Verilog学习记录
目录
一、Verilog简介
(一)Verilog 的主要特性
- 可采用 3 种不同的方式进行设计建模:行为级描述——使用过程化结构建模;数据流描述——使用连续赋值语句建模;结构化方式——使用门和模块例化语句描述。
- 两类数据类型:线网(wire)数据类型与寄存器(reg)数据类型,线网表示物理元件之间的连线,寄存器表示抽象的数据存储元件。
- 能够描述层次设计,可使用模块实例化描述任何层次。
- 用户定义原语(UDP)创建十分灵活。原语既可以是组合逻辑,也可以是时序逻辑。
- 可提供显示语言结构指定设计中的指定端口到端口的时延,以及路径时延和时序检查。
- 同一语言可用于生成模拟激励和指定测试的约束条件。
(二)Verilog的主要应用
Verilog 作为硬件描述语言,主要用来生成专用集成电路。主要通过 3 个途径来完成:
1、可编程逻辑器件
FPGA 和 CPLD 是实现这一途径的主流器件。他们直接面向用户,具有极大的灵活性和通用性,实现快捷,测试方便,开发效率高而成本较低。==>FPGA 开发环境有 Xilinx 公司的 ISE(目前已停止更新),VIVADO;因特尔公司的 Quartus II;
2、半定制或全定制 ASIC
通俗来讲,就是利用 Verilog 来设计具有某种特殊功能的专用芯片。根据基本单元工艺的差异,又可分为门阵列 ASIC,标准单元 ASIC,全定制 ASIC。==>ASIC 开发环境有 Synopsys 公司的 VCS ;很多人也在用 Icarus Verilog 和 GTKwave 的方法,更加的轻便。
3、混合 ASIC
主要指既具有面向用户的 FPGA 可编程逻辑功能和逻辑资源,同时也含有可方便调用和配置的硬件标准单元模块,如CPU,RAM,锁相环,乘法器等。
(三)Verilog设计方法
Verilog 的设计多采用自上而下的设计方法(top-down)。即先定义顶层模块功能,进而分析要构成顶层模块的必要子模块;然后进一步对各个模块进行分解、设计,直到到达无法进一步分解的底层功能块。
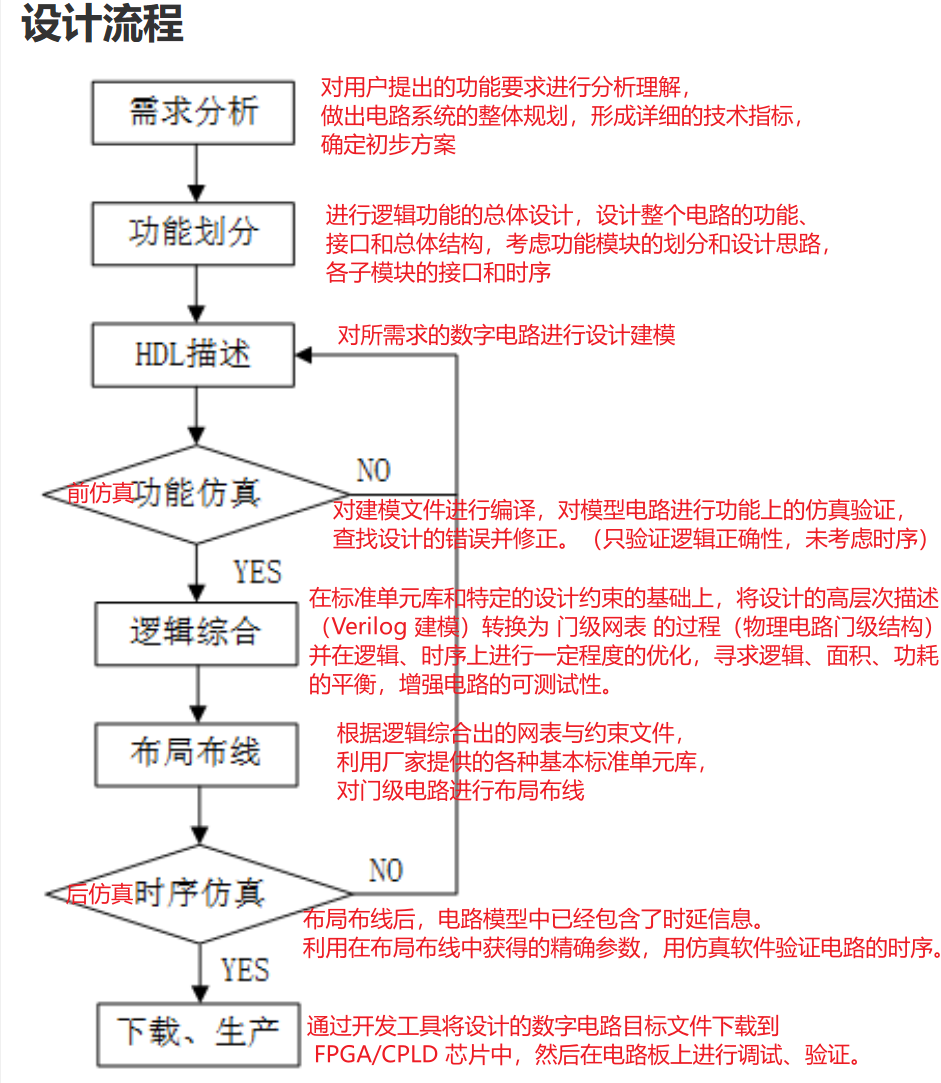
二、Verilog基础语法
Verilog 是区分大小写的,格式自由;可以在一行内编写,也可跨多行编写;每个语句必须以分号为结束符。
(一)标识符和关键字
?标识符(identifier)可以是任意一组字母、数字、$?符号和?_(下划线)符号的合,但标识符的第一个字符必须是字母或者下划线,不能以数字或者美元符开始。
关键字是 Verilog 中预留的用于定义语言结构的特殊标识符,Verilog 中关键字全部为小写。
Verilog HDL 有下列四种基本的值来表示硬件电路中的电平逻辑:
- 0:逻辑 0 或 "假"
- 1:逻辑 1 或 "真"
- x 或 X:未知,信号数值的不确定,即在实际电路里,信号可能为 1,也可能为 0。
- z 或 Z:高阻态,常见于信号(input, reg)没有驱动时的逻辑结果。例如一个 pad 的 input 呈现高阻状态时,其逻辑值和上下拉的状态有关系。上拉则逻辑值为 1,下拉则为 0 。
(二)Verilog数据类型
2.2.1 线网(wire)
wire 类型表示硬件单元之间的物理连线,由其连接的器件输出端连续驱动。如果没有驱动元件连接到 wire 型变量,缺省值一般为 "Z"。
2.2.2寄存器(reg)
寄存器(reg)用来表示存储单元,它会保持数据原有的值,直到被改写
-
整数(integer)
- 整数类型用关键字 integer 来声明。声明时不用指明位宽,位宽和编译器有关,一般为32 bit。reg 型变量为无符号数,而 integer 型变量为有符号数。
-
实数(real)
- 实数用关键字 real 来声明,可用十进制或科学计数法来表示。实数声明不能带有范围,默认值为 0。如果将一个实数赋值给一个整数,则只有实数的整数部分会赋值给整数。
-
时间(time)
- Verilog 使用特殊的时间寄存器 time 型变量,对仿真时间进行保存。其宽度一般为 64 bit,通过调用系统函数 $time 获取当前仿真时间。
-
存储器
- 存储器变量就是一种寄存器数组,可用来描述 RAM 或 ROM 的行为。
-
参数
- 参数用来表示常量,用关键字 parameter 声明,只能赋值一次。但是,通过实例化的方式,可以更改参数在模块中的值。
-
字符串
- 字符串保存在 reg 类型的变量中,每个字符占用一个字节(8bit)。因此寄存器变量的宽度应该足够大,以保证不会溢出。
- 字符串不能多行书写,即字符串中不能包含回车符。如果寄存器变量的宽度大于字符串的大小,则使用 0 来填充左边的空余位;如果寄存器变量的宽度小于字符串大小,则会截去字符串左边多余的数据。
以下是wire和reg都有的:
-
向量
- 当位宽大于 1 时,wire 或 reg 即可声明为向量的形式。
-
数组
- 在 Verilog 中允许声明 reg, wire, integer, time, real 及其向量类型的数组。
- 数组维数没有限制。线网数组也可以用于连接实例模块的端口。数组中的每个元素都可以作为一个标量或者向量,以同样的方式来使用,形如:<数组名>[<下标>]。对于多维数组来讲,用户需要说明其每一维的索引。
- 虽然数组与向量的访问方式在一定程度上类似,但不要将向量和数组混淆。向量是一个单独的元件,位宽为 n;数组由多个元件组成,其中每个元件的位宽为 n 或 1。它们在结构的定义上就有所区别。
(三)Verilog操作符
Verilog 中提供了大约 9 种操作符,分别是算术、关系、等价、逻辑、按位、归约、移位、拼接、条件操作符。
如果操作数某一位为 X,则计算结果也会全部出现 X。例如:
实例
b?=?4'b100x?;
c?=?a+b?;?? ? ??//结果为c=4'bxxxx等价操作符
包括逻辑相等(==),逻辑不等(!=),全等(===),非全等(!==)。
逻辑相等/不等操作符不能比较 x 或 z,当操作数包含一个 x 或 z,则结果为不确定值。
全等比较时,如果按位比较有相同的 x 或 z,返回结果也可以为 1,即全等比较可比较 x 或 z。所以,全等比较的结果一定不包含 x。
归约操作符
包括:归约与(&),归约与非(~&),归约或(|),归约或非(~|),归约异或(^),归约同或(~^)。
归约操作符只有一个操作数,它对这个向量操作数逐位进行操作,最终产生一个 1bit 结果。
逻辑操作符、按位操作符和归约操作符都使用相同的符号表示,因此有时候容易混淆。区分这些操作符的关键是分清操作数的数目,和计算结果的规则。
A = 4'b1010 ;
