Gemini 语言能力深度剖析 [译]
原文:An In-depth Look at Gemini's Language Abilities
摘要
Google 最近发布的 Gemini 系列模型首次全面展示了在多种任务上能与 OpenAI 的 GPT(生成式预训练转换器)系列相匹敌的性能。本文深入探讨了 Gemini 的语言处理能力,并做出两项重要贡献。首先,我们提供了一个第三方的客观比较,分析了 OpenAI 的 GPT 与 Google 的 Gemini 模型的能力,这一比较包括可复现的代码和完全透明的结果。其次,我们深入分析了实验结果,找出了两种模型类别的优势所在。我们针对 10 个数据集进行了分析,测试了包括推理、回答知识性问题、解决数学问题、进行语言翻译、代码生成和作为遵循指令的 AI 智能体等多种语言能力。通过这项分析,我们发现 Gemini Pro 的准确度虽接近,但略低于对应的 GPT 3.5 Turbo,在我们所评估的所有任务中均是如此。我们还提供了一些导致这种次优表现的原因,包括在处理多位数字的数学推理上的不足、对多项选择题答案排序的敏感性、过于严格的内容过滤等问题。同时,我们也发现了 Gemini 在某些方面的高效表现,例如生成非英语内容以及处理更长、更复杂的推理链条。相关代码和数据的复制可以在此链接找到:https://github.com/neulab/gemini-benchmark。
1 引言
Google DeepMind 最近发布了其大语言模型系列中的最新成员——Gemini(Gemini 团队,2023)。这款模型格外引人注目,原因在于 Gemini 团队报告的成果首次在众多任务上与 OpenAI 的 GPT 模型系列媲美(Brown 等人,2020)。具体而言,Gemini 的“Ultra”版本在许多任务上表现超越了 GPT-4,而其“Pro”版本则与 GPT-3.5 不相上下(Gemini 团队,2023)。然而,由于详细的评估方法和模型预测尚未公开,这限制了对其结果及其影响的复制、检验和深入分析。
在本文中,我们深入探究了 Gemini 在语言理解和生成方面的能力,目的有二:
-
我们希望提供一个第三方客观的比较,通过可复制的代码和完全透明的结果,对比 OpenAI GPT 和 Google Gemini 这两类模型的性能。
-
我们致力于深入分析实验结果,找出这两类模型中哪一类在特定领域表现更加出色。
此外,我们还简要比较了最近推出的 Mixtral 模型,以此作为一个优秀开源模型的参考(Mistral AI 团队,2023)。
