产品经理应该懂的人工智能知识
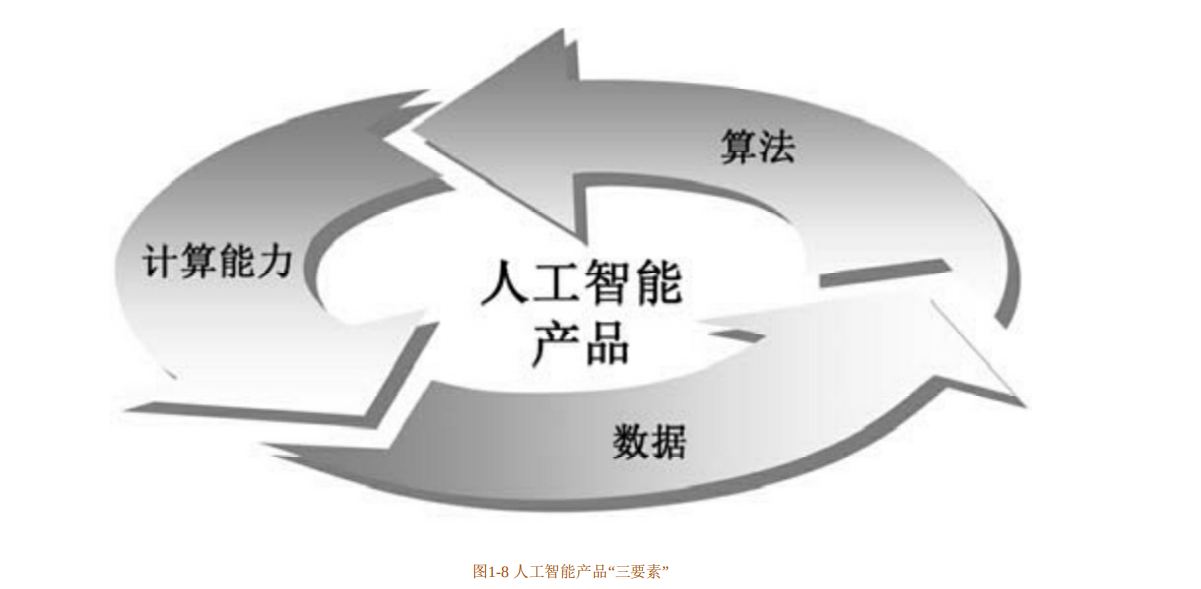
一、 人工智能产品“三要素”
算法、数据、计算能力是人工智能产品的三要素。
二、人工智能产品的应用
人工智能普遍应用的产品或服务可分为三大类:
第一类是语音和文字处理,例如人工智能写新闻稿、机器人客服等;
第二类是图像和视觉,例如自动驾驶、医疗影像诊断、机器人分拣、人脸识别等;
第三类是大数据分析和预测,例如交互搜索引擎、智能推荐引擎、金融风控,健康风险管理系统等。
三、 机器学习处理过程
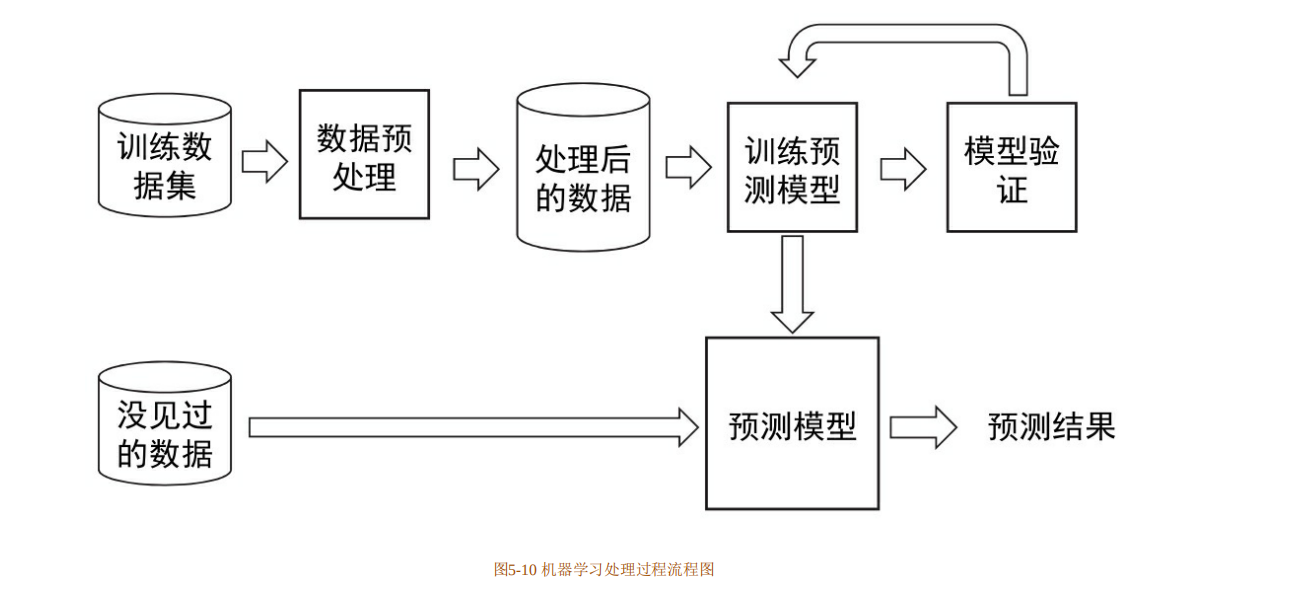
(1)原始数据采集
原始数据作为机器学习过程中的输入来源是从各种渠道中被采集而来的。在监督学习的场景中还需要对数据进行标记,例如训练自动驾驶模型时不仅需要汽车行进中的路况图像数据,而且需要标记图像中的汽车、行人、街道指示牌等。再如,情感分析模型需要用标签标记,来帮助算法理解人类使用的俚语或讽刺挖苦的表达方式。有时数据标记的工作往往非常耗时耗力,在某些场景中的标记工作不仅对人的专业背景有较高要求,而且完成标记所需的周期极长(例如精准医疗领域中通过X光片进行疾病预测),因此研究人员正在努力研究可以实现自动标记数据的工具。
(2)数据预处理