&A ; //结果为 1 & 0 & 1 & 0 = 1'b0,可用来判断变量A是否全1
~|A ; //结果为 ~(1 | 0 | 1 | 0) = 1'b0, 可用来判断变量A是否为全0
^A ; //结果为 1 ^ 0 ^ 1 ^ 0 = 1'b0(四)Verilog编译指令
2.4.1`define, `undef
在编译阶段,`define?用于文本替换,类似于 C 语言的?#define,`undef?用来取消之前的宏定义。
一旦?`define?指令被编译,其在整个编译过程中都会有效。例如,在一个文件中定义:
`define DATA_DW 32
`define S $stop;
//用`S来代替系统函数$stop; (包括分号)
`define WORD_DEF reg [31:0]
//可以用`WORD_DEF来声明32bit寄存器变量则在另一个文件中也可以直接使用 DATA_DW。
2.4.2?`elsif, `else?
该编译指令对于?`ifdef?指令是可选的,即可以只有?`ifdef?和?`endif?组成一次条件编译指令块。当然,也可用?`ifndef?来设置条件编译,表示如果没有相关的宏定义,则执行相关语句。
`ifdef MCU51
parameter DATA_DW = 8 ;
`elsif WINDOW
parameter DATA_DW = 64 ;
`else
????parameter DATA_DW = 32 ;
`endif2.4.3 `timescale
在 Verilog 模型中,时延有具体的单位时间表述,并用?`timescale?编译指令将时间单位与实际时间相关联。
time_unit 表示时间单位,time_precision 表示时间精度,它们均是由数字以及单位 s(秒),ms(毫秒),us(微妙),ns(纳秒),ps(皮秒)和 fs(飞秒)组成。时间精度可以和时间单位一样,但是时间精度大小不能超过时间单位大小。`timescale 的时间精度设置是会影响仿真时间的。时间精度越小,仿真时占用内存越多,实际使用的仿真时间就越长。所以如果没有必要,应尽量将时间精度设置的大一些。
该指令用于定义时延、仿真的单位和精度,格式为:
`timescale time_unit / time_precision
`timescale 1ns/100ps ? ?//时间单位为1ns,精度为100ps,合法
//`timescale 100ps/1ns ?//不合法
module AndFunc(Z, A, B);
? ? output Z;
? ? input A, B ;
? ? assign #5.207 Z = A & B
endmodule2.4.4 `resetall
该编译器指令将所有的编译指令重新设置为缺省值。`resetall?可以使得缺省连线类型为线网类型。
当 `resetall 加到模块最后时,可以将当前的 `timescale 取消防止进一步传递,只保证当前 `timescale 在局部有效,避免 `timescale 的错误继承。
(五)assign连续赋值
assign LHS_target = RHS_expression ;- LHS_target 必须是一个标量或者线型向量,而不能是寄存器类型。
- RHS_expression 的类型没有要求,可以是标量或线型或存器向量,也可以是函数调用。
- 只要 RHS_expression 表达式的操作数有事件发生(值的变化)时,RHS_expression 就会立刻重新计算,同时赋值给 LHS_target。
三、Verilog过程结构
(一)Initial和always
过程结构语句有 2 种,initial 与 always 语句。它们是行为级建模的 2 种基本语句。
一个模块中可以包含多个 initial 和 always 语句,但 2 种语句不能嵌套使用。
这些语句在模块间并行执行,与其在模块的前后顺序没有关系。但是 initial 语句或 always 语句内部可以理解为是顺序执行的(非阻塞赋值除外)。
每个 initial 语句或 always 语句都会产生一个独立的控制流,执行时间都是从 0 时刻开始。
3.1.1 initial语句
initial 语句从 0 时刻开始执行,只执行一次,多个 initial 块之间是相互独立的。
如果 initial 块内包含多个语句,需要使用关键字 begin 和 end 组成一个块语句。
如果 initial 块内只要一条语句,关键字 begin 和 end 可使用也可不使用。
initial 理论上来讲是不可综合的,多用于初始化、信号检测等。
3.1.2 always语句
与 initial 语句相反,always 语句是重复执行的。always 语句块从 0 时刻开始执行其中的行为语句;当执行完最后一条语句后,便再次执行语句块中的第一条语句,如此循环反复。由于循环执行的特点,always 语句多用于仿真时钟的产生,信号行为的检测等。
(二)阻塞赋值和非阻塞赋值
过程性赋值是在 initial 或 always 语句块里的赋值,赋值对象是寄存器、整数、实数等类型(本质都是reg型变量)。这些变量在被赋值后,其值将保持不变,直到重新被赋予新值。
连续性赋值总是处于激活状态,任何操作数的改变都会影响表达式的结果;过程赋值只有在语句执行的时候,才会起作用。这是连续性赋值与过程性赋值的区别。
Verilog 过程赋值包括 2 种语句:阻塞赋值与非阻塞赋值。
3.2.1 阻塞赋值
- 阻塞赋值属于顺序执行,即下一条语句执行前,当前语句一定会执行完毕。
- 阻塞赋值语句使用等号?=?作为赋值符。
- 前面的仿真中,initial 里面的赋值语句都是用的阻塞赋值。
3.2.2 非阻塞赋值
- 非阻塞赋值属于并行执行语句,即下一条语句的执行和当前语句的执行是同时进行的,它不会阻塞位于同一个语句块中后面语句的执行。
- 非阻塞赋值语句使用小于等于号?<=?作为赋值符。
实际 Verilog 代码设计时,切记不要在一个过程结构中混合使用阻塞赋值与非阻塞赋值。两种赋值方式混用时,时序不容易控制,很容易得到意外的结果。
更多时候,在设计电路时,always 时序逻辑块中多用非阻塞赋值,always 组合逻辑块中多用阻塞赋值;在仿真电路时,initial 块中一般多用阻塞赋值。
如下所示,2 个 always 块中语句并行执行,赋值操作右端操作数使用的是上一个时钟周期的旧值,此时 a<=b 与 b<=a 就可以相互不干扰的执行,达到交换寄存器值的目的。
always?@(posedge?clk)?begin
? ? a?<=?b?;
end
?