我们在 10 个数据集上进行了分析,旨在测试多种文本理解与生成技能。这包括模型在回答知识型问题方面的能力(如 MMLU;Hendrycks et al. (2021))、进行推理能力(如 BigBenchHard;Suzgun et al. (2022))、解决数学问题(例如 GSM8K;Cobbe et al. (2021))、进行语言翻译(例如 FLORES;Goyal et al. (2022))、自动生成编程代码(如 HumanEval;Chen et al. (2021)),以及扮演遵从指令的 AI 智能体(WebArena;Zhou et al. (2023b))。1
我们的主要研究成果总结见于 表 1。简而言之,截至 2023 年 12 月 18 日,Gemini 的 Pro 模型在各项任务上的准确度与 OpenAI 最新版 GPT 3.5 Turbo 相似,但略有不及。下文将详细介绍我们的实验方法 (第 2 节),并对各任务的结果进行深入分析。每项任务的分析都配有一个在线结果展示工具,使用 Zeno (Cabrera et al., 2023),2 该工具可通过本文档中的 图标访问。所有的研究结果和复现代码均可在 GitHub - neulab/gemini-benchmark 查看。
| Model | |||||
| 任务 | 数据集 | Gemini Pro | GPT 3.5 Turbo | GPT 4 Turbo | Mixtral |
| 基于知识的问答 (Knowledge-based QA) | MMLU (少样本) | 64.12 | 67.75 | 80.48 | - |
| MMLU (CoT) | 60.63 | 70.07 | 78.95 | - | |
| 推理 (Reasoning) | BIG-Bench-Hard | 65.58 | 71.02 | 83.90 | 41.76 |
| 数学 (Mathematics) | GSM8K | 69.67 | 74.60 | 92.95 | 58.45 |
| SVAMP | 79.90 | 82.30 | 92.50 | 73.20 | |
| ASDIV | 81.53 | 86.69 | 91.66 | 74.95 | |
| MAWPS | 95.33 | 99.17 | 98.50 | 89.83 | |
| 代码生成 (Code Generation) | HumanEval | 52.44 | 65.85 | 73.17 | - |
| ODEX | 38.27 | 42.60 | 46.01 | - | |
| 机器翻译 (Machine Translation) | FLORES (零样本) | 29.59 | 37.50 | 46.57 | - |
| FLORES (少样本) | 29.00 | 38.08 | 48.60 | - | |
| Web Agents | WebArena | 7.09 | 8.75 | 15.16 | 1.37 |
表 1: 我们基准测试的主要结果。最佳模型以粗体显示,第二佳模型以下划线表示。Mixtral 只在部分任务上进行了评估。
