子分解。
n皇后问题
- 舍伍德算法
随机快速排序
import random
def quicksort(arr):
????if len(arr) <= 1:
????????return arr
????pivot = random.choice(arr) ?# 随机选择一个枢纽元素
????left = [x for x in arr if x < pivot]
????equal = [x for x in arr if x == pivot]
????right = [x for x in arr if x > pivot]
????return quicksort(left) + equal + quicksort(right)
# 示例用法
arr = [3, 1, 5, 2, 4]
sorted_arr = quicksort(arr)
print("随机快速排序的结果为:", sorted_arr)1. 代码的输入是一个待排序的列表arr,输出是排序后的列表。
2. 代码选用的数据结构是列表。
3. 代码选用的算法设计策略是使用舍伍德算法的随机快速排序算法。
4. 求解步骤描述:
???- 如果输入列表arr的长度小于等于1,则返回该列表本身。
???- 从arr中随机选择一个枢纽元素pivot。
???- 将arr分为三个部分:小于pivot的元素放在left列表中,等于pivot的元素放在equal列表中,大于pivot的元素放在right列表中。
???- 递归调用quicksort函数对left和right列表进行排序,并将结果与equal列表拼接起来作为排序后的列表返回。
5. 算法的功能是对给定的列表进行排序。
6. 算法的设计策略是使用随机化选择枢纽元素的舍伍德算法的快速排序。通过随机选择枢纽元素的方式来避免最坏情况的发生,提高排序的平均性能。
9. 该算法的策略思想是使用舍伍德算法的随机快速排序,通过随机选择枢纽元素来避免最坏情况的发生。选择枢纽元素时,随机性可以避免在特定情况下出现快速排序的最坏时间复杂度。
10. 该算法的时间复杂度为O(nlogn),空间复杂度为O(n)。在分析递归的时间和空间复杂度时,通常需要考虑递归调用的次数、每次调用的计算复杂度以及递归栈的深度。空间复杂度取决于递归调用栈的深度,最坏情况下为O(n),平均情况下为O(logn)。
11. 所用的求解方法是舍伍德算法的随机快速排序算法。
线性时间选择
NP完全理论
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!