always?@(posedge?clk)?begin
? ? b?<=?a;
end四、Verilog时延
连续赋值延时语句中的延时,用于控制任意操作数发生变化到语句左端赋予新值之间的时间延时。
时延一般是不可综合的。寄存器的时延也是可以控制的,这部分在时序控制里加以说明。
(一)连续赋值时延
连续赋值时延一般可分为普通赋值时延、隐式时延、声明时延。
//普通时延,A&B计算结果延时10个时间单位赋值给Z
wire Z, A, B ;
assign #10 Z = A & B ;
//隐式时延,声明一个wire型变量时对其进行包含一定时延的连续赋值。
wire A, B;
wire #10 Z = A & B;
//声明时延,声明一个wire型变量是指定一个时延。因此对该变量所有的连续赋值都会被推迟到指定的时间。除非门级建模中,一般不推荐使用此类方法建模。
wire A, B;
wire #10 Z ;
assign Z =A & B(二)惯性时延
在上述例子中,A 或 B 任意一个变量发生变化,那么在 Z 得到新的值之前,会有 10 个时间单位的时延。如果在这 10 个时间单位内,即在 Z 获取新的值之前,A 或 B 任意一个值又发生了变化,那么计算 Z 的新值时会取 A 或 B 当前的新值。所以称之为惯性时延,即信号脉冲宽度小于时延时,对输出没有影响(还没来得及输出,值就已经没了)。
因此仿真时,时延一定要合理设置,防止某些信号不能进行有效的延迟。
对一个有延迟的与门逻辑进行时延仿真。
(三)时延控制
Verilog 提供了 2 大类时序控制方法:时延控制和事件控制。事件控制主要分为边沿触发事件控制与电平敏感事件控制。
4.3.1 时延控制
基于时延的时序控制出现在表达式中,它指定了语句从开始执行到执行完毕之间的时间间隔。
时延可以是数字、标识符或者表达式。
根据在表达式中的位置差异,时延控制又可以分为常规时延与内嵌时延。
4.3.2 常规时延
遇到常规延时时,该语句需要等待一定时间,然后将计算结果赋值给目标信号。
格式为:#delay procedural_statement,该时延方式的另一种写法是直接将井号?#?独立成一个时延执行语句。
4.3.3内嵌时延
遇到内嵌延时时,该语句先将计算结果保存,然后等待一定的时间后赋值给目标信号。内嵌时延控制加在赋值号之后,当延时语句的赋值符号右端是常量时,2 种时延控制都能达到相同的延时赋值效果。当延时语句的赋值符号右端是变量时,2 种时延控制可能会产生不同的延时赋值效果。
- (1)一般延时的两种表达方式执行的结果都是一致的。
- (2)一般时延赋值方式:遇到延迟语句后先延迟一定的时间,然后将当前操作数赋值给目标信号,并没有"惯性延迟"的特点,不会漏掉相对较窄的脉冲。
- (3)内嵌时延赋值方式:遇到延迟语句后,先计算出表达式右端的结果,然后再延迟一定的时间,赋值给目标信号。
五、一些值得注意的notes
(一)边沿触发事件控制
在 Verilog 中,事件是指某一个 reg 或 wire 型变量发生了值的变化。
基于事件触发的时序控制又主要分为以下几种。
5.1.1 一般事件控制
事件控制用符号?@?表示。
语句执行的条件是信号的值发生特定的变化。
关键字 posedge 指信号发生边沿正向跳变,negedge 指信号发生负向边沿跳变,未指明跳变方向时,则 2 种情况的边沿变化都会触发相关事件。
//信号clk只要发生变化,就执行q<=d,双边沿D触发器模型
always @(clk) q <= d ;
//在信号clk上升沿时刻,执行q<=d,正边沿D触发器模型
always @(posedge clk) q <= d ;
//在信号clk下降沿时刻,执行q<=d,负边沿D触发器模型
always @(negedge clk) q <= d ;5.1.2 命名事件控制
用户可以声明 event(事件)类型的变量,并触发该变量来识别该事件是否发生。命名事件用关键字 event 来声明,触发信号用?->?表示。例如:
event?? ? start_receiving?;
always?@(?posedge?clk_samp)?begin
? ? ? ??->?start_receiving?;?? ? ??//采样时钟上升沿作为时间触发时刻
end
?
always?@(start_receiving)?begin
? ? data_buf?=?{data_if[0],?data_if[1]}?;?//触发时刻,对多维数据整合
end5.1.3 敏感列表
当多个信号或事件中任意一个发生变化都能够触发语句的执行时,Verilog 中使用"或"表达式来描述这种情况,用关键字?or?连接多个事件或信号。这些事件或信号组成的列表称为"敏感列表"。当然,or 也可以用逗号?,?来代替。当组合逻辑输入变量很多时,那么编写敏感列表会很繁琐。此时,更为简洁的写法是?@*?或?@(*),表示对语句块中的所有输入变量的变化都是敏感的。
(二)顺序块,并行块,嵌套块,命名块,disable
Verilog 语句块提供了将两条或更多条语句组成语法结构上相当于一条一句的机制。主要包括两种类型:顺序块和并行块。顺序块和并行块还可以嵌套使用。
5.2.1 顺序块
- 顺序块用关键字 begin 和 end 来表示。
- 顺序块中的语句是一条条执行的。当然,非阻塞赋值除外。
- 顺序块中每条语句的时延总是与其前面语句执行的时间相关。
5.2.2 并行块
- 并行块有关键字 fork 和 join 来表示。
- 并行块中的语句是并行执行的,即便是阻塞形式的赋值。
- 并行块中每条语句的时延都是与块语句开始执行的时间相关。
5.2.3 命名块
我们可以给块语句结构命名。
命名的块中可以声明局部变量,通过层次名引用的方法对变量进行访问。
`timescale 1ns/1ns
?
module test;
?
? ? initial begin: runoob ? //命名模块名字为runoob,分号不能少
? ? ? ? integer ? ?i ; ? ? ? //此变量可以通过test.runoob.i 被其他模块使用
? ? ? ? i = 0 ;
? ? ? ? forever begin
? ? ? ? ? ? #10 i = i + 10 ; ? ? ?
? ? ? ? end
? ? end
?
? ? reg stop_flag ;
? ? initial stop_flag = 1'b0 ;
? ? always begin : detect_stop
? ? ? ? if ( test.runoob.i == 100) begin //i累加10次,即100ns时停止仿真
? ? ? ? ? ? $display("Now you can stop the simulation!!!");
? ? ? ? ? ? stop_flag = 1'b1 ;
? ? ? ? end
? ? ? ? #10 ;
? ? end
?
endmodulerepeat 的功能是执行固定次数的循环,它不能像 while 循环那样用一个逻辑表达式来确定循环是否继续执行。repeat 循环的次数必须是一个常量、变量或信号。如果循环次数是变量信号,则循环次数是开始执行 repeat 循环时变量信号的值。即便执行期间,循环次数代表的变量信号值发生了变化,repeat 执行次数也不会改变。
(三)例化,generate,全加器,层次访问
在一个模块中引用另一个模块,对其端口进行相关连接,叫做模块例化。模块例化建立了描述的层次。信号端口可以通过位置或名称关联,端口连接也必须遵循一些规则。
5.3.1 命名端口连接
如果某些输出端口并不需要在外部连接,例化时 可以悬空不连接,甚至删除。一般来说,input 端口在例化时不能删除,否则编译报错,output 端口在例化时可以删除。
5.3.2 顺序端口连接
这种方法将需要例化的模块端口按照模块声明时端口的顺序与外部信号进行匹配连接,位置要严格保持一致。虽然代码从书写上可能会占用相对较少的空间,但代码可读性降低,也不易于调试。有时候在大型的设计中可能会有很多个端口,端口信号的顺序时不时的可能也会有所改动,此时再利用顺序端口连接进行模块例化,显然是不方便的。所以平时,建议采用命名端口方式对模块进行例化。
5.3.3 用 generate 进行模块例化
当例化多个相同的模块时,一个一个的手动例化会比较繁琐。用 generate 语句进行多个模块的重复例化,可大大简化程序的编写过程。
重复例化 4 个 1bit 全加器组成一个 4bit 全加器的代码如下:
module full_adder4(
? ? input [3:0] ? a , ? //adder1
? ? input [3:0] ? b , ? //adder2
? ? input ? ? ? ? c , ? //input carry bit
?
