我开发了一个聚合网盘资源搜索引擎-支持阿里云盘与夸克网盘资源
还在为找不到电子书资源而发愁?还在愁没有高清影视剧观看?
来试试我开发的云盘资源搜索引擎吧!

公众号回复关键词: 搜索 !
就可以获取到网站网址。
这里还有资源分享微信群,不定期分享资源。
关于界面
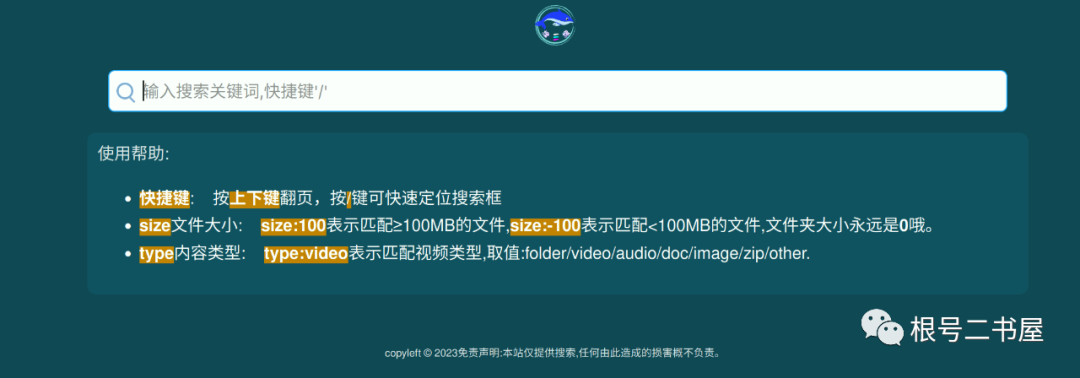
怎么使用这个引擎?
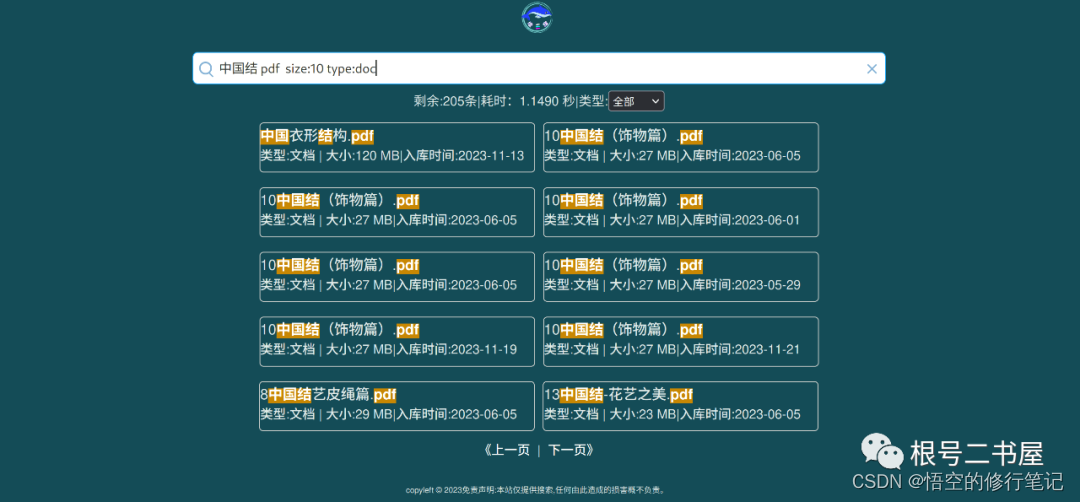
非常简单。想搜索什么就输入搜索词即可。比如找包含中国结的PDF文档就输入"中国结 pdf" 。
既然时文件那就有大小(注意:文件夹的大小永远为0),比如限制搜索结果文件大小在10MB以上,就加上 “size:10” 。
相反,限制文件在 10MB以内,就这样: “size:-10” (加一个负号)。
有些分享着在文件夹名称中也包含了PDF信息,我们可以通过"type:doc" 限制为文档类型。
指定网盘搜索
最新添加了夸克云盘资源的整合,如果想要限制只展示夸克云盘资源可以这样:“中国结 pdf 夸克”。
如果限制只展示阿里云盘资源,就这样: “中国结 pdf 阿里云”。
下面是一个页面展示效果:
为什么会写这个搜索引擎?
写这个搜索服务网站也是为自己使用,网络上分享资源的平台多如牛毛,找点资源困难重重,不是不精准,就是分享链接失效过期了。
出身码农的我何不自己写一个呢?经过一番分析和尝试, 发现实现的方法还是很多的,也并没有非常复杂。
现在看到的版本,其实是经过几次重写的版本,经过自测还是非常的不错。
既然挺好用的,就分享给大家使用,希望可以帮助需要的人。
介绍一下技术实现的过程?
搜索引擎的搜索服务使用的是 Elasticsearch的搜索服务,了解的都会知道这个东西提供的是全文搜索,匹配起来更精准,而且速度也更快,缺点是非常占用内存。前端简单地采用Vue实现。资源采集器采用Go实现。
这个搜索服务的开发过程有些值得说的弯路:
- 资源采集器实现了两次:第一次采用Python实现,优点是开发快,但资源占用多,效率低。第二次采用Go语言实现,主要优点是快,不过这次是并行处理速度快,而且CPU、内存资源占用少。其实Go语言还实现了两版本(第一版采集器、存储器和API服务三者分离,第二版合并为一个服务程序,代码更优美一点)。
- 搜索引擎也有两个版本:最开始采用了Meilisearch实现(抱着新鲜好玩的态度试一试,开发简单快速,但存储占用太高,并且当单个索引文件过大时,搜索那叫一个慢,果断放弃),第二个版本还是老老实实的使用了 Elasticsearch搜索引擎,一如既往的稳定、快速,毕竟这点数据量对于Elasticsearch算不了什么。
关于开发过程的一些事情就说到这里,新开发的资源采集器模型做了其他云盘资源支持能力预留,但采集功能还没有实现。下一步打算支持夸克云盘的资源搜索能力,毕竟低价就可以获取6TB空间,总要存点什么才好哈。
最后
这个搜索引擎起初为个人使用,用着还不错,那就分享给大家一起来用吧。
如果偶尔遇到任何使用问题,可以留言。
假如有更好的点子也交流交流。
这个搜索引擎不会接任何广告,也希望以最简洁的方式呈现搜索内容。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!