springboot实现OCR
2024-01-03 16:39:34
1、引入依赖
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>2、config
@Configuration
public class TessOcrConfiguration {
@Bean
public Tesseract tesseract() {
Tesseract tesseract = new Tesseract();
// 设置训练数据文件夹路径
tesseract.setDatapath("D:/tessdata");
// 设置为中文简体
tesseract.setLanguage("chi_sim");
return tesseract;
}
}3、定义api
@PostMapping(value = "/ocr", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public String ocr(@RequestParam("file") MultipartFile file) throws TesseractException, IOException {
return weChatService.ocr(file);
}4、定义service
@Resource
private Tesseract tesseract;
@Override
public String ocr(MultipartFile file) throws TesseractException, IOException {
InputStream sbs = new ByteArrayInputStream(file.getBytes());
BufferedImage bufferedImage = ImageIO.read(sbs);
return tesseract.doOCR(bufferedImage);
}5、将官方的简体中文训练数据(后缀为.traineddata的文件)放到配置的目录(D:/tessdata)下
下边是官方训练数据的下载地址,打开后可以找到简体中文的文件 chi_sim.traineddata,下载下来放到指定位置就可以了
tess4j官方训练数据下载![]() https://digi.bib.uni-mannheim.de/tesseract/tessdata_fast/6、测试效果
https://digi.bib.uni-mannheim.de/tesseract/tessdata_fast/6、测试效果
测试图片

postman调用
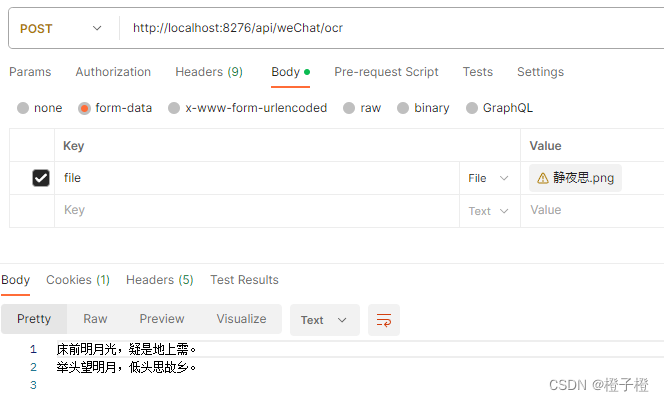
可以发现【霜】被识别成了【需】,说明还是有一定的误差
文章来源:https://blog.csdn.net/baidu_35760874/article/details/135363724
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!