训练数据(输入数据)的“质”和“量”从某种意义上决定了机器学习的成败,但是原始训练数据的质量常常无法满足训练要求,例如原始数据具有不完整、嘈杂、不一致等缺陷,因此需要经过数据预处理过程才能将原始数据变成有效的训练数据集。机器学习的数据预处理与普通的数据挖掘过程中的预处理流程和侧重点不同,而且不同的机器学习场景对数据进行预处理的方式也不同。例如普通数据挖掘中的预处理概念就比较宽泛,包括数据清洗、数据集成、数据转换、数据削减、数据离散化等。而深度学习中数据预处理的过程主要包含数据归一化(包括样本尺度归一化、逐样本的均值相减、标准化)和数据白化。另外,在预处理阶段我们还需要将数据分为三种数据集,包括用来训练模型的训练集(Training Set),开发过程中用于调参(Parameter Tuning)的验证集(Validation Set)以及测试时所使用的测试集(Test Set)。
(3)模型训练
在正式开始模型训练之前,需要针对我们的训练目标进行分类。理解目标的本质对选择训练(学习)的方式至关重要,机器学习可以实现的目标可以被分为:分类、回归、聚类、异常检测等。前期算法工程师需要通过测试集和训练集,在几种可能的算法上做一些 Demo(样本)测试,再根据测试的效果选择具体的算法。这样可以避免后期由于大范围的模型训练策略改动而带来的损失。选择好训练(学习)方式后就可以正式开始模型训练了。