2 实验设置
在讨论评估结果和发现之前,本节描述了我们的实验配置,包括测试的模型、模型查询细节和评估程序。
2.1 测试的模型
在这项工作中,我们比较了 4 种模型。
Gemini Pro
Gemini Pro 是 Gemini 系列中第二大的模型,仅次于系列中最大的 Gemini Ultra 3。该模型采用了 Transformer(Vaswani 等人,2017)架构,通过视频、文本和图像的多模态训练。其参数数量和训练数据规模未向外界公开。根据 Google 的原始论文报道,Gemini Pro 的性能与 GPT 3.5 Turbo 相媲美。
GPT 3.5 Turbo
OpenAI 提供的 GPT 3.5 Turbo 是第二强大的文本模型,属于 GPT-3 系列(Brown 等人,2020)。该模型经过特别的指令调整,并通过人类反馈强化学习进行训练(Ouyang 等人,2022),专注于文本处理。关于其模型规模和训练细节,详情未予公开。
GPT 4 Turbo
GPT 4 Turbo,作为 GPT-4(OpenAI,2023)家族的第二代产品,是一个多模态训练的模型系列。它的成本相较于原版 GPT-4 更低,更适合用于性能基准测试,但关于具体的训练算法、数据及参数规模的详细信息同样未公开。
Mixtral
与此相对的是,Mixtral 是一款开源的混合专家模型(mixture-of-experts model),包含八个各具 7B 参数的模型(Mistral AI 团队,2023)。据报告,Mixtral 在包括本文中检验的几项任务上,达到了与 GPT 3.5 Turbo 相当的准确度。
| 语言模型 | 输入费用 | 输出费用 |
|---|---|---|
| Gemini Pro | $1.00 | $2.00 |
| GPT-3.5 Turbo | $1.00 | $2.00 |
| GPT-4 | $10.00 | $30.00 |
| Mixtral | $0.60 | $0.60 |
表 2:? 每 100 万 Token 的价格。Gemini Pro 按字符计费;我们根据每个英文 Token 平均含 4 个字符的规则进行换算(Raf, 2023)。
2.2 模型查询细节
所有模型的查询都是通过 LiteLLM4 提供的统一接口,在 2023 年 12 月 11 日至 15 日期间完成的。Gemini 模型通过 Google Vertex AI 进行查询,OpenAI 的模型通过 OpenAI API 进行,而 Mixtral 则通过 Together.5 提供的 API 进行。此外,我们还列出了通过这些接口对每个模型每 100 万 Token 的当前定价情况,这一数据在 表 2 中,可作为衡量模型运行成本效率的一个参考。
