机器学习——朴素贝叶斯
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
????????朴素贝叶斯算法是一种基于贝叶斯理论的有监督学习算法。朴素是指样本特征之间是相互独立的,朴素贝叶斯算法有着坚实的数学基础和稳定的分类效率。
????????朴素贝叶斯算法或朴素贝叶斯分类器(Naive Bayes Classifier,NBC)发源于古典数学理论,是基于贝叶斯理论与特征条件独立假设的分类方法,通过单独考量每一特征被分类的条件概率作出分类预测。
朴素贝叶斯算法具有如下优点:
- 有坚实的数学基础以及稳定的分类效率。?
- 需要估计的参数很少,对缺失数据不太敏感,算法也比较简单。
朴素贝叶斯算法具有如下缺点
- 必须知道先验概率,因此往往预测效果不佳。
- 对输入数据的数据类型较为敏感。
1.1 贝叶斯定理
????????贝叶斯分类:?贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
????????先验概率:根据以往经验和分析得到的概率。我们用P(Y)来代表在没有训练数据前假设Y拥有的初始概率。
????????后验概率:根据已经发生的事件来分析得到的概率。以P(Y|X)代表假设X 成立的情下观察到Y数据的概率,因为它反映了在看到训练数据X后Y成立的置信度。
????????联合概率:联合概率是指在多元的概率分布中多个随机变量分别满足各自条件的概率。X与Y的联合概率表示为P(X,Y)、 P(XY) 或P(X∩Y) 。假设X和Y都服从正态分布,那么P(X<5,Y<0)就是一个联合概率,表示 X<5,Y<0两个条件同时成立的概率。表示两个事件共同发生的概率。
????????贝叶斯公式:

????????朴素贝叶斯法是典型的生成学习方法。生成方法由训练数据学习联合概率分布 P(X,Y),然后求得后验概率分布P(Y|X)。 具体来说,利用训练数据学习P(X|Y)和P(Y)的估计,得到联合概率分布:P(X,Y)=P(X|Y) P(Y)
????????贝叶斯公式示例:现有两个容器,容器一有7个红球和3个白球,容器二有1个红球和9个白球。现两个容器里任取一个红球,红球来自容器一的概率是多少?
????????假设抽出红球为事件B,选中容器一为事件A,则有
P(X) =8/20? ? ?P(Y)=1/2? ? ?P(X|Y)=7/10
按照贝叶斯公式:
P(A|B) = P(X|Y)P(Y)/P(X)
2、朴素贝叶斯分类方法
????????相对于决策树、KNN之类的算法,朴素贝叶斯算法需要的参数较少,比较容易掌握,sklearn.naive_ bayes模块提供了3种朴素贝叶斯分类方法,分别是GaussianNB函数、MultinomialNB函数和 BernoulliNB函数。其中,GaussianNB 函数是高斯分布的朴素贝叶斯分类方法,MultinomialNB函数是多项式分布的朴素贝叶斯分类方法,BernoulliNB函数是伯努利分布的朴素贝叶斯分类方法。这3个类适用的分类场景各不相同,主要根据数据类型来选择,具体如下
- GaussianNB函数适合样本特征分布大部分是连续值的情况。
- MultinomialNB函数适合非负离散数值特征的情况。
- BernoulliNB函数适合二元离散值或者稀疏的多元离散值的情况。
2.1?GaussianNB函数
Sklearn提供了GaussianNB函数用于实现高斯分布,具体语法如下:
GaussianNB(priors = True)【参数说明】参数仅有一个,priors(先验概率)
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.naive_bayes import GaussianNB
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
x, y = make_blobs(n_samples = 500, centers = 5, random_state = 8)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 8)
gnb = GaussianNB()
gnb.fit(x_train, y_train)
print('模型得分:{:.3f}'.format(gnb.score(x_test, y_test)))
x_min, x_max = x[:,0].min() - 0.5, x[:,0].max() + 0.5
y_min, y_max = x[:,1].min() - 0.5, x[:,1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
z = gnb.predict(np.c_[(xx.ravel(), yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx, yy, z, cmap = plt.cm.Pastel1)
plt.scatter(x_train[:,0], x_train[:,1], c = y_train, cmap = plt.cm.cool, edgecolor = 'k')
plt.scatter(x_test[:,0], x_test[:,1], c = y_test, cmap = plt.cm.cool, marker = '*', edgecolor = 'k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('Classifier: GaussianNB')
plt.show()【运行结果】
模型得分:0.968

