一些结合实例的代码理解(学习笔记)
2023-12-15 17:29:09
1、计算模型得分
#计算分类模型得分
def compute_score_with_logits(logits, labels):
#torch.max(logits,1)选择每行的最大值,返回的元组中的第一个元素是最大值,第二个元素的最大值对应的索引
#[1]取得索引,.data取得数据的张量部分
logits = torch.max(logits, 1)[1].data # argmax 找到预测的类别
#创建一个与labels大小相同的全零张量,移动到GPU(若可用),用于存储独热编码
one_hots = torch.zeros(*labels.size()).cuda()
#logits.view(-1,1)将logits张量变形为一个列向量,列数为1,-1表示自动推断该维度大小
#维度索引为1的指定位置赋值为1
#创建一个独热编码,只有预测类别对应的位置上的值为1,其他位置都为0
one_hots.scatter_(1, logits.view(-1, 1), 1)
scores = (one_hots * labels)#按元素相乘,只有对应正确类别的位置上的值保留,其他位置都是0
return scores
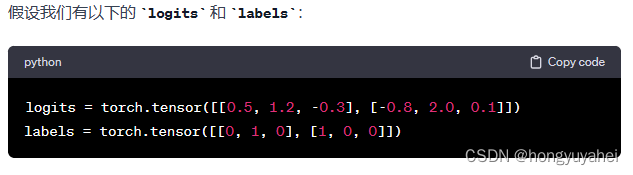

其中,scatter_()函数的用法如下:

logits = torch.max(logits, 1)[1].data
# 在第一个样本中,最大值索引为 1;在第二个样本中,最大值索引为 1
# 所以 logits 变为 tensor([1, 1])
one_hots = torch.zeros(*labels.size()).cuda()
# 创建一个与 labels 大小相同的全零张量,并将其移动到 GPU 上
one_hots.scatter_(1, logits.view(-1, 1), 1)
# 对于 logits 中的每个值,将对应位置的 one_hots 置为 1
# one_hots 变为 tensor([[0, 1, 0], [0, 1, 0]])
scores = (one_hots * labels)
# 按元素相乘,只有对应正确类别的位置上的值保留,其他位置都是 0
# scores 变为 tensor([[0, 1, 0], [0, 0, 0]])


2、交叉熵损失
import torch
import torch.nn as nn
def instance_bce_with_logits(logits, labels):
#断言确保输入的logits张量是二维的
#若logits的维度是2,则程序继续执行;否则,触发AssertionError异常,中断程序执行
assert logits.dim() == 2
#计算二分类交叉熵损失
loss = nn.functional.binary_cross_entropy_with_logits(logits, labels)
print(loss)
print(loss*labels)
loss = loss * labels.size(1)#将损失乘以真实标签的维度(通常是类别的数量),将损失值按照每个样本的平均损失进行缩放
print(loss)
return loss
if __name__ == '__main__':
logits = torch.tensor([[-1.5, 2.0, 0.5], [0.3, -0.8, 1.2]])
labels = torch.tensor([[0, 1, 1], [1, 0, 1]], dtype=torch.float32)
loss = instance_bce_with_logits(logits,labels)

文章来源:https://blog.csdn.net/hongyuyahei/article/details/135017474
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!