值得一提的是,Gemini Pro 在某些情况下会屏蔽一些问题,尤其是那些涉及潜在非法或敏感内容的问题。在测试中,部分回答因此被屏蔽,我们将这些情况视为错误回答。对于那些屏蔽回答数量较多的任务,我们将在相应的章节中进行讨论。
2.3 评估流程
为了确保模型间的公平比较,我们对所有评估模型采用了完全一致的提示和评估协议重新进行了实验。此举旨在保证所有模型在相同的基础上进行比较,这与以往研究中常见的不同实验设置形成了对比。我们通常遵循标准资源库中提供的提示和评估方式,这些可能是由数据集官方发布的,或来自 Eleuther 的评估框架(Gao et al., 2023a)。这些提示一般包含问题、输入以及少数样本示例,有时还会加入如“连锁思考推理”这类方法(Wei et al., 2022)。在某些情况下,我们对标准实践稍作调整,以确保所有模型得到稳定评估;所有此类调整都已在下文中说明,并在相应的代码库中实现。
3 基于知识的问答
在这个分类中,我们专注于 MMLU (Hendrycks et al., 2021) 提供的 57 个基于知识的多选问答任务,这些任务涉及 STEM、人文学科、社会科学等多个领域。MMLU 被广泛应用于全面评估大语言模型 (LLMs) 在知识型任务上的能力。总共包含 14,042 个测试样本。
3.1 实验详情
生成参数
在这项任务中,我们评估了两种流行的评估方法,其中包括 Hendrycks 等人(2021)提出的标准五次尝试(5-shot)提示和 Fu 等人(2023)在 chain-of-thought-hub6 中提出的五次尝试链式思考(5-shot chain-of-thought)提示,其前缀为“Let’s think step by step.”(Kojima 等人,2022)。需要注意的是,我们没有像 Gemini Team (2023) 那样采用多次响应采样和基于自我一致性的重排方法,因为这会大幅增加成本,在很多情况下可能不切实际。我们采用了温度为零的贪婪搜索策略来生成响应。
评估
对于标准提示方法,我们直接使用模型生成的第一个字符作为其答案,因为这是五次尝试提示的预设。但有时模型可能不遵循这一格式,而是在其他位置给出答案。这种情况我们会视为错误(我们将在下一节进一步讨论这一点)。至于链式思考提示,我们会从模型的响应中提取答案,如果无法提取答案,我们会默认答案为“C”,正如 chain-of-thought-hub 所做的那样。
3.2 结果与分析
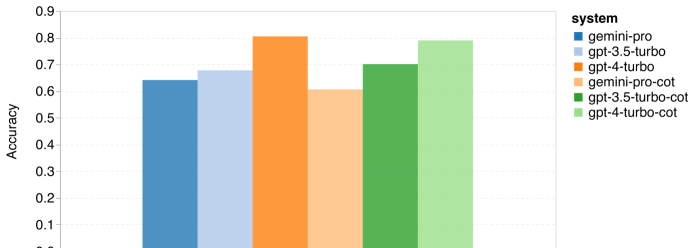
图 1: 在 MMLU 上使用 5-shot 提示和思路链提示的整体准确率
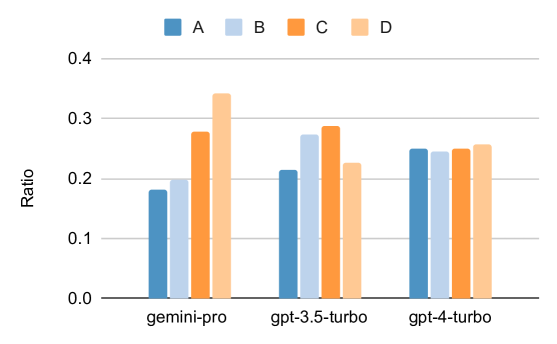
图 2: 模型对多项选择答案的预测比例
本节中,我们将对 MMLU 的整体性能、各子任务的表现以及不同输出长度下的表现进行比较分析。