? ? output [3:0] ?so , ?//adding result
? ? output ? ? ? ?co ? ?//output carry bit
? ? );
?
? ? wire [3:0] ? ?co_temp ;
? ? //第一个例化模块一般格式有所差异,需要单独例化
? ? full_adder1 ?u_adder0(
? ? ? ? .Ai ? ? (a[0]),
? ? ? ? .Bi ? ? (b[0]),
? ? ? ? .Ci ? ? (c==1'b1 ? 1'b1 : 1'b0),
? ? ? ? .So ? ? (so[0]),
? ? ? ? .Co ? ? (co_temp[0]));
?
? ? genvar ? ? ? ?i ;
? ? generate
? ? ? ? for(i=1; i<=3; i=i+1) begin: adder_gen
? ? ? ? full_adder1 ?u_adder(
? ? ? ? ? ? .Ai ? ? (a[i]),
? ? ? ? ? ? .Bi ? ? (b[i]),
? ? ? ? ? ? .Ci ? ? (co_temp[i-1]), //上一个全加器的溢位是下一个的进位
? ? ? ? ? ? .So ? ? (so[i]),
? ? ? ? ? ? .Co ? ? (co_temp[i]));
? ? ? ? end
? ? endgenerate
?
? ? assign co ? ?= co_temp[3] ;
?
endmodule(四) defparam,参数,例化,ram
当一个模块被另一个模块引用例化时,高层模块可以对低层模块的参数值进行改写。这样就允许在编译时将不同的参数传递给多个相同名字的模块,而不用单独为只有参数不同的多个模块再新建文件。
参数覆盖有 2 种方式:1)使用关键字 defparam,2)带参数值模块例化。
5.4.1 defparam 语句
可以用关键字 defparam 通过模块层次调用的方法,来改写低层次模块的参数值。
//instantiation
defparam ? ? u_ram_4x4.MASK = 7 ;
ram_4x4 ? ?u_ram_4x4
? ? (
? ? ? ? .CLK ? ?(clk),
? ? ? ? .A ? ? ?(a[4-1:0]),
? ? ? ? .D ? ? ?(d),
? ? ? ? .EN ? ? (en),
? ? ? ? .WR ? ? (wr), ? ?//1 for write and 0 for read
? ? ? ? .Q ? ? ?(q) ? ?);5.4.2 带参数模块例化
第二种方法就是例化模块时,将新的参数值写入模块例化语句,以此来改写原有 module 的参数值。
ram #(.AW(4), .DW(4))
? ? u_ram
? ? (
? ? ? ? .CLK ? ?(clk),
? ? ? ? .A ? ? ?(a[AW-1:0]),
? ? ? ? .D ? ? ?(d),
? ? ? ? .EN ? ? (en),
? ? ? ? .WR ? ? (wr), ? ?//1 for write and 0 for read
? ? ? ? .Q ? ? ?(q)
? ? ?);模块在编写时,如果预知将被例化且有需要改写的参数,都将这些参数写入到模块端口声明之前的地方(用关键字井号?#?表示)。这样的代码格式不仅有很好的可读性,而且方便调试。对已有模块进行例化并将其相关参数进行改写时,不要采用 defparam 的方法。除了上述缺点外,defparam 一般也不可综合。
(五)函数,大小端转换,数码管译码
在 Verilog 中,可以利用任务(关键字为 task)或函数(关键字为 function),将重复性的行为级设计进行提取,并在多个地方调用,来避免重复代码的多次编写,使代码更加的简洁、易懂。
5.5.1 函数
函数只能在模块中定义,位置任意,并在模块的任何地方引用,作用范围也局限于此模块。函数主要有以下几个特点:
- 1)不含有任何延迟、时序或时序控制逻辑
- 2)至少有一个输入变量
- 3)只有一个返回值,且没有输出
- 4)不含有非阻塞赋值语句
- 5)函数可以调用其他函数,但是不能调用任务
//function entity
function [N-1:0] data_rvs ;
input [N-1:0] data_in ;
parameter MASK = 32'h3 ;
integer k ;
begin
for(k=0; k<N; k=k+1) begin
data_rvs[N-k-1] = data_in[k] ;
end
end
endfunction5.5.2 任务与函数的区别
和函数一样,任务(task)可以用来描述共同的代码段,并在模块内任意位置被调用,让代码更加的直观易读。函数一般用于组合逻辑的各种转换和计算,而任务更像一个过程,不仅能完成函数的功能,还可以包含时序控制逻辑。下面对任务与函数的区别进行概括:

(六)竞争,冒险,书写规范
5.6.1 产生原因
数字电路中,信号传输与状态变换时都会有一定的延时。
- 在组合逻辑电路中,不同路径的输入信号变化传输到同一点门级电路时,在时间上有先有后,这种先后所形成的时间差称为竞争(Competition)。
- 由于竞争的存在,输出信号需要经过一段时间才能达到期望状态,过渡时间内可能产生瞬间的错误输出,例如尖峰脉冲。这种现象被称为冒险(Hazard)。
- 竞争不一定有冒险,但冒险一定会有竞争。
5.6.2 规避方法
在编程时多注意以下几点,也可以避免大多数的竞争与冒险问题。
- 时序电路建模时,用非阻塞赋值。
- 组合逻辑建模时,用阻塞赋值。
- 在同一个 always 块中建立时序和组合逻辑模型时,用非阻塞赋值。
- 在同一个 always 块中不要既使用阻塞赋值又使用非阻塞赋值。
- 不要在多个 always 块中为同一个变量赋值。
- 避免 latch 产生。
(七)锁存器
5.7.1 锁存器及其危害
一个变量声明为寄存器时,它既可以被综合成触发器,也可能被综合成 Latch,甚至是 wire 型变量。但是大多数情况下我们希望它被综合成触发器,但是有时候由于代码书写问题,它会被综合成不期望的 Latch 结构。
锁存器(Latch)是电平触发的存储单元,数据存储的动作取决于输入时钟(或者使能)信号的电平值。仅当锁存器处于使能状态时,输出才会随着数据输入发生变化。
当电平信号无效时,输出信号随输入信号变化,就像通过了缓冲器;当电平有效时,输出信号被锁存。激励信号的任何变化,都将直接引起锁存器输出状态的改变,很有可能会因为瞬态特性不稳定而产生振荡现象。
Latch 的主要危害有:
- 1)输入状态可能多次变化,容易产生毛刺,增加了下一级电路的不确定性;
- 2)在大部分 FPGA 的资源中,可能需要比触发器更多的资源去实现 Latch 结构;
- 3)锁存器的出现使得静态时序分析变得更加复杂。
5.7.2 避免latch的产生
Latch 多用于门控时钟(clock gating)的控制,一般设计时,我们应当避免 Latch 的产生。Latch产生的情况:
- 组合逻辑中,不完整的 if - else 结构,会产生 latch。(补全 if-else 结构,或者对信号赋初值)
- case 语句产生 Latch 的原理几乎和 if 语句一致。在组合逻辑中,当 case 选项列表不全且没有加 default 关键字,或有多个赋值语句不完整时,也会产生 Latch。(将 case 选项列表补充完整,或对信号赋初值)
- 在组合逻辑中,如果一个信号的赋值源头有其信号本身,或者判断条件中有其信号本身的逻辑,则也会产生 latch。因为此时信号也需要具有存储功能,但是没有时钟驱动。(在组合逻辑中避免这种写法,信号不要给信号自己赋值,且不要用赋值信号本身参与判断条件逻辑)
- 如果组合逻辑中 always@() 块内敏感列表没有列全,该触发的时候没有触发,那么相关寄存器还是会保存之前的输出结果,因而会生成锁存器。(敏感信号列表建议多用 always@(*))
(八)信号声明,时钟和复位生成
5.8.1信号声明
testbench 模块声明时,一般不需要声明端口。因为激励信号一般都在 testbench 模块内部,没有外部信号。
声明的变量应该能全部对应被测试模块的端口。当然,变量不一定要与被测试模块端口名字一样。但是被测试模块输入端对应的变量应该声明为 reg 型,如 clk,rstn 等,输出端对应的变量应该声明为 wire 型,如 dout,dout_en。
5.8.2 时钟生成
生成时钟的方式有很多种,例如以下两种生成方式也可以借鉴。
initial clk = 0 ;
always #(CYCLE_200MHz/2) clk = ~clk;
initial begin
? ? clk = 0 ;
? ? forever begin
? ? ? ? #(CYCLE_200MHz/2) clk = ~clk;
? ? end
end利用参数的方法去指定时间延迟时,如果延时参数为浮点数,该参数不要声明为 parameter 类型。当然,timescale 的精度也需要提高,单位和精度不能一样,否则小数部分的时间延迟赋值也将不起作用。
5.8.3 复位生成
复位逻辑比较简单,一般赋初值为 0,再经过一段小延迟后,复位为 1 即可。
这里大多数的仿真都是用的低有效复位。
六、状态机
(一)状态机类型
Verilog 中状态机主要用于同步时序逻辑的设计,能够在有限个状态之间按一定要求和规律切换时序电路的状态。状态的切换方向不但取决于各个输入值,还取决于当前所在状态。 状态机可分为 2 类:Moore 状态机和 Mealy 状态机。
6.1.1 Moore 型状态机
Moore 型状态机的输出只与当前状态有关,与当前输入无关。
输出会在一个完整的时钟周期内保持稳定,即使此时输入信号有变化,输出也不会变化。输入对输出的影响要到下一个时钟周期才能反映出来。这也是 Moore 型状态机的一个重要特点:输入与输出是隔离开来的。
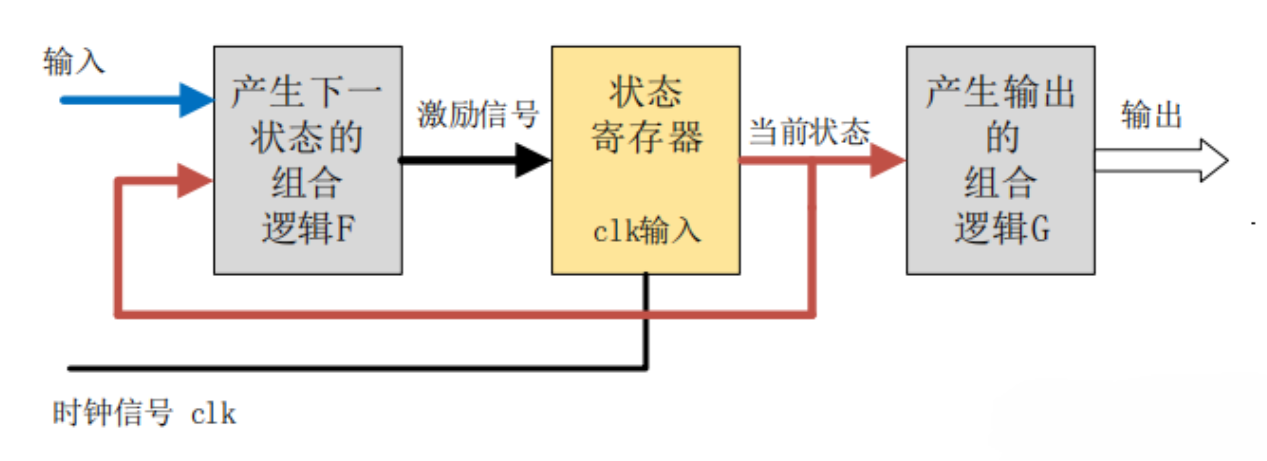
6.1.2 Mealy 型状态机
Mealy 型状态机的输出,不仅与当前状态有关,还取决于当前的输入信号。
Mealy 型状态机的输出是在输入信号变化以后立刻发生变化,且输入变化可能出现在任何状态的时钟周期内。因此,同种逻辑下,Mealy 型状态机输出对输入的响应会比 Moore 型状态机早一个时钟周期。

(二)状态机设计流程
根据设计需求画出状态转移图,确定使用状态机类型,并标注出各种输入输出信号,更有助于编程。一般使用最多的是 Mealy 型 3 段式状态机。
状态机设计:3 段式(推荐)
- (0) 首先,根据状态机的个数确定状态机编码。利用编码给状态寄存器赋值,代码可读性更好。
- (1) 状态机第一段,时序逻辑,非阻塞赋值,传递寄存器的状态。(即状态转移,同步复位,cstate <= nstate)
- (2) 状态机第二段,组合逻辑,阻塞赋值,根据当前状态和当前输入,确定下一个状态机的状态。(当前状态可以转移到哪个状态,组合逻辑)
- (3) 状态机第三段,时序逻辑,非阻塞赋值,因为是 Mealy 型状态机,根据当前状态和当前输入,确定输出信号。(在当前状态要做出那些行动,时序逻辑)
七、编码风格和规范
(一)Verilog编码风格
- 信号变量、模块等一定要使用有意义的名字,且信号名称在模块间穿梭时也应该保持不变,以便代码自身就具有清晰的说明信息,增强可读性。
- 当名字单词数量过多时,可以使用首字母大写或下划线"_"进行拼接。个人喜欢后者,比较清晰。(即小写字母+下划线,见名知义)
- 建议使用单词缩写的方式对信号进行命名,并懂得取舍,避免过长的信号命名。例如 clock 缩写为 clk, destination 缩写为 dest,source 缩写为 src 等。
- 巧用数字代表英文字母,例如 2 代表 to, 4 代表 for, 可以省略一丢丢代码空间。
- 虽然 Verilog 区分大小写,但是建议一般功能模块的名称、端口、信号变量等全部使用小写,parameter 使用大写,一些电源、pad 等特殊端口使用大写。
- 寄存器变量一般加后缀?_r, 延迟打拍的变量加后缀?_r1、_r2等。主要有两大好处。一是 RTL 设计时容易根据变量类型对数据进行操作。二是综合后网表的信号名字经常会改变,加入后缀容易在综合后网表中找到与 RTL 中对应的信号变量。
- 其他尾缀:_d?可以表示延迟后的信号,_t?可以表示暂时存储的信号,_n?可以表示低有效的信号,_s?可以表示 slave 信号,_m?可以表示 master 信号等。
- 避免使用关键字对信号进行命名,例如?in, out, x, z?均不建议作为变量。
- 文件名字保持与设计的?module?名字一致,文件内尽量只包含一个设计模块。
- 一行代码内容过长时,尽量换行编写,无需使用换行符。
- 口信号保证每行一个信号,逗号紧跟在端口声明之后,强迫症患者请保持逗号也对齐。
- 尽量使用 begin + end 的方式保证执行语句间的层叠关系。begin 与关键字同行,end 另起一行。
- 尽量使用 tab 键和空格,保证语句按照层级结构对齐,变量、关键字、操作符之间也应该留有空隙,便于逻辑判断。
- 模块例化时,端口信号尽量与连接信号隔开,并各自对齐。连接信号为向量时指明其位宽,方便阅读、调试。
- 例化多个相同的模块时,尽量使用 generate 语句,避免过长的例化代码描述。
(二)注释
每一个设计模块开头,都应该包含文件说明信息,包括版权、模块名字、作者、日期、梗概、修改记录等信息。例如:
/**********************************************************
// Copyright 1891.06.02-2017.07.14
// Contact with willrious@sina.com
================ runoob.v ======================
>> Author : willrious
>> Date : 1995.09.07
>> Description : Welcome
>> note : (1)To
>> : (2)My
>> V180121 : World.
