目标检测-One Stage-YOLO v3
2024-01-08 12:17:02
前言
根据前文目标检测-One Stage-YOLOv2可以看出YOLOv2的速度和精度都有相当程度的提升,但是精度仍较低,YOLO v3基于一些先进的结构和思想对YOLO v2做了一些改进。
提示:以下是本篇文章正文内容,下面内容和可供参考
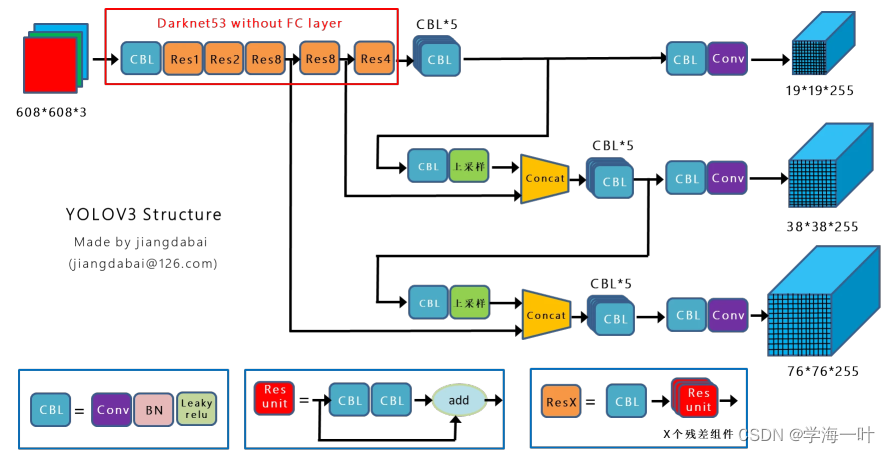
一、YOLO v3的网络结构和流程
- 将影像输入卷积网络(DarkNet53)+FPN得到多尺度特征图
ps:Darknet53,由Darknet19结合Resnet而成
- 利用anchor机制获取预选框
- 将上一步得到的anchor输入不同的分类和边框回归器
- 使用非极大值抑制NMS去除冗余窗口
二、YOLO v3的创新点
具体来说,没有什么大的创新点,但是结合先进的思想改进了YOLOv2:
- 将backbone的网络结构进行了改进,将Darknet19结合Resnet(残差块轻量化),变成了Darknet53(Darknet53的性能与ResNet152相似,速度快2倍)
- 引入多尺度特征图(feature maps),每个尺寸的feature map各司其职,13 × 13负责大目标物体,26 × 26负责中目标物体和52 × 52负责小目标物体。原因很简单,越深层的信息越抽象,越浅层的越粗糙,浅层还保留着小物体的信息,深层就不一定还在了。
ps:和SSD一样,感受野小的feature map检测小目标(较小的scale),使用感受野大的feature map检测更大目标(较大的scale),但加入了特征融合机制。
- 类别预测方面使用多个逻辑回归分类器(logistic)代替softmax分类器,以此来确定预测框属于多类的可能
- softmax(全部类别的概率之和为1)假定全部类别是互斥的,即如果预测框属于类别A,那么就不可能属于类别B
- 但面对非互斥类别集时,softmax不能判别多类别归属,比如预测框可能既属于“动物”,又属于“狗”,尤其对于Open Images这种数据集,目标可能有重叠的类别标签
- 因此yolov3使用不同的logistic回归分类器(数量和类别数对应)检验bbox为每个类别的置信度(objectness score),如果超过一定阈值,就可认为bbox属于某个类别,即可实现多类别分类
总结
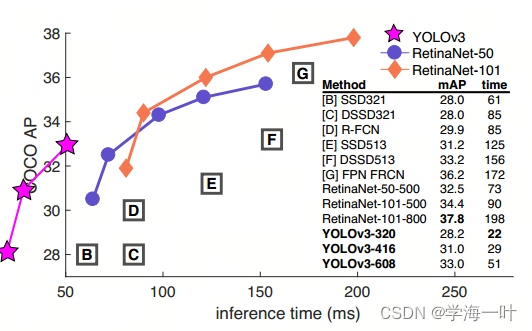
YOLOv3-320(28.2mAP)与SSD321一样准确(28.0mAP[.5, .95]),但速度快三倍(61ms -> 22ms)
在mAP50上(57.9),YOLOv3-608和当时的SOTA(RetinaNet-101-800)精度一样(57.5),但要快3.8倍(198ms -> 51ms)
文章来源:https://blog.csdn.net/long11350/article/details/135357677
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!