风控系统敏感词校验架构设计
1、写作背景
最近遇到一个需求是支持识别直播集合落地页用于广告投放,其实就是加一个规则配置。这里想到了自己经常联调的风控同学违禁词识别场景。和某明星塌房需要拦截关键词一毛一样。在联调之余有幸请教了风控的几位同学,再此学习了一下风控系统中敏感词校验的设计方案。
本文只讨论方案,不讨论技术细节。
本文只讨论方案,不讨论技术细节。
本文只讨论方案,不讨论技术细节。
方案要解决的关键点是
- 实时生效。场景:张三塌房,需要对增量的文案流量过滤张三关键词。
- 大量的关键词内存存储方案。场景:业务需求增多,关键词自然增多,很常见。
- 快速匹配违禁词。场景:用户多,词多,自然需求
2、实现思路
2.1 HelloWord级别的敏感词校验
我们以下面的DEMO为例,从0开始**,一步一步的质疑这个方案,从而实现局部最优**。
DEMO逻辑为读取数据库全量违禁词存储到内存中,流量来了以后for循环处理,校验是否命中违禁词。
package cbeann;
public class App {
public static List<String> forbiddenWordCache = cacheInit();
public static void main(String[] args) {
// controller 流量入口
String input = "关注绿豆的《云服务小管家》公众号";
for (String wordItem : forbiddenWordCache) {
if (match(input, wordItem)) {
// 命中某个规则
System.out.println(wordItem);
}
}
}
public static List<String> cacheInit() {
// 从数据库中查询违禁词集合
List<String> forbiddenWordList = Arrays.asList("绿豆", "红豆");
return forbiddenWordList;
}
// 匹配规则
public static boolean match(String input, String rule) {
// AIGC and 算法
return true;
}
}
2.2 实时生效解决方案
-
重启方案不适合大系统
对于上面的DEMO,实际上数据init一次以后就不会再加载了,如果数据中新增一个违规词,则只能通过重启服务,这个操作太重(大项目启动一次20几分钟)。 -
定时任务方案无效查询多,时效性差
实际上这种新增的场景并不是很多,所以我们可以搞一个定时任务,每几小时重新拉一下DB。这种方案也有一个弊端,如果周期小频繁查询全量数据,DB压力大,无效查询居多(基本不变);如果周期大我联调或者真生产环境要瞬间加违禁词,时效性差。
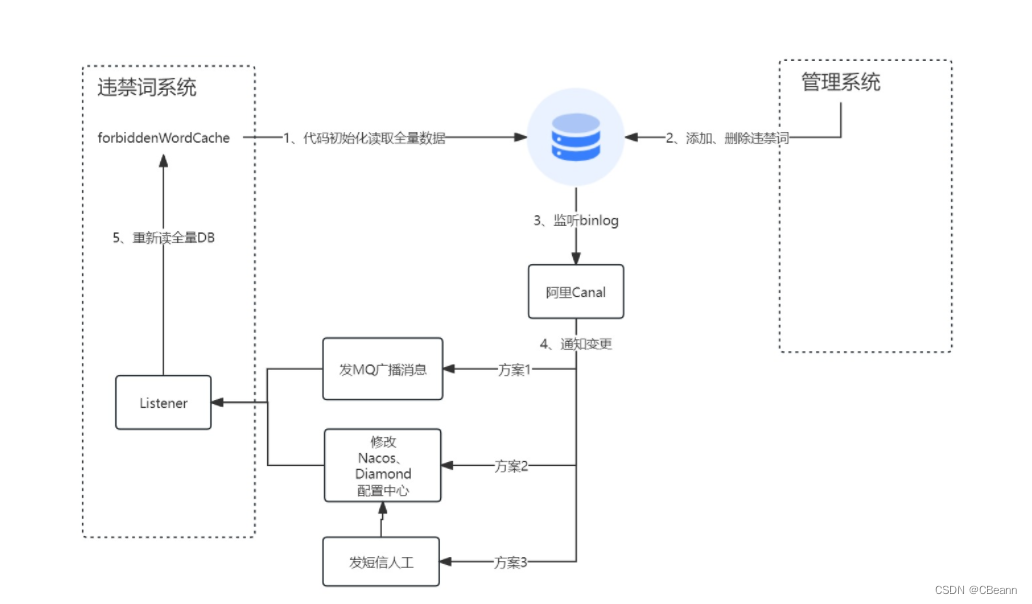
终极方案:新增或者删除以后【自动或者人工】感知到这种变更,然后变更通知到系统中的Listener,重新读取全量的数据。整体链路如下:
- 项目启动加载全量违禁词
- 运营添加删除违禁词
- Canal中间件捕捉变更
- 通知变更。发送MQ广播消息是让所有机器都能消费;自动修改配置中心让其触发Listener;或者发短信让开发人员触发Listener
- Listener更新缓存。这里要注意,因为是集群,此时会同时发送大量的慢SQL,要在Listener加随机数防止打挂DB。
2.2 大量关键词存储方案
首先明确一点,这些违禁词一定会存储到内存里,因为你需要for循环呀。
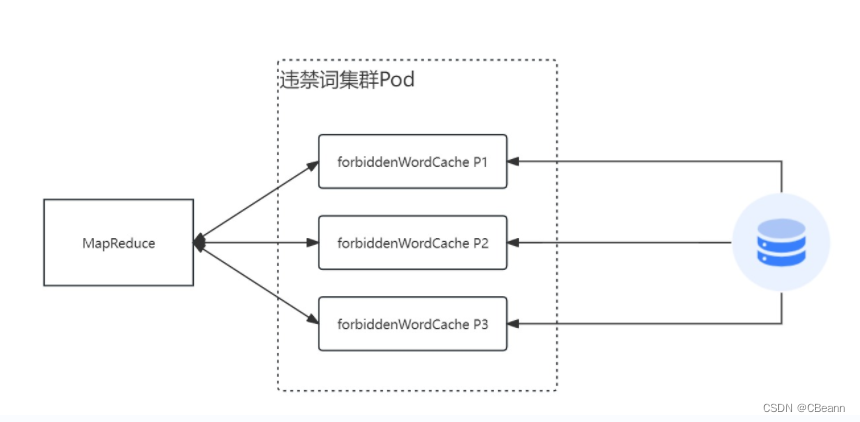
但是随着业务的增长,必然会存在大量的违禁词,此时都存内存必然放不下。所以切片。
当一个流量来了以后,此时会把这个流量分配给多个POD节点,最后在主节点进行聚合,从而实现大量关键词存储内存中的解决方案。
那么切片的规则是什么?看下面的快速匹配违禁词
2.3 快速匹配违禁词
Trie 树(前缀树)可以用于高效的解决关键词匹配问题。上面的切片规则可以根据开始的第一个字进行切分。
详情可参考Trie 树原理及其敏感词过滤的实现
3、总结
- 整个链路可以不实现,但是方案要完整;系统可以不用,但是要做。两句都对。
- 数据结构还是有用的,此处使用了Trie 树(前缀树)
- 真实的设计方案,场景可遇不可求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!