(4)模型评估(Evaluation)
接下来,是时候看看训练后的模型质量了。我们利用在第(2)步数据预处理中准备好的测试集(Test Set)对模型进行测试,由于测试集的数据对于模型来说是从没见过的,因此可以客观地度量模型在现实世界中的表现情况。模型的效果通常用“拟合程度”来形容,例如某个图片识别的任务中模型训练后的误差率与人类的平均误差率只相差1%,然而测试集误差比训练集误差高了10%,这就意味着模型在全新的(没见过)的数据上表现很不好,因此我们可以判断这个模型过拟合(Overfitting)了。而如果训练模型的误差和人类误差相比差别很大,那么说明模型的效果比较失败,可能要重新调整整个流程。过拟合通常是因为模型过度地学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,从而导致模型泛化能力较差。模型复杂程度、参数、特征数以及训练数据的选取,都可能是导致过拟合现象的原因。
(5)调参(Parameter Tuning)
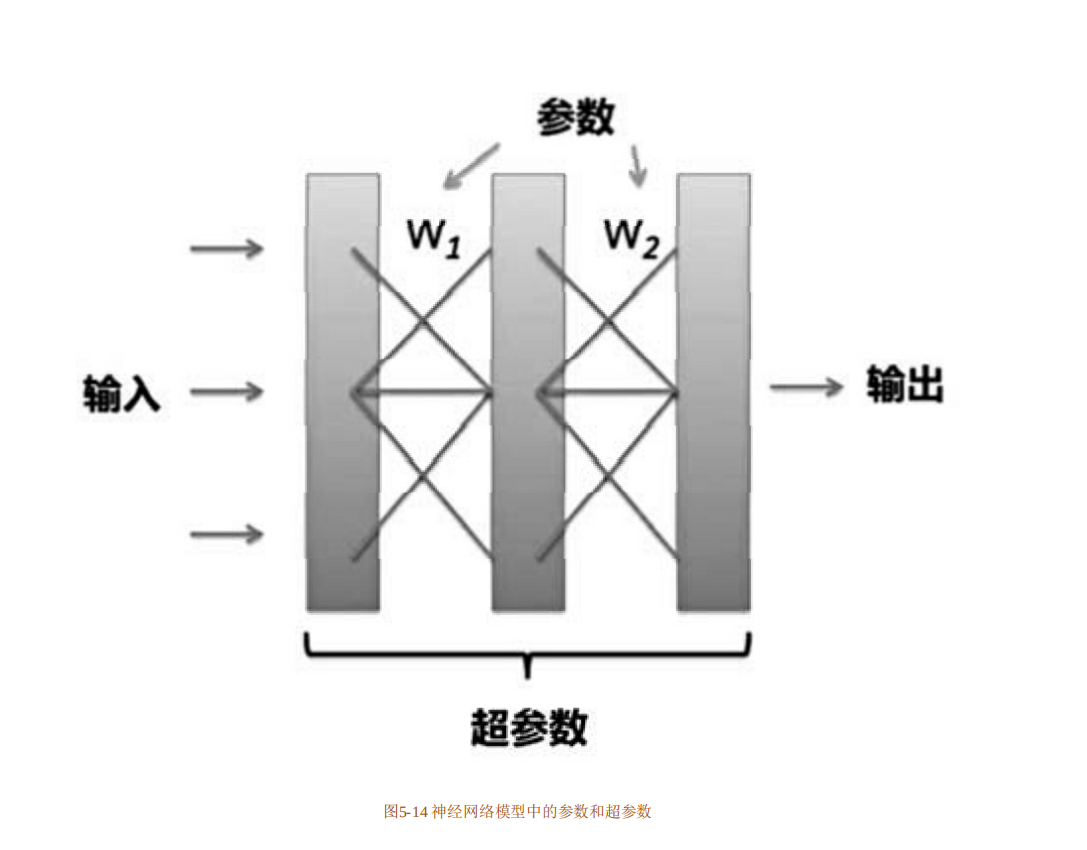
对模型的评估结束后,可以通过调参的手段对训练(学习)过程进行优化。参数可以分为两类,一类是需要在训练(学习)之前手动设置的参数,即超参数(Hyperparameter),另外一类是通常不需要手动设置、在训练过程中可被自动调整的参数(Parameter)。在一个神经网络模型中阐释两者区别如图5-14所示。权重W就是参数,层数就是超参数。