2.2?MultinomialNB多项式分布
????????多项式分布的朴素贝叶斯分类方法假设特征由简单多项式分布生成,适用于描述特征次数或者特征次数比例问题,例如文本分类的特征是单词出现次数。
Sklearn提供了MultinomialNB函数用于实现多项式分布
MultinomialNB(alpha = 1.0, fit_prior = True, class_prior = None)【参数说明】
- alpha:先验平滑因子,默认为1,表示拉普拉斯平滑。
- fit_prior:是否去学习类别的先验概率,默认为True。
- class_prior:各个类别的先验概率。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, naive_bayes
from sklearn.model_selection import train_test_split
def load_data():
digits = datasets.load_digits()#加载sklearn自带digits数据集
return train_test_split(digits.data, digits.target, test_size = 0.25, random_state = 0,stratify = digits.target)
#多项式贝叶斯分类器
def test_MultinomialNB(* data):
x_train, x_test, y_train, y_test = data
cls = naive_bayes.MultinomialNB()
cls.fit(x_train, y_train)
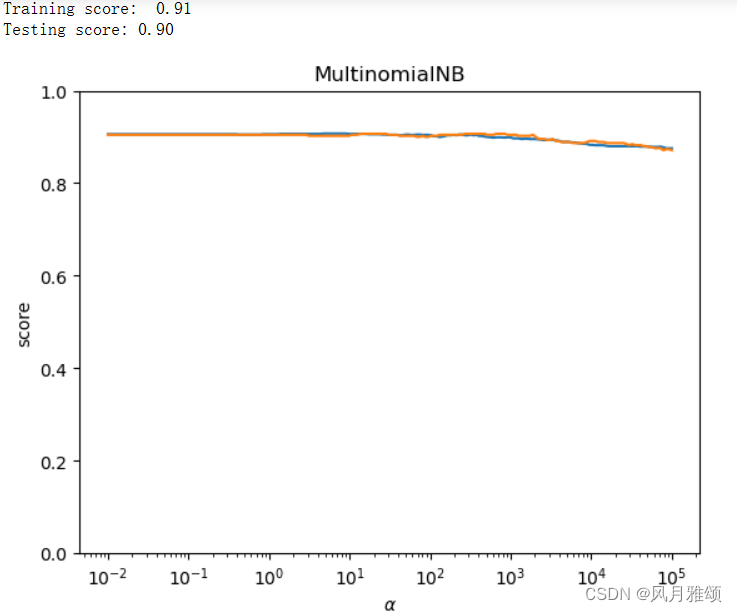
print('Training score: % .2f'% cls.score(x_train, y_train))
print('Testing score:% .2f'% cls.score(x_test, y_test))
#产生用于分类问题的数据集
x_train, x_test, y_train, y_test = load_data()
#调用test_GaussianNB
test_MultinomialNB(x_train, x_test, y_train, y_test)
#测试MultinomialNB的预测性能受alpha参数影响
def test_MultinomialNB_alpha(* data):
x_train, x_test, y_train, y_test = data
alphas = np.logspace(-2, 5, num = 200)
train_scores = []
test_scores = []
for alpha in alphas:
cls = naive_bayes.MultinomialNB(alpha = alpha)
cls.fit(x_train, y_train)
train_scores.append(cls.score(x_train, y_train))
test_scores.append(cls.score(x_test, y_test))
#绘图
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(alphas, train_scores, label = "Training Score")
ax.plot(alphas, test_scores, label = "Testing score")
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel('score')
ax.set_ylim(0, 1.0)
ax.set_title('MultinomialNB')
ax.set_xscale('log')
plt.show()
#调用test_MultinomialNB_alpha
test_MultinomialNB_alpha(x_train, x_test, y_train, y_test)【运行结果】
2.3??BernoulliNB函数
????????伯努利分布又名两点分布、二项分布或0-1分布,适用于数据集中每个特征只有0和1两个数值的情况。Sklearn提供了BernoulliNB函数以实现伯努利分布,具体语法如下:
BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)【参数说明】
- alpha:平滑因子,与多项式中的alpha一致。
- binarize:样本特征二值化的阈值,默认是0。如果不输人,模型认为所有特征都已经二值化;如果输入具体的值,模型把大于或等于该值的样本归为一类,小于该值的样本归为另一类。
- fit_prior:是否学习类别的先验概率,默认是True。
- class_prior:各个类别的先验概率。如果没有指定,模型会根据数据自动学习。每个类别的先验概率相同,等于类标记总个数的倒数。
????????BernoulliNB函数一共有4个参数,其中3个参数的名字和意义与MultinomialNB函数完全相同。唯一多出的参数是binarize,用于处理二项分布。
import numpy as np
from sklearn.naive_bayes import BernoulliNB
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
x, y = make_blobs(n_samples = 500, centers = 5, random_state = 8)
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state = 8)
nb = BernoulliNB()
nb.fit(x_train, y_train)
print('模型得分:{:.3f}'.format(nb.score(x_test, y_test)))
import matplotlib.pyplot as plt
x_min, x_max = x[:,0].min() - 0.5, x[:,0].max() + 0.5
y_min, y_max = x[:,1].min() - 0.5, x[:,1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
z = nb.predict(np.c_[(xx.ravel(), yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx, yy, z, cmap = plt.cm.Pastel1)
plt.scatter(x_train[:,0], x_train[:,1], c = y_train, cmap = plt.cm.cool, edgecolor = 'k')
plt.scatter(x_test[:,0], x_test[:,1], c = y_test, cmap = plt.cm.cool, marker = '*', edgecolor = 'k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('Classifier: BernoulliNB')
plt.show()【运行结果】
模型得分:0.544

