训练和测试的loss、accuracy等数据保存到文件并读出
2023-12-28 16:18:34
首先是写文件到excel
import os.path
from openpyxl import load_workbook
import pandas as pd
import matplotlib.pyplot as plt
def write_excel(excel_name, sheet_name, value):
columns = ["epoc", "train_loss", "train_acc", "test_acc"] # 列名
# 创建一个 pandas 的数据框
if not os.path.exists(excel_name): # 文件不存在,就创建一个
df = pd.DataFrame(columns=columns)
df.to_excel(excel_name, index=False)
books = load_workbook(excel_name).sheetnames # 得到已存在的sheet列表
# 将数据框写入 Excel 文件
if sheet_name not in books: # 如果sheet_name不存在,创建
with pd.ExcelWriter(excel_name, engine="openpyxl", mode="a") as writer:
df = pd.DataFrame(columns=columns)
df.to_excel(writer, sheet_name=sheet_name, index=False) # header=None 参数用于追加写入时不重复写入列名
# 追加一行数据
workbooks = load_workbook(excel_name) # 获取文件
worksheet = workbooks[sheet_name] # 获取工作表sheet
worksheet._current_row = worksheet.max_row # 指定最大行数
worksheet.append(value) # 添加数据
workbooks.save(excel_name) # 保存
print("写入成功")
#测试
excel_name = r"example_pandas.xlsx"
sheet_name = "Sheet1"
value = [1, 2, 3, 4]
write_excel(excel_name, sheet_name, value)
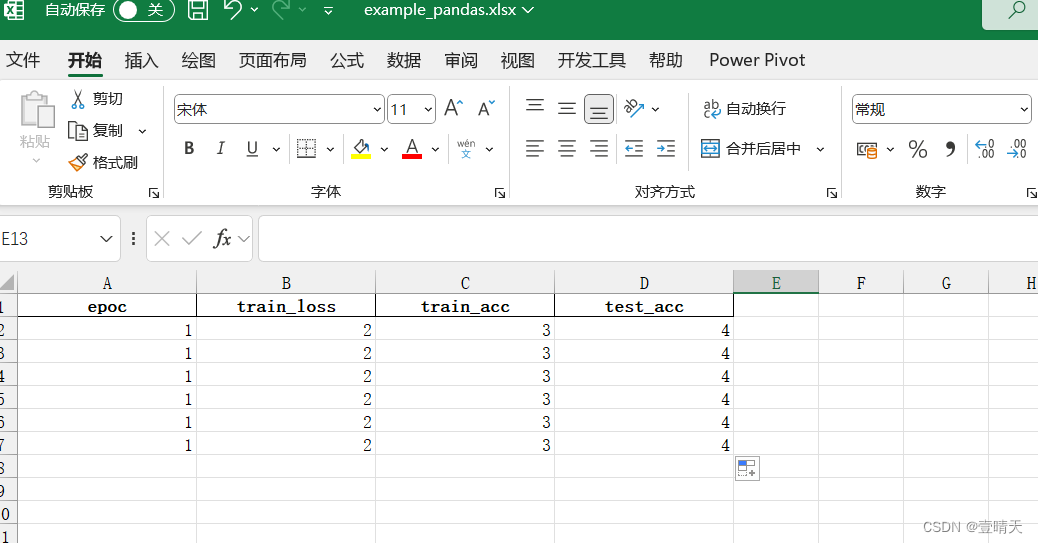
读取excel和绘图
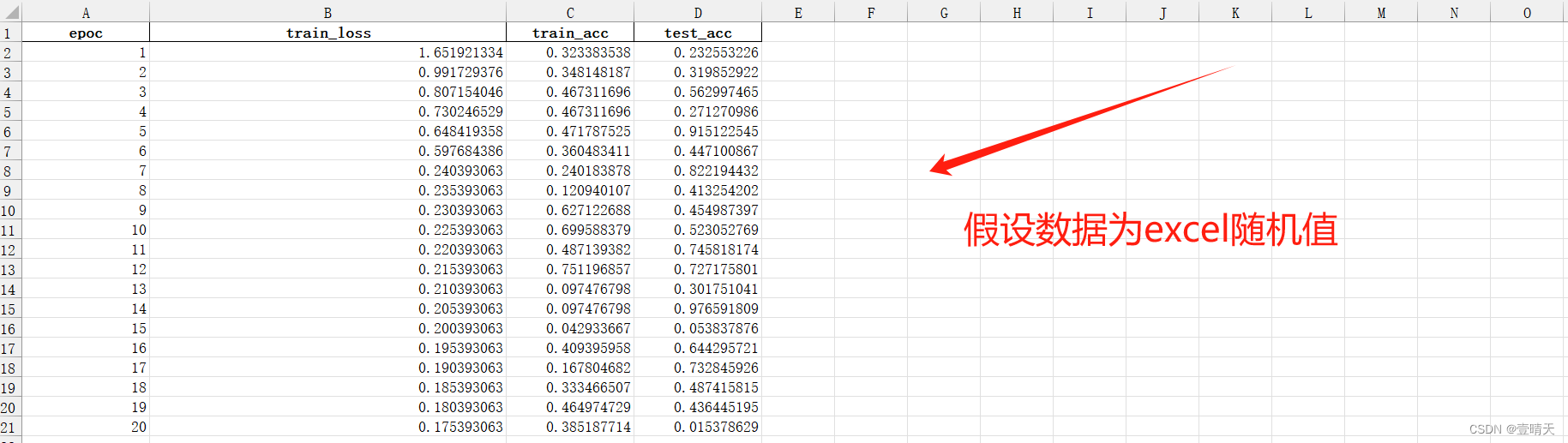
绘制一个loss图,一个准确率图
def image_show(excel_name, sheet_name):