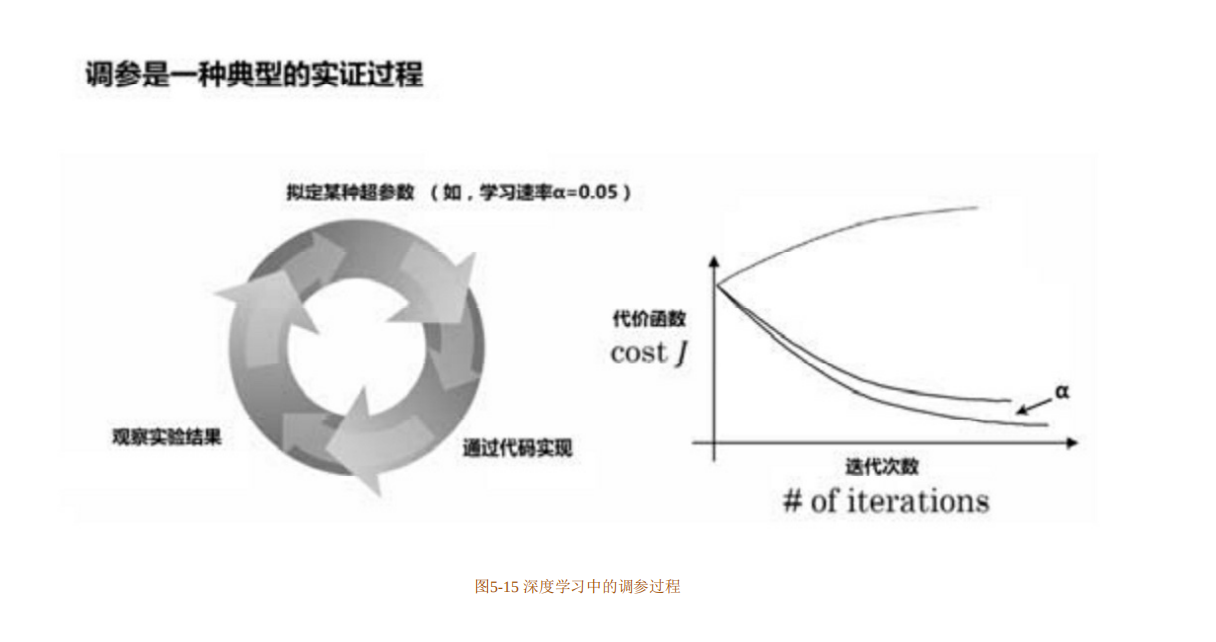
调参的过程,是一种基于数据集、模型和训练过程细节的实证过程,图5-15描述了一个典型的深度学习调参流程,通过调试不同超参数(在这个例子中调试的是学习速率)的值来测试模型效果,直到找到能够实现最低代价函数J的超参数。调参通常需要依赖经验和灵感来探寻其最优值,本质上更接近艺术而非科学,因此调参也是考察算法工程师能力高低的重点环节。
(6)推断(Inference)
机器学习的目标是利用数据来回答某种问题,因此推断或预测是机器学习回答问题的关键一步,同时也是机器学习价值体现的重要环节。
四、机器学习常用算法类型
分类算法(Classification)
分类算法用于将数据点划分到不同的类别中,预测一个或多个离散变量的取值。分类算法的目标是找到一个最佳的决策边界,使得该边界可以在训练数据上最大化正确分类的数量,并在测试数据上具有良好的泛化能力。常见的分类算法包括逻辑回归、决策树和支持向量机等。
分类尝试确定输入数据所属哪个类别,分类通常是一个监督训练操作,这意味着是用户向神经网络提供数据和期望的结果。对于数据分类,期望结果是确定这个数据类。