************************************************************/注释应该精炼的表达出代码所描述的意义,简短的注释在一行语句代码之后添加,过长的注释提前一行书写。注释尽量用英文书写,以保证不同操作系统、不同编辑器下能够正常显示。端口信号中,除一般的时钟和复位信号,其他信号最好也进行注释
(三)关于优化
- 使用圆括号确定程序的优先级或逻辑结构。为避免操作符优先级问题导致设计错误,建议多多使用圆括号。同时,圆括号的巧妙使用有时候也会优化逻辑综合后的结构。
- 条件语句尽量使用 case 语句代替 if 语句。当同级别的条件判断语句过多时,使用 case 语句综合后的硬件结构,往往比 if 语句消耗更少的资源,拥有更好的时序。
- 状态机编写时,尽量使用 3 段式,以保证代码具有良好的整洁性和安全性。
- 系统设计时,尽量采用模块按功能分割、然后进行模块例化的方法。相比成千上万行代码都集成在一个文件中,模块分割有利于团队设计,便于更新维护。
(四)关于赋初值
变量声明时不要对变量进行赋初值操作。如果变量声明时设置初始值,仿真时变量会有期望的初值,但综合后电路的初始值是不确定的。如果信号初值会影响逻辑功能,则仿真过程可能会因验证不充分而错过查找出逻辑错误的机会。例如下面描述是不建议的:
reg [31:0] wdata = 32'b0 ;赋初值操作应该在复位状态下完成,也建议寄存器变量都使用复位端,以保证系统上电或紊乱时,可以通过复位操作让系统恢复初始状态。
建议设计时,时钟采用正边沿逻辑,复位采用负边沿逻辑。
(五)关于 always 语句
不到万不得已不要在 2 个 always 块中分别使用同一时钟的上升沿和下降沿逻辑,否则会引入相对复杂的时钟质量和时序约束的问题。
? ?//建议尽量避免 2 个 always 块 2 个时钟边沿的逻辑
? ?always?@(posedge?clk)?begin
? ? ? a?<=?b?;
? ?end
? ?always?@(negedge?clk)?begin
? ? ? c?<=?d?;
? ?end禁止在一个 always 块中同时将时钟的双边沿作为触发条件,编译、仿真可能会按照设计人员的思想进行,但此类电路往往不可综合,或综合后电路功能不会符合预期。
? ?//禁止一个 always 块中使用双边沿逻辑
? ?always?@(posedge?clk?or?negedge?clk)?begin
? ? ? a?<=?b?;
? ?end??禁止在 2 个 always 块中为同一个变量赋值,这是很多初学者容易犯的错误。
??//此设计是错误的
? ?always?@(posedge?clk)?begin
? ? ? a?<=?b?;
? ?end
? ?always?@(negedge?clk)?begin
? ? ? a?<=?d?;
? ?end一个 always 块中不要存在多个并行或不相关的条件语句,使用多个 always 分别描述。
当一个 always 语句中存在多个并行或不相关的条件语句时,仿真的执行结果或综合的实际电路中,不相关的条件语句都是并行执行的。但是仿真过程可能是顺序执行的,如果有延迟信息可能会导致不可以预知的错误结果。且该写法可读性较差,功能结构划分不明显。
? ??//不推荐
? ??always?@(posedge?clk)?begin
? ? ? ??if?(a?==?b)
? ? ? ? ? ? data_t1?<=?data1?;
? ? ? ??if?(a?==?b?&&?c?==?d)
? ? ? ? ? ? data_t2?<=?data2?;
? ? ? ??else
? ? ? ? ? ? data_t2?<=?'b0?;
? ??end
? ?
? ??//推荐分开写
? ??always?@(posedge?clk)?begin
? ? ? ??if?(a?==?b)
? ? ? ? ? ? data_t1?<=?data1?;
? ??end
? ??always?@(posedge?clk)?begin
? ? ? ??if?(a?==?b?&&?c?==?d)
? ? ? ? ? ? data_t2?<=?data2?;
? ? ? ??else
? ? ? ? ? ? data_t2?<=?'b0
? ??end(六)关于时钟与异步
设计中尽量使用同步设计。
必须要使用异步逻辑时,一定要对不同时钟域之间的信号进行同步处理,不能直接使用相关信号,否则会产生亚稳态电路。
尽量不要直接将时钟信号与普通变量信号做逻辑操作,或对时钟信号进行电平信号的检测判断。
(七)关于综合
一般情况下信号变量不要直接使用乘法?*、除法?/、求余数?%?等操作。这些操作符被综合后,结构和时序往往不易控制。应该使用相关优化后的 ip 模块或工艺库中的集成模块。但是 parameter 类型的常量就可以使用此类操作符,因为在编译之初编译器就会计算出常量运算的结果,不会消耗多余的硬件资源。
组合逻辑的条件语句中条件补充完整,组合逻辑的 always 语句中敏感信号要罗列完全,以避免不期望的 Latch 产生。
逻辑设计时要考虑代码能不能综合成实际电路,会综合成什么样的电路。
(八)关于例化
例化时,连接输入端的信号可以是 reg 型或 wire 型变量,连接输出端的信号一定是 wire 型变量。但是端口信号声明时,输入信号必须是 wire 型变量,输出信号可以是 reg 型或 wire 型变量。
多个模块例化时,模块名字在前,例化名字在后,且例化名字不能相同。

八、Verilog高级
(一)门级建模和RTL级建模
门级建模,是使用基本的逻辑单元,例如与门,与非门等,进行更低级抽象层次上的设计。与行为级建模相比,门级建模更注重硬件的实现方法,即通过连接一些基本门电路去实现多种逻辑功能。虽然行为级建模最后也会被综合成基本的门级电路网络,但对于复杂的设计来说,行为级建模的效率远远高于门级建模。所以目前 Verilog 大多数用于描述数字设计的行为级层次(RTL),一般只注重设计实现的算法或流程,而不用特别关心具体的硬件实现方式。