首先,从 图 2 的总体结果来看,Gemini Pro 的准确率低于 GPT 3.5 Turbo,并且比 GPT 4 Turbo 低很多。使用思路链式提示对性能的提升不大,这可能是因为 MMLU 主要是基于知识的问答任务,对于更强的面向推理的提示可能收益不大。
在这个总体结果的基础上,我们更深入地分析了一下。一个显著的发现是,MMLU 中所有问题都是四选一的多项选择题,答案从 A 到 D 排列。在 图 2 中,我们展示了各模型选择每个选项的频率。可以看出,Gemini 在选择“D”项时存在明显偏好,与更加均衡的 GPT 模型形成鲜明对比。这暗示了 Gemini 在解决多项选择题方面可能未经过充分的指令调优,这可能导致模型在答案排序上有偏差(Tjuatja 等人,2023)。
最后,我们分析了各个子任务的表现。图 3 展示了不同模型在特定任务上的表现。可以看到,与 GPT 3.5 相比,Gemini Pro 在大多数任务上表现较差。思路链式提示有助于减少不同子任务间的表现差异。
在进一步的研究中,我们分析了 Gemini Pro 在哪些任务上表现不及或超过 GPT 3.5。根据图 4,我们发现 Gemini Pro 在如人类性学 (社会科学)、逻辑学 (人文学科)、初等数学 (STEM) 以及医学专业 (专业领域) 等方面表现不如 GPT 3.5。在两项 Gemini Pro 比 GPT 3.5 Turbo 表现更好的任务中,其优势微小。
Gemini Pro 在特定任务上的欠佳表现主要由两个因素造成。首先,正如之前在小节 2.2中提到,Gemini 在某些情况下无法提供答案。在大部分 MMLU 子任务中,API 的响应概率超过 95%,但在道德情境和人类性学任务中,响应概率分别仅为 85% 和 28%,这表明某些任务的低表现可能与输入内容的筛选机制有关。其次,Gemini Pro 在解决逻辑学和初等数学任务所需的基础数学推理方面略显不足,我们将在第 4 节中进一步分析。
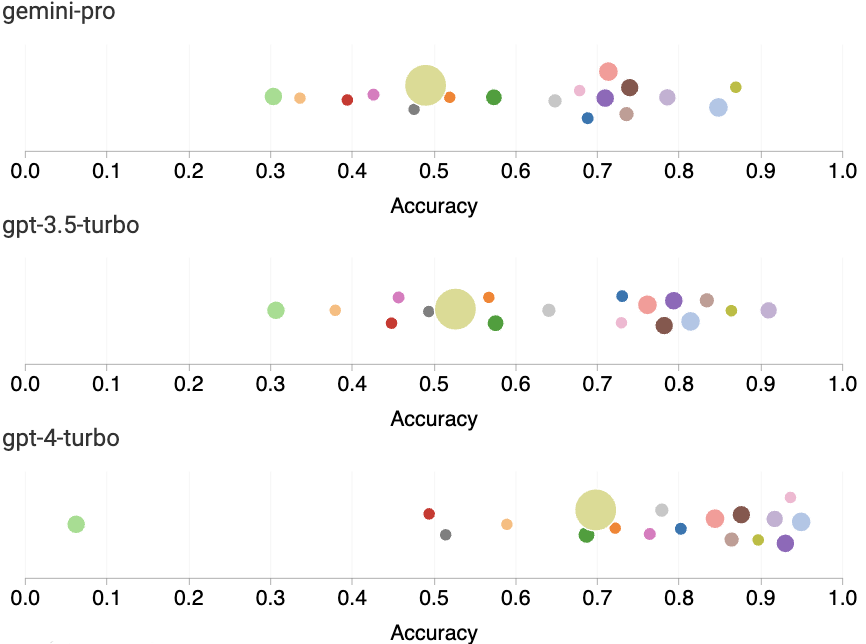
图 3:MMLU 各子任务的准确率
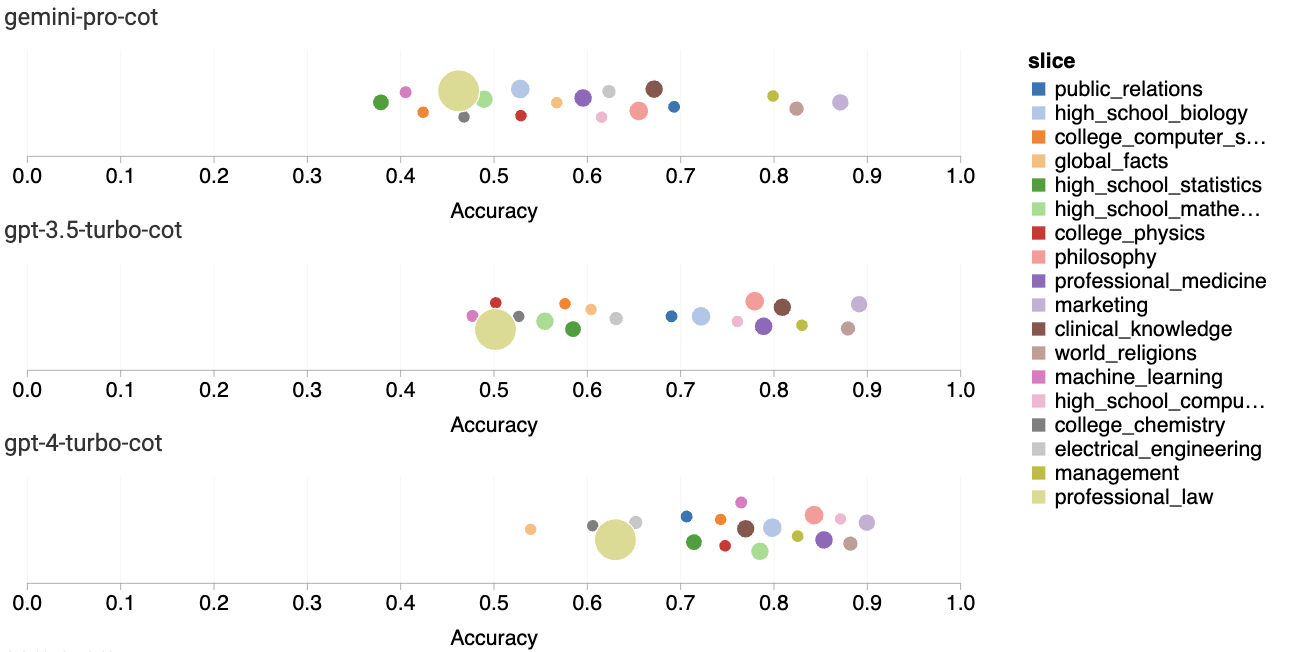
图 3:MMLU 各子任务的准确率
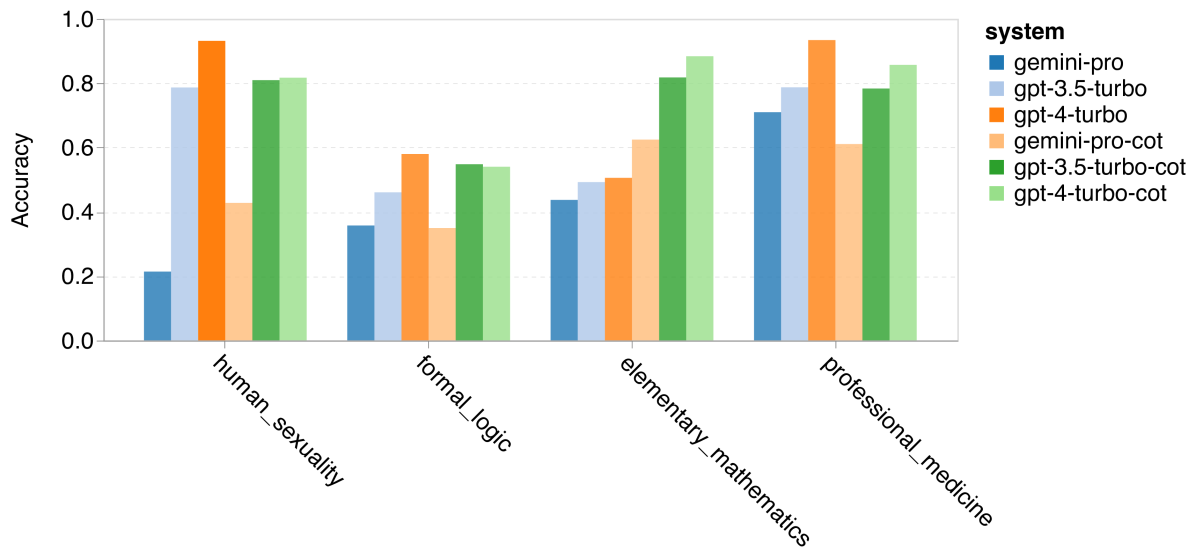
图 4:Gemini Pro 与 GPT 3.5 在 MMLU 任务中的表现对比 (a)GPT 3.5 在四项主要任务中胜过 Gemini Pro
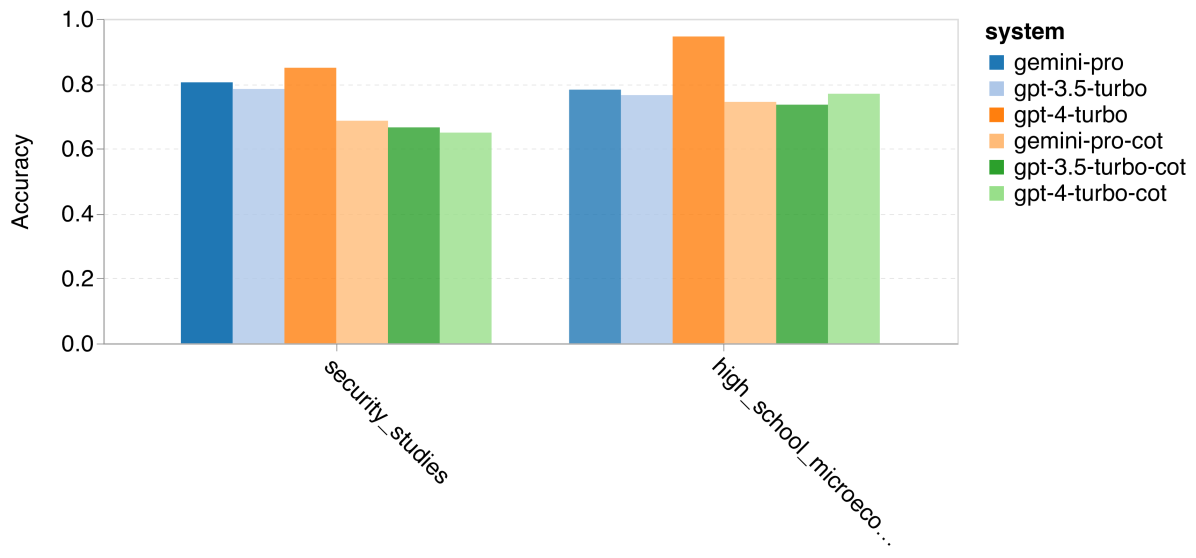
图 4:Gemini Pro 与 GPT 3.5 在 MMLU 任务中的表现对比 (b)Gemini Pro 在某些任务中胜过 GPT 3.5