dataframe = pd.read_excel(excel_name, sheet_name) # 读取excel的地址
epoc = dataframe['epoc'].values # 读出某列的数据为一个列表
train_loss = dataframe['train_loss'].values # 读出某列的数据为一个列表
train_acc = dataframe['train_acc'].values # 读出某列的数据为一个列表
test_acc = dataframe['test_acc'].values # 读出某列的数据为一个列表
plt.figure(1, dpi=300) # 画第一个图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.ylim([0, 2]) # 设置y轴刻度范围
# plt.yticks(np.linspace(0, 2, 10)) # 设置刻度
plt.xticks(range(0, 21, 2)) # 共20个值,每2个点显示一次
plt.plot(epoc, train_loss, color='r', marker='', linewidth=1, linestyle='-', label="loss") # 可以调整粗细,大小,颜色
plt.title("train_loss曲线") # 显示图名称
plt.xlabel('e poc') # 显示x轴名称
plt.ylabel('loss') # 显示y轴名称
plt.legend() # 显示标签
# -------------------------------
plt.figure(2, dpi=300) # 画第二个图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.ylim([0, 1])
plt.yticks(np.linspace(0, 1, 10))
plt.plot(epoc, train_acc, color='r', marker='', linewidth=1, linestyle='--', label="train_acc")
plt.plot(epoc, test_acc, color='b', marker='', linewidth=1, linestyle='-', label="test_acc")
plt.title("accuracy准确率")
plt.xlabel('epoc')
plt.ylabel('accuracy')
plt.legend()
plt.show() # 显示
#测试
excel_name = r"example_pandas.xlsx"
sheet_name = "Sheet1" # 工作簿sheet的名字
image_show(excel_name, sheet_name)
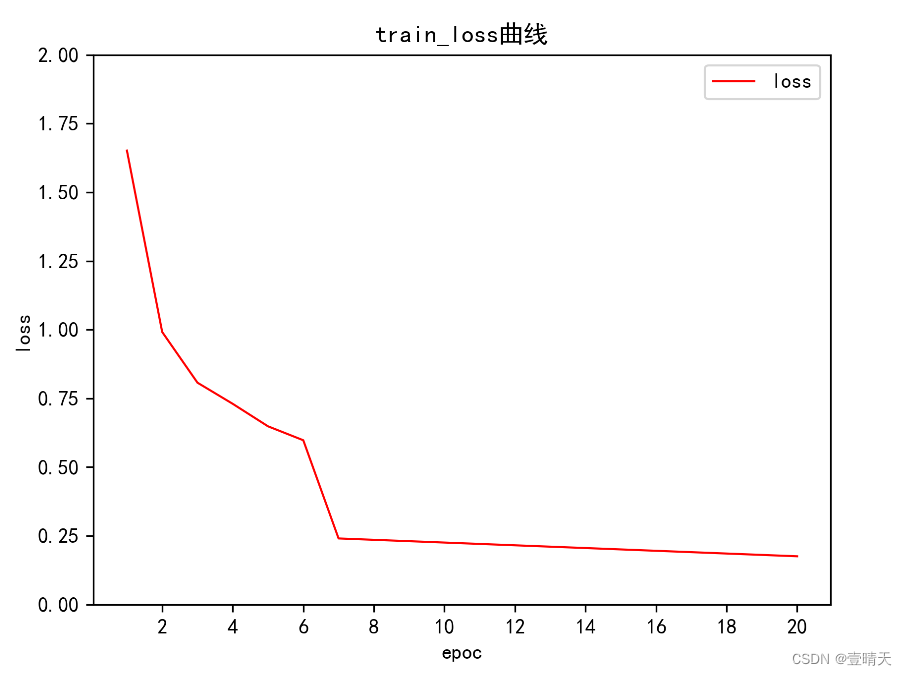