(二)门延迟类型
前两节中所介绍的门级电路都是没有延迟的,实际门级电路都是有延迟的。Verilog 中允许用户使用门延迟,来定义输入到其输出信号的传输延迟。门延迟类型主要有以下 3 种。
8.2.1 上升延迟
在门的输入发生变化时,门的输出从 0,x,z 变化为 1 所需要的转变时间,称为上升延迟。

8.2.2 下降延迟
在门的输入发生变化时,门的输出从 1,x,z 变化为 0 所需要的转变时间,称为下降延迟。

8.2.3 关断延迟
关断延迟是指门的输出从 0,1,x 变化为高阻态 z 所需要的转变时间。
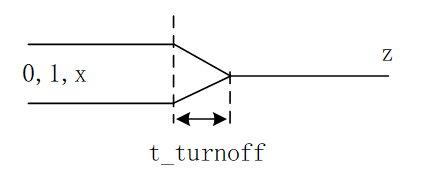
门输出从 0,1,z 变化到 x 所需要的转变时间并没有被明确的定义,但是它所需要的时间可以由其他延迟类型确定,即为以上 3 种延迟值中最小的那个延迟。
(三)锁存器和触发器
D 锁存器是一种电平触发。如果在 EN=1 的有效时间内,D 端信号发生多次翻转,则输出端 Q 也会发生多次翻转。这降低了电路的抗干扰能力,不是实际所需求的安全电路。为提高触发器的可靠性,增强电路抗干扰能力,发明了在特定时刻锁存信号的 D 触发器。
?8.3.1 触发器
将两个 D 锁存器进行级联,时钟取反,便构成了一种简单的 D 触发器,又名 Flip-flop。
第一级 D 锁存器又称为主锁存器,在 CP 为低电平时锁存。第二级 D 锁存器又称为从锁存器,时钟较主锁存器相反,在 CP 为高电平时锁存。即,D 触发器输出端 Qs 只会在时钟 CP 下降沿对 D 端进行信号的锁存,其余时间输出端信号具有保持的功能。

?(四)时序分析
静态时序分析 (Static Timing Analysis, STA),也是一种时序验证的技术。它不关心逻辑功能的正确与否,只对设计中的时序进行计算分析,来确定电路中是否存在违反 (violation) 时序约束的设计。STA 分析速度快,能够快速定位问题,但会忽略一些异步的问题。所以 "STA + 时序仿真"是一种相对完善且安全的时序验证方法。
8.4.1 延迟模型比较
- 分布延迟:分布延迟将延迟时间分散在了每一个门单元上,但仍然不能描述基本单元中不同引脚上延时的差异。当设计规模变大时,结构将变的复杂。
- 集总延迟:该方式模型简单,适用于小规模的电路,但是不能描述输入端到输出端不同路径的延迟。
- 路径延迟:指定了引脚到引脚的延迟,延迟信息比较齐全。虽然信息比较多,但对于大规模电路也更容易实现。因为设计者无需关心模块内部的实现逻辑,只需要了解输入到输出引脚的延迟即可。即便模块内部逻辑有所改变,路径延迟的说明也可以保持不变。
所以,大多数逻辑门单元库中的延迟信息,都是以路径延迟的方式给出的。很多集成模块,也可以从其数据手册中直接获取到路径延迟,十分方便。
8.4.2 建立时间和保持时间
- 建立时间就是时钟触发事件来临之前,数据需要保持稳定的最小时间,以便数据能够被时钟正确的采样。
- 保持时间就是时钟触发事件来临之后,数据需要保持稳定的最小时间,以便数据能够被电路准确的传输。
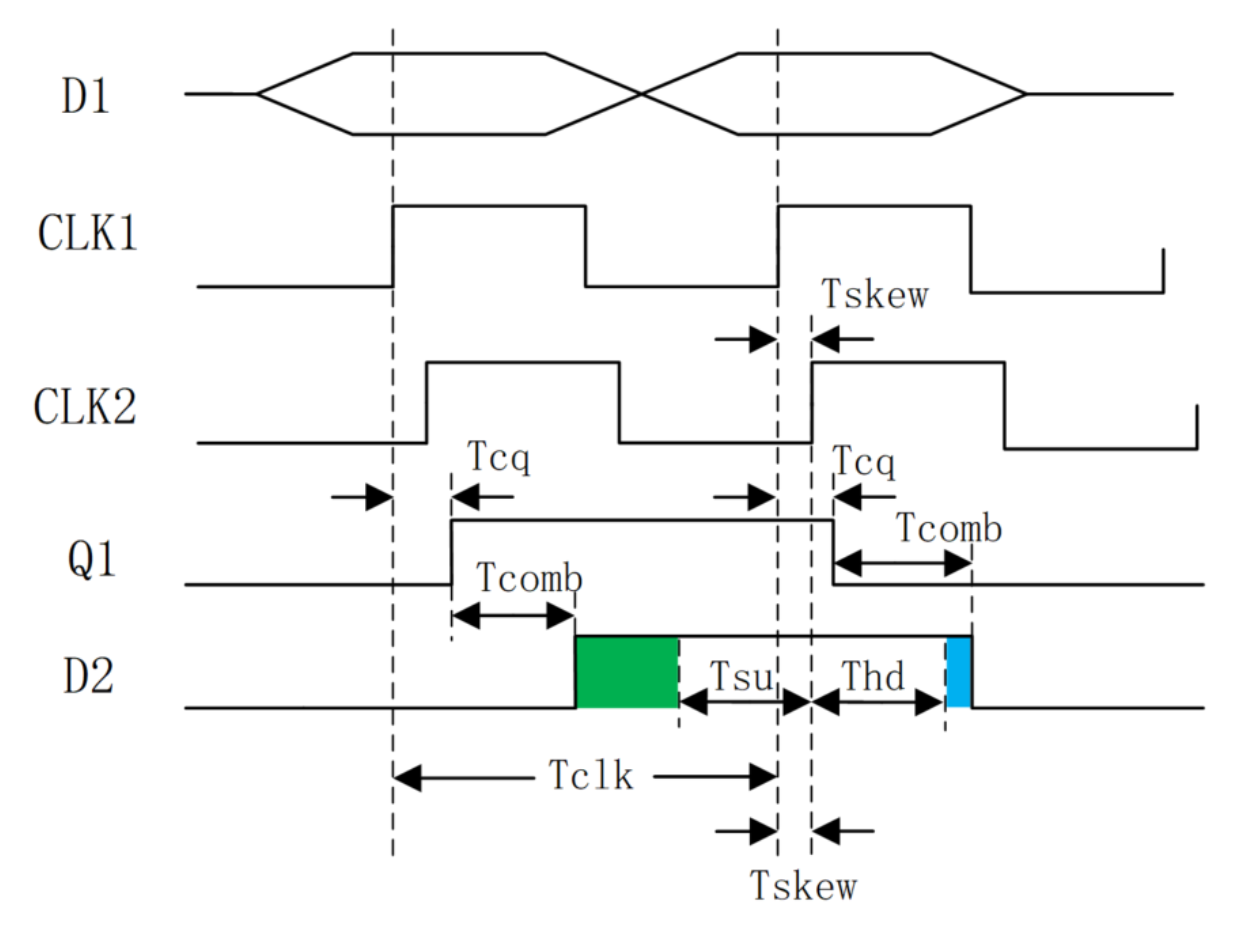
可以通俗的理解为:时钟到来之前,数据需要提前准备好;时钟到来之后,数据还要稳定一段时间。建立时间和保持时间组成了数据稳定的窗口,如下图所示。

8.4.3 建立时间约束条件
下图是一个典型的触发器到触发器之间的数据传输示意图。其中 "Comb" 代表组合逻辑延迟,"Clock Skew" 表示时钟偏移,数据均在时钟上升沿触发。

时钟到来之前,数据需要提前准备好,才能被时钟正确采样,要求数据路径 (data path) 比时钟路径 (clock path)更快,即数据到达时间(data arrival time)小于数据要求时间(data required time)。则建立时间需要满足的表达式为:
Tcq + Tcomb + Tsu <= Tclk + Tskew (1)
各个时间参数说明如下:
- Tcq: 寄存器 clock 端到 Q 端的延迟;
- Tcomb: data path 中的组合逻辑延迟;
- Tsu: 建立时间;
- Tclk: 时钟周期;
- Tskew: 时钟偏移。
对上式进行变换,则理论上电路能够承载的最小时钟周期和最快时钟频率分别为:
最小时钟周期 = Tcq + Tcomb + Tsu - Tskew
最快时钟频率 = 1 / (Tcq + Tcomb + Tsu - Tskew)
8.4.4 保持时间约束条件
时钟到来之后,数据还要稳定一段时间,这就要求前一级的数据延迟(data delay time)不要大于触发器的保持时间,以免数据被冲刷掉。则保持时间需要满足的表达式为:
Tcq + Tcomb >= Thd + Tskew (2)
各个时间参数说明如下:
- Tcq: 寄存器 clock 端到 Q 端的延迟;
- Tcomb: data path 中的组合逻辑延迟;
- Thd: 保持时间;
- Tskew: 时钟偏移。
由式 (1) (2) 可以推导出时钟偏移、组合逻辑延迟及时钟周期的约束。建议只需要记住这 2 个最基本的约束条件表达式,需要求取其他参数约束时,再进行推导,以免各种推导造成记忆混乱。
(五)同步复位和异步复位
8.5.1 同步复位
同步复位是指复位信号在时钟有效边沿到来时有效。如果没有时钟,无论复位信号怎样变化,电路也不执行复位操作。
- 同步复位的优点:信号间是同步的,能滤除复位信号中的毛刺,有利于时序分析。
- 同步复位的缺点:大多数触发器单元是没有同步复位端的,采用同步复位会多消耗部分逻辑资源。且复位信号的宽度必须大于一个时钟周期,否则可能会漏掉复位信号。