在最后这部分,我们探究了在链式思维提示中输出长度对模型性能的影响,具体见 图 5。一般来说,性能更强的模型会进行更复杂的推理,从而产生更长的回答。Gemini Pro 的一个突出特点是,与其他两款模型相比,其准确率受输出长度的影响较小。特别是在输出长度超过 900 个字符时,它的表现甚至超过了 GPT 3.5。但值得注意的是,与 GPT 4 Turbo 相比,Gemini Pro 和 GPT 3.5 Turbo 很少产生这样长的推理链。
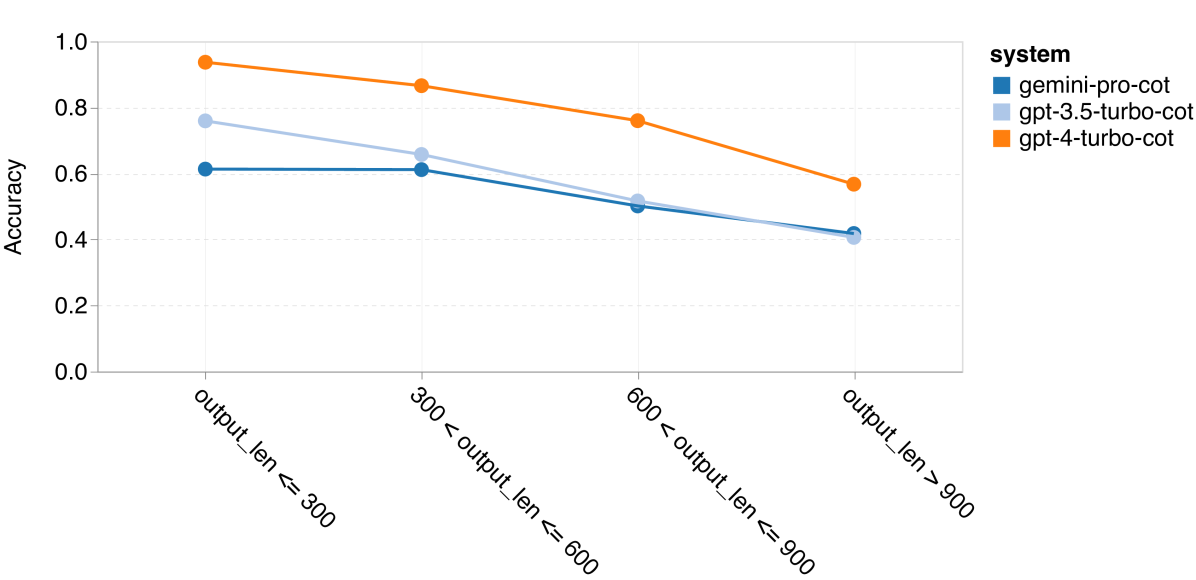
图 5: MMLU 上输出长度的分析 (a) 输出长度与准确率
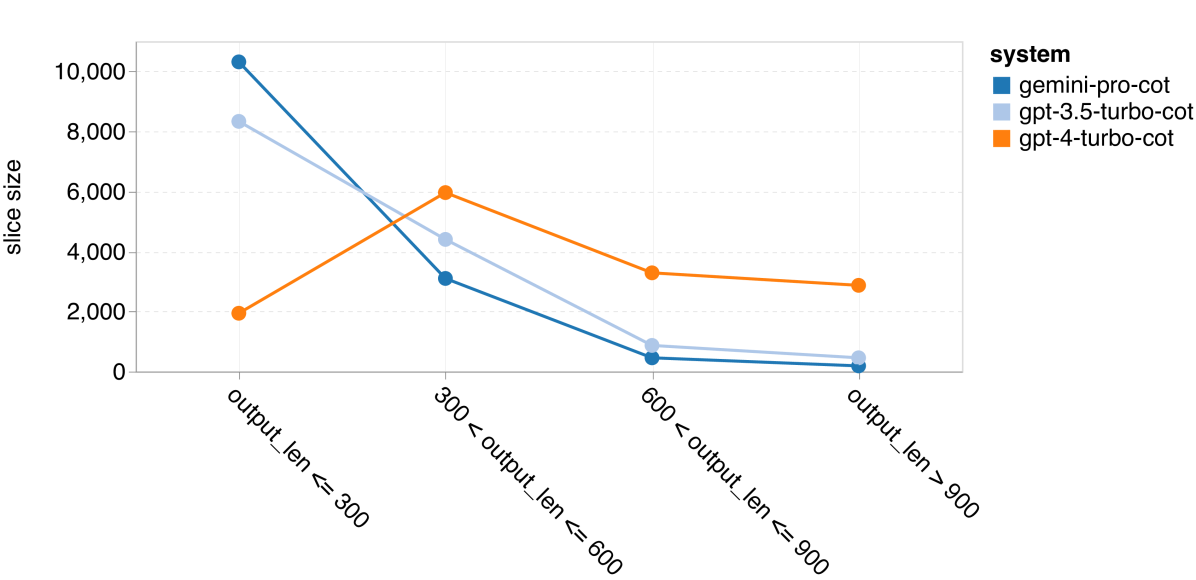
图 5: MMLU 上输出长度的分析 (b) 输出长度分布情况
4 通用推理
在这一部分,我们专注于 BIG-Bench Hard(Suzgun et al., 2022)中的 27 种多样化推理任务,这些任务涵盖了算术、符号、多语言推理以及事实知识理解等领域。大多数任务包含 250 个问题 - 答案对,但有些任务的数量略少。
4.1 实验细节
生成参数
我们遵循 Eleuther harness 的标准 3-shot 提示规则,应用于所有模型。在这种方法中,每个问题后面都跟着一系列的推理步骤,最后以“所以答案是 ___”作为结论。在超参数方面,我们采用贪婪解码,生成温度设置为 0。
评估
在 Eleuther 的评估工具中,针对 BIG-Bench Hard 的评估是通过匹配句子“So the answer is ___.”来提取文本的。但我们发现,一些模型即使给出了正确答案,也不会严格按照这个句式生成回答,尤其在多项选择题中。在这类题目里,答案通常是从题干中选出的一个选项(比如,“answer: (B)”)。为了应对这一情况,我们调整了匹配规则,对于多项选择题,我们直接将模型生成文本的最后一个词作为答案。
4.2 结果与分析
在推理类任务上,我们综合报告了模型的整体表现、针对不同难度问题的表现,以及在 BIG-Bench 各个子任务上的表现。
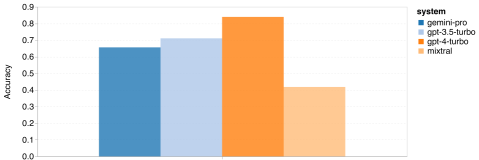
图 6:BIG-Bench-Hard 测试中的总体准确率
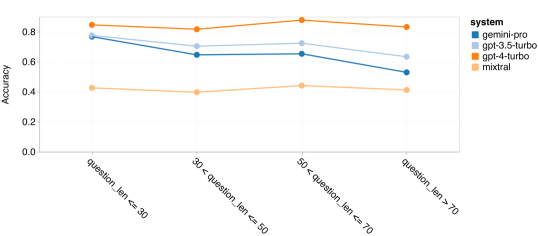
图 7:BIG-Bench-Hard 测试中,按问题长度划分的准确率
首先,从图 ?7可见,Gemini Pro 在总体准确率方面略逊于 GPT 3.5 Turbo,而且远不及 GPT 4 Turbo。而 Mixtral 模型的整体准确率则更低。
从这个总体成绩出发,我们进一步探讨了 Gemini 的不足之处。首先,我们分析了问题长度对准确率的影响,如图 ?7所示。结果显示,Gemini Pro 在处理较长和更复杂的问题时表现不佳,而 GPT 系列模型则表现更加稳定。特别是 GPT 4 Turbo,在处理长问题时几乎没有性能损失,展现了对长且复杂查询的深刻理解能力。GPT 3.5 Turbo 在这方面的表现居中。Mixtral 虽然在问题长度方面表现稳定,但整体准确率较低。