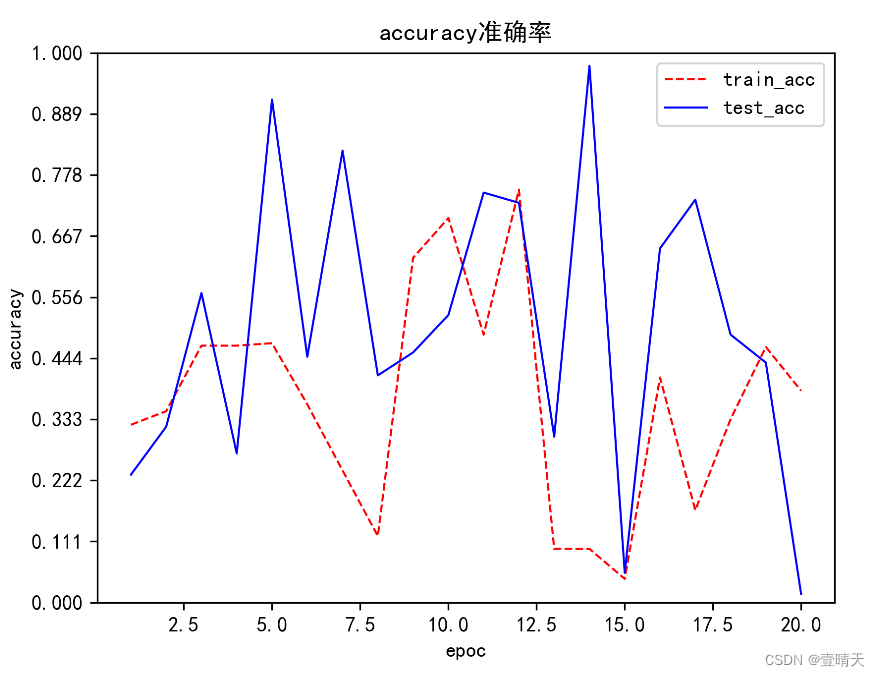
行叭,学习了好半天!到这里吧
奥,对,还有一些读取excel的代码
# 参考 https://blog.csdn.net/HJ_xing/article/details/112390297、https://blog.csdn.net/rebecca_cao/article/details/134899345
# path = r"train_info.xlsx"
# sheet_name = "Sheet1" # 工作簿sheet的名字
# dataframe = pd.read_excel(path, sheet_name) # 读取excel的地址
# print(dataframe)
#
# data = dataframe.values # 获取整个工作表值数据,不包括表的标题
# data = dataframe.head(3) # 读取前3行,包括标题
# data = dataframe.iloc[0].values # 0表示数值第一行,不包含表头
# data = dataframe.iloc[[1, 2, 3, 4]].values # 读取指定多行,在iloc[]里面嵌套列表指定行数
# data = dataframe.sample(3).values # 读取df中随机3行数据(3个样本)
# data = dataframe.iloc[1, 2] # 读取索引为[1, 2]的值,读取指定某行某列(单元格)的数据
# print(dataframe['列名称'].values) # 读出某列的数据为一个列表
# datas = dataframe.loc[:, ['列名1', '列明2']].values # 读所有行的列名1和列名2的值
# datas = dataframe.loc[7:9, ['step', 'train_loss']].values # 读7-9行的列名1和列名2的值
# data = dataframe.loc[[1, 2], ['列明1', '列名2']].values # 读取第一行第二行的列1,列2
# print("输出行号列表", dataframe.index.values)
# print("输出列标题", dataframe.columns.values)
# data = dataframe.head(3) # 读取前3行,带标题
# step = dataframe['step'].values
# train_loss = dataframe['train_loss'].values
文章来源:https://blog.csdn.net/weixin_46672808/article/details/135244318
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!