数据分析为何要学统计学(0)——如何提高数据样本质量
2023-12-15 10:29:41
样本是数据分析的关键,直接影响研究成果质量。如果样本质量不高,即使使用再好的分析方法,也无法得出理想的结论。所以数据学科圈里有句名言——“数据比方法更重要”。所以如何提高数据样本的质量是保证研究成果质量的第一步,虽然这一点在现实中往往被忽视。因为当前追求新方法的热情远远高于准备数据,而这种现象对科学研究来说,极为有害。
提高数据样本质量是一项极为传统的技术活,确实没有太多值得圈点的地方。但高水平的研究成果都会以很大的篇幅描述数据的构成及获得过程,以此来突出研究工作的真实性、可靠性、科学性。比较典型的是,一篇优秀的学术论文,Data、Method都是不可或缺,极为重要的章节。
如何提高数据样本质量?我们可以从样本产生的各各环节下手,找出影响样本质量的关键活动,有的放矢地解决这个问题。
首先是确保数据采集的准确性与可靠性,也就是如何降低数据误差
(具体如何采集原始数据属于试验环节,在此不涉及,我们假设原始数据已经采集完成并符合要求)
任何检测都不可能是绝对准确的,测量值与真实值之间总是或多或少的存在着差别,即误差。采样过程必需要尽量降低数据误差。根据误差产生的原因,我们可以将误差分为系统误差、随机误差和过失误差三种情况。
- 系统误差是由测量工具不精确和测量方法选择不当造成的。这类误差我们可以通过校准工具或者选择更合适的测量方法来消除;
- 随机误差是由环境因素等外部不可控原因导致的,如温度、湿度、压力、电磁干扰等。无法预防,也无法从根本上消除。只有通过多闪重复实验来尽可能降低随机误差的比例;
- 过失误差是由操作人员的不履行正确采集操作规程、工作不认真甚至造假等人为因素造成的。这种误差是可以通过员工培训或管理手段避免的。
其次是采用科学的抽样方法。
所谓抽样就是从样本集合中选取一定数量的样本。抽样一是为了降低数据分析的工作量,二是消除人为干预数据供应的情况,同时还可以降低随机误差的不良影响。正确的抽样会显著提高样本代表总体的水平。一般常用的抽样方法包括单纯随机抽样、系统抽样和分层抽样。
- 单纯随机抽样。采用无放回的形式,随机抽取样本集合中的样本,直到达数量要求为止。这种抽样操作简便,公平性强,但不适合大样本集合,容易造成样本分布局部化,降低样本代表总体的水平;

- 系统抽样。首先将样本集合平均分为m组(m为采样数量),然后对每一组进行单纯随机抽样。该方法适合大样本,能够弥补单纯随机抽样局化的缺陷。但是对于数据按顺序有周期特征或单调递增(或递减)趋势特征时,将会产生明显的偏性。
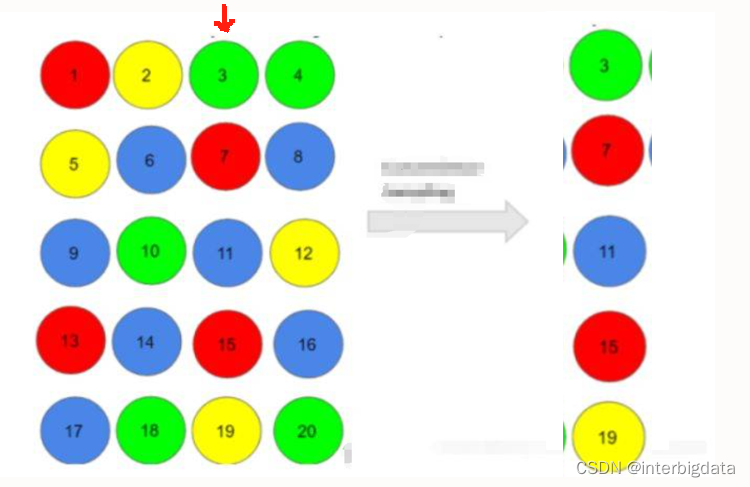
- 分层抽样。先对样本集合根据样本的某种属性进行分组,然后在每组内按等比方式抽样。比如某高校要对学生体BMI监测,一共要抽取300人。该校有男生12000人,女生18000人。于是我们可以将学生分为男生组与女生组,然后按比例从男生中使用随机抽样或系统抽样方法选择120人,女生中选择180人。该方法适合为明显个体特征(如年龄、性别、职业等)的大样本,样本代表性较好,抽样误差较小。缺点是操作更复杂。

有研究指出以上三种抽样方法,分层抽样误差相对最小,单纯随机抽样误差相对最大。不过在计算机的帮助下,抽样工作量已经可以忽略不计,在数据量已经不是问题的前提下,尽量选择低误差的抽样方法是保障样本质量的重要措施。
文章来源:https://blog.csdn.net/interbigdata/article/details/134922118
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!