然后,我们分析了在 BIG-Bench-Hard 的不同具体任务中准确率的变化。下面列出了 GPT 3.5 Turbo 在某些任务上比 Gemini Pro 表现更出色的情况。
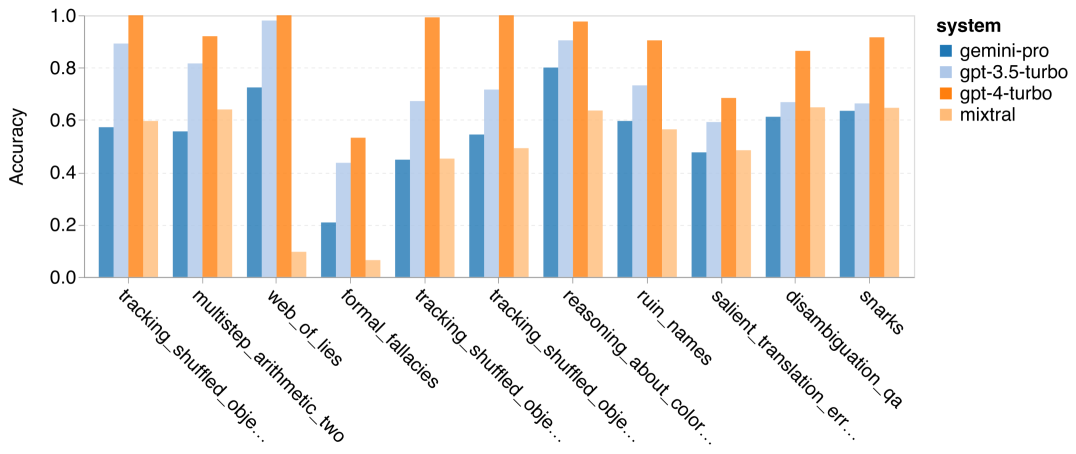
图 8:GPT 3.5 Turbo 在某些任务上的突出表现
显而易见,Gemini Pro 在‘tracking_shuffled_objects’任务上表现不佳。这类任务要求追踪物品在人们之间交换过程中的持有者,Gemini Pro 在这方面经常弄错顺序(如图 ?8所示)。
表 3: Gemini Pro 在追踪混乱对象任务中维持状态的不足,示例。
| 提示 | Alice、Bob 和 Claire 是朋友,也都是热爱阅读的人,他们偶尔会交换书籍。在学期开始时,他们每人各买了一本新书:Alice 买了《尤利西斯》(Ulysses),Bob 买了《弗兰肯斯坦》(Frankenstein),Claire 买了《洛丽塔》(Lolita)。随着学期的进行,他们开始互换这些新书。首先,Claire 和 Bob 互换了书。然后,Bob 和 Alice 互换了书。最后,Claire 和 Bob 又互换了书。在学期结束时,Bob 最终拥有 |
|---|---|
| 标签 | (B) |
| 输出 | (0) 开始时:Alice 拥有《尤利西斯》,Bob 拥有《弗兰肯斯坦》,Claire 拥有《洛丽塔》。 |
在某些任务中,尤其是多步算术任务(multistep_arithmetic_two)、显著翻译错误检测(salient_translation_error_detection)、智谋游戏(snarks)、歧义问题回答(disambiguition_qa)以及两个追踪混乱对象任务中,Gemini Pro 的表现甚至不如 Mixtral 模型。
然而,也有些任务中,Gemini Pro 表现优于 GPT 3.5 Turbo。图 9 展示了 Gemini Pro 在六个任务中相比 GPT 3.5 Turbo 表现更佳的情况。这些任务各具特色,包括需要世界知识的体育理解(sports_understanding)、操纵符号堆栈的迪克语言(dyck_languages)、按字母顺序排序单词(word_sorting)以及解析表格(penguins_in_a_table)等。
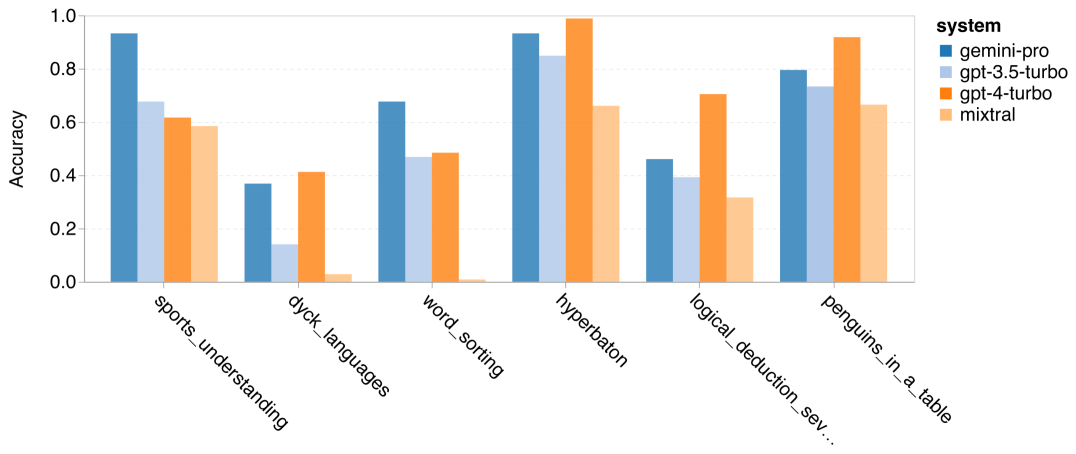
图 9: Gemini Pro 在哪些任务上胜过 GPT 3.5 Turbo
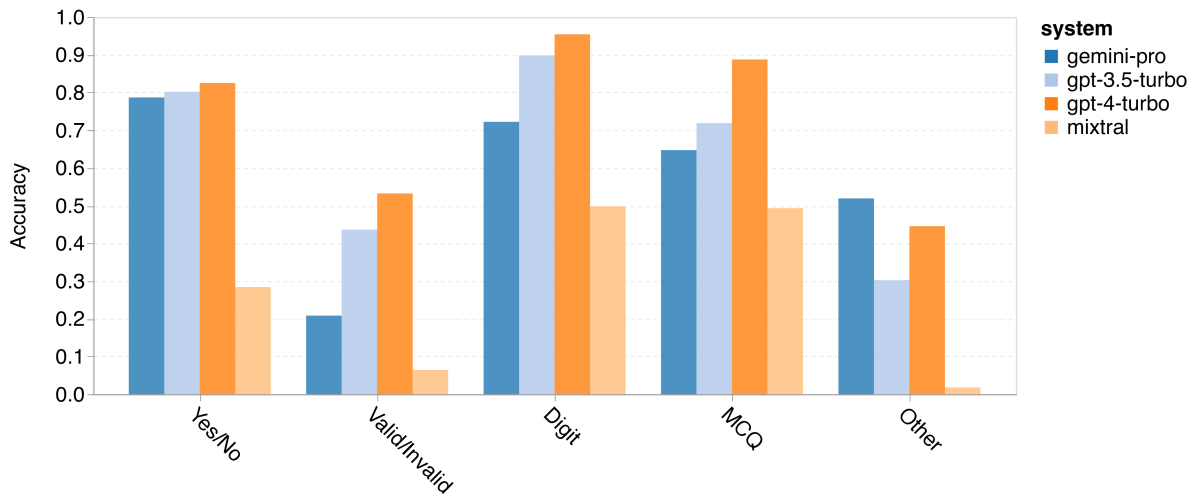
图 10: 按不同答案类型的准确率