回归算法(Regression)
回归问题通常被用来预测具体的数值而非分类。除了返回的结果不同,其他方面与分类问题相似。我们将定量输出,或者连续变量预测称为回归;将定性输出,或者离散变量预测称为分类。例如,天气预报预测天气类型的问题是分类问题,而预测明天的温度、湿度、PM2.5指数就是典型的回归问题。
聚类算法(Clustering)
聚类是一个典型的无监督。聚类的目标就是发现数据的潜在规律和结构。聚类通常被用作描述和衡量不同数据源间的相似性,并把数据源分类到不同的簇中。例如社交软件根据用户的兴趣爱好以及在线行为数据对社交人群进行划分,就是一个典型的聚类问题。
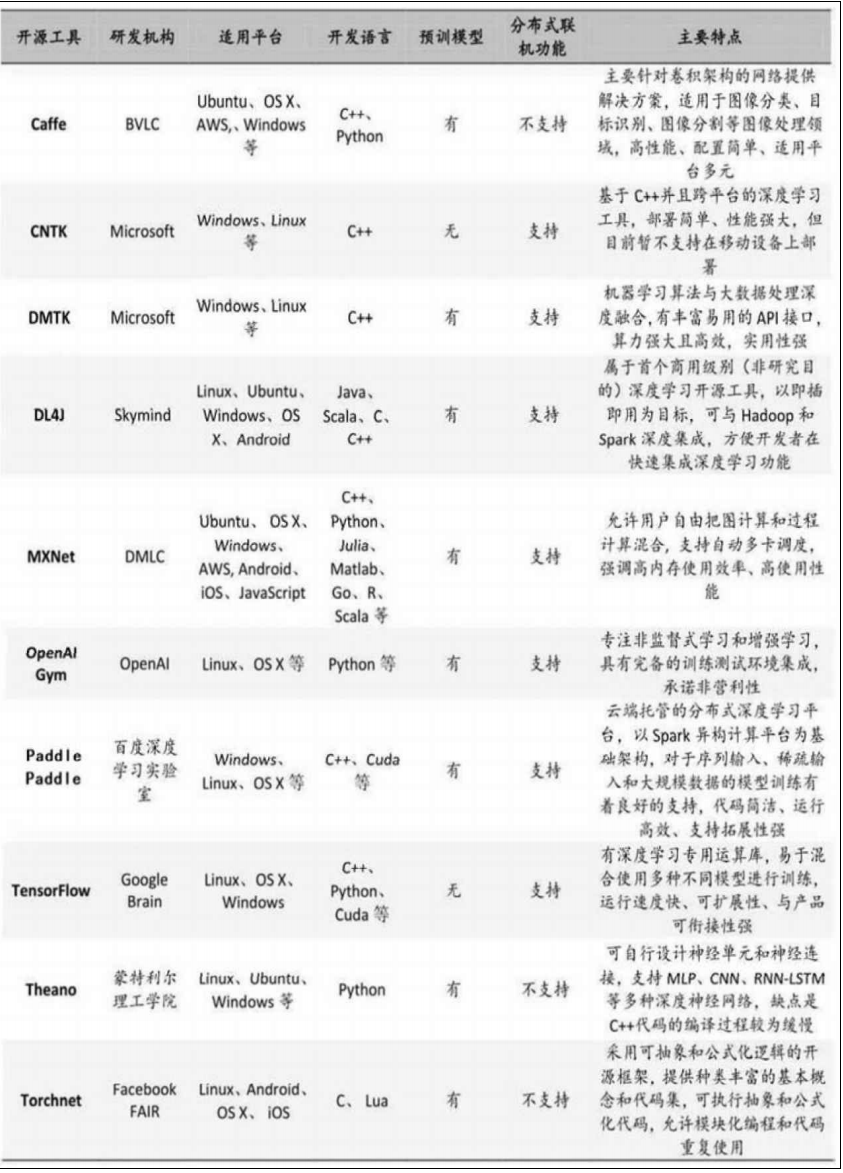
五、机器学习开发平台汇总
机器学习平台为开发者提供一站式软件服务,包括构建机器学习模型的各种部件,支持实时管理配置功能,并可以实现对接各种底层硬件架构。每个框架都有各自的优点,没有最好的,只有最适合的。考虑到平台间的迁移成本较高,包括代码转移和人员培训学习等,企业应针对公司内部的产品定位和开发人员的知识、技能储备,慎重选择最适合的开发平台,避免频繁的平台更替。
参考:《人工智能产品经理:AI时代PM修炼手册》
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!