8.5.2 异步复位
异步复位是指无论时钟到来与否,只要复位信号有效,电路就会执行复位操作。
- 异步复位的优点:大多数触发器单元有异步复位端,不会占用额外的逻辑资源。且异步复位信号不经过处理直接引用,设计相对简单,信号识别快速方便。
- 异步复位的缺点:复位信号与时钟信号无确定的时序关系,异步复位很容易引起时序上 removal 和 recovery 的不满足。且异步复位容易受到毛刺的干扰,产生意外的复位操作。
(六)时钟源
8.6.1 时钟源分类
根据时钟源在数字设计模块中位置的不同,可以将时钟源分为外部时钟源和内部时钟源。
外部时钟源:
- RC/LC 振荡电路:利用正反馈或负反馈电路产生周期性变化时钟信号。此类时钟源电路简单,频率变化范围大,但工作频率较低,稳定度不高。
- 无源/有源晶体振荡器:利用石英晶体的压电效应(压力和电信号可以相互转换)产生谐振信号。此类时钟源频率精度高,稳定性好,噪声低,温漂小。有源晶振中,往往还加入了压控或温度补偿,时钟的相位和频率都有较好的特性。但电路实现相对复杂,频带较窄,频率基本不能调节。
内部时钟源:锁相环(PLL, Phase Locked Loop):
利用外部输入的参考信号控制环路内部振荡信号的频率和相位,实现输出信号频率对输入信号频率的自动跟踪,通过反馈通路将信号倍频到一个较高的固定频率。
8.6.2 时钟特性
仿真时,所有同步的时钟都是理想的:时钟的翻转是在瞬间完成的,模块之间的时钟沿都是对齐的,没有延迟,没有抖动。实际电路中,时钟在传输、翻转时都会有延迟。
时钟偏移(skew)
由于线网的延迟,时钟信号在到达触发器端口时,不能保证不同触发器端口的时钟沿是对齐的,即不同触发器端口的时钟相位存在差异。这种差异称为时钟偏移。
一般时钟偏移与时钟频率没有直接的关系,与走线长度、负载电容、负载数量等因素有关。
时钟抖动(jitter)
相对于理想时钟沿,实际时钟中存在的不随时间积累的、时而超前、时而滞后的偏移称为时钟抖动。可以用抖动频率和抖动幅度对时钟抖动进行定量描述。时钟抖动可分为随机抖动和固定抖动:
- 随机抖动的来源为热噪声、半导体工艺等。
- 固定抖动的来源为开关电源、电磁干扰或其他不合理的布局布线等。
在综合工具 Design Compiler 中,时钟的偏移和抖动统一用不确定度 uncertainty 来统一表示。
转换时间(transition)
时钟从上升沿跳变到下降沿,或者从下降沿跳变到上升沿时,并不是"直上直下"不需要时间完成电平跳变,而是"斜坡式"需要一个过渡时间完成电平跳变,这个过渡时间称之为时钟的转换时间。转换时间大小与单元库工艺、电容负载等有关。
时钟延时(lantency)
时钟从时钟源(例如晶振、PLL 或分频器输出端)出发到达触发器端口的延迟时间,称为时钟延时。时钟延时包括时钟源延迟(source latency)和时钟网络延迟(network latency)。

时钟源延时,是时钟信号从实际时钟原点到设计模块时钟定义点的传输时间。上图所示为 3ns。
时钟网络延时,是从设计模块时钟定义点到模块内触发器时钟端的传输时间,传输路径上可能经过缓冲器(buffer)。上图所示为 1ns。
时钟源延时(source latency)是设计模块内所有触发器共有的延时,所以不会影响时钟偏移(skew)。
8.6.3 时钟树
数字设计时各个模块应当使用同步时钟电路,同步电路中被相同时钟信号驱动的触发器共同组成一个时钟域。理想电路中,时钟信号会同时到达同时钟域所有触发器的时钟端。但是实际中因为各种延迟的存在,这种无延迟的时钟特性是很难实现的。而且时钟信号的驱动能力有限,难以独立的为一个包含较多的触发器的时钟域提供有效扇出。为解决时钟延迟与驱动的问题,就需要采用时钟树系统对时钟信号进行管理,来确保良好的时序和驱动能力。
时钟树,是个由许多缓冲单元 (buffer cell) 平衡搭建的网状结构。一般由一个时钟源点,经一级一级的缓冲单元搭建而成。增加 clock buffer(图中橙色三角模块) 的实际时钟树结构如下所示。
 ?蓝色的上升沿符号表示时钟的转换时间(transition),红色的实线则表示时钟延时 (latency),包含 network delay 和 source latency,绿色的虚线表示时钟不确定度(uncertainty),包括时钟偏移(skew)和时钟抖动(jitter)。
?蓝色的上升沿符号表示时钟的转换时间(transition),红色的实线则表示时钟延时 (latency),包含 network delay 和 source latency,绿色的虚线表示时钟不确定度(uncertainty),包括时钟偏移(skew)和时钟抖动(jitter)。
时钟树并不是来减少时钟信号到达各个触发器的时间,而是减少到达各个触发器之间的时间差异。一般是后端设计人员通过插入 clock buffer 完成时钟树的设计。前端设计人员,往往需要保证时钟方案与数字逻辑的功能正确性。
(七)综合
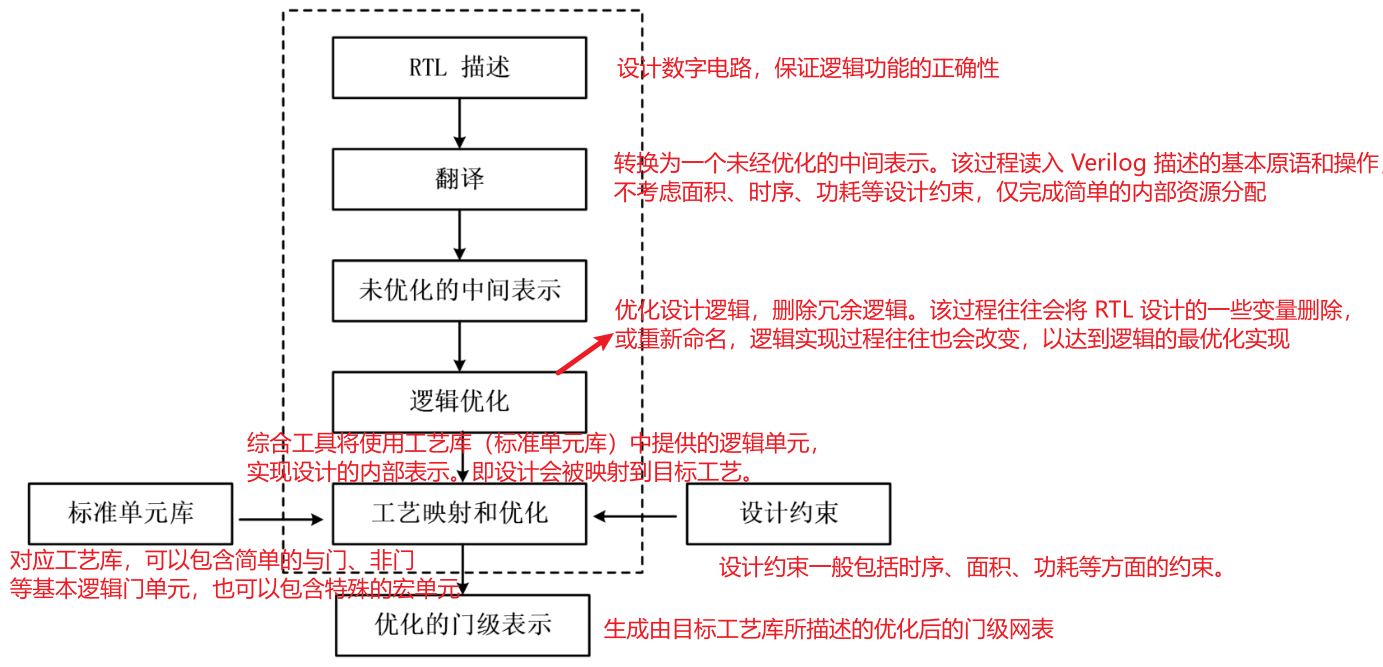
综合,就是在标准单元库和特定的设计约束基础上,把数字设计的高层次描述转换为优化的门级网表的过程。标准单元库对应工艺库,可以包含简单的与门、非门等基本逻辑门单元,也可以包含特殊的宏单元,例如乘法器、特殊的时钟触发器等。设计约束一般包括时序、负载、面积、功耗等方面的约束。
无论是数字芯片设计,还是 FPGA 开发,现在综合过程基本都是借用计算机辅助逻辑综合工具,自动的将高层次描述转换为逻辑门电路。设计人员可以将精力集中在系统结构方案、高层次描述、设计约束和标准工艺库等方面,而不用去关心高层次的描述怎么转换为门级电路。综合工具在内部反复进行逻辑转换、优化,最终生成最优的门级电路。
参考链接:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!