3、案例
3.1 朴素贝叶斯分类应用于鸢尾花数据分类
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
clf = GaussianNB()
clf = clf.fit(x, y)
y_pred = clf.predict(x)
print('高斯分布的朴素贝叶斯分类。样本总数:%d;错误样本数:%d\n'%(x.shape[0], (y != y_pred).sum()))
scores = cross_val_score(clf,x,y,cv = 10)
print("Accuracy:%.3f\n"%scores.mean())【运行结果】

from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import MultinomialNB
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
clf = MultinomialNB()
clf = clf.fit(x, y)
y_pred = clf.predict(x)
print('多项式分布的朴素贝叶斯分类。样本总数:%d;错误样本数:%d\n'%(x.shape[0], (y != y_pred).sum()))
scores = cross_val_score(clf,x,y,cv = 10)
print("Accuracy:%.3f\n"%scores.mean())【运行结果】

from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import BernoulliNB
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
clf = BernoulliNB()
clf = clf.fit(x, y)
y_pred = clf.predict(x)
print('伯努利分布的朴素贝叶斯分类。样本总数:%d;错误样本数:%d\n'%(x.shape[0], (y != y_pred).sum()))
scores = cross_val_score(clf,x,y,cv = 10)
print("Accuracy:%.3f\n"%scores.mean())【运行结果】

3.2 新闻文本分类
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
#1.数据获取
news = fetch_20newsgroups(subset = 'all')
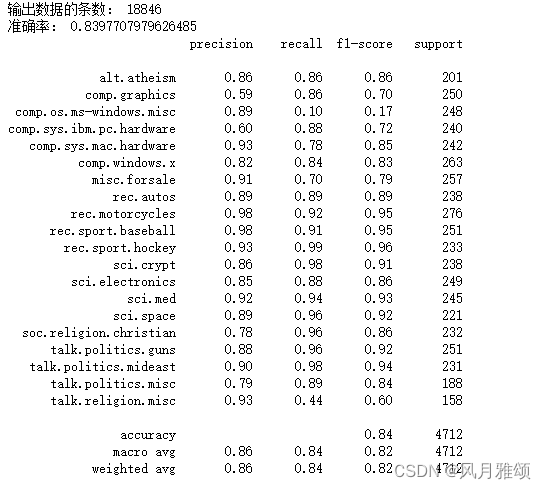
print('输出数据的条数:', len(news.data))
#2.数据预处理
#分割训练集和测试集,随机抽取25%的数据样本作为测试集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size = 0.25, random_state = 33)
#文本向量化
vec = CountVectorizer()
x_train = vec.fit_transform(x_train)
x_test = vec.transform(x_test)
#3.使用多项式分布朴素贝叶斯分类方法进行训练
mnb = MultinomialNB()
mnb.fit(x_train, y_train)
y_pred = mnb.predict(x_test)
#4.获取结果报告
print('准确率:', mnb.score(x_test, y_test))
print(classification_report(y_test, y_pred, target_names = news.target_names))【运行结果】
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!