我们进一步探讨了大语言模型(LLM)在不同答案类型上的稳定性。如下图所示,Gemini Pro 在判断“有效/无效”类型的答案方面表现最差,这类答案属于“形式谬误”(formal_fallacies)任务。值得注意的是,这个任务中有 68.4% 的问题被阻塞了。然而,在“其他”类型的答案(包括“词语排序”(word_sorting)和“Dyck 语言”(dyck_language)任务)上,Gemini 显著优于所有 GPT 模型和 Mixtral,这也印证了之前的发现:Gemini 特别擅长于单词重排和正确排序地输出符号。在多项选择题(MCQ)答案方面,有 4.39% 的问题被 Gemini Pro 阻塞,尽管 GPT 模型在这一类型中表现突出,但 Gemini 在竞争方面显得有些吃力。
总的来说,似乎没有明显的趋势表明哪个模型在特定任务上比另一个模型表现更好。因此,在执行通用推理任务时,尝试使用 Gemini 和 GPT 模型,然后根据具体情况决定选用哪一个,可能是个不错的选择。
5 数学
![]()
为了评估所测试模型在数学推理方面的能力,我们研究了四个数学文字问题的基准测试:(1) 小学数学基准测试,GSM8K (Cobbe et al., 2021),(2) SVAMP 数据集 (Patel et al., 2021),这个数据集通过改变词序来生成问题,以检验模型的鲁棒性推理能力,(3) ASDIV 数据集 (Miao et al., 2020),包含了多种语言模式和问题类型,以及 (4) MAWPS 基准 (Koncel-Kedziorski et al., 2016),涵盖算术和代数文字问题。
5.1 实验细节
生成参数
我们采用了标准的 8 次少样本连锁思考提示 (Gao et al., 2023a; Wei et al., 2022),在这种提示中,每个少样本问题都伴随着一个用于生成答案的思考链。在评估所有大语言模型时,我们采用了温度值为 0 的贪婪解码方式。
评估
在评估过程中,我们对 Eleuther harness 的标准评估协议进行了轻微的修改。原协议是匹配“答案是”后面的数字输出。我们注意到,即使没有这个特定短语,所有被评估的模型依然倾向于给出正确答案。为了解决这个问题,我们选择将生成文本中的最后一个数字作为问题的答案,这样做大大提高了整体的准确率。
5.2 结果与分析
本节我们将对 Gemini Pro 与 GPT 3.5 Turbo、GPT 4 Turbo 和 Mixtral 在四项数学文字问题任务的准确性进行比较。这包括它们的总体表现、不同问题复杂度下的表现,以及在不同思维链条长度(chain-of-thought depth)下的表现。
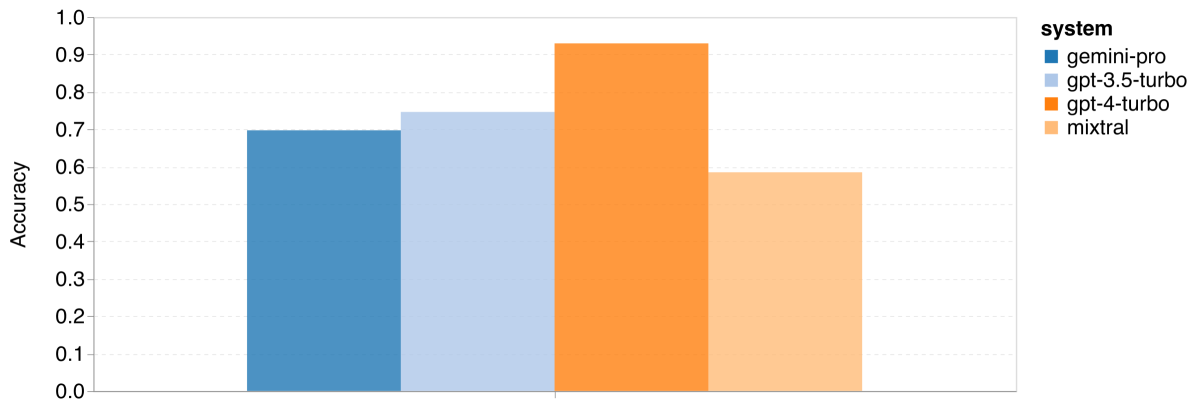
图 11:四项数学推理任务的整体准确率 (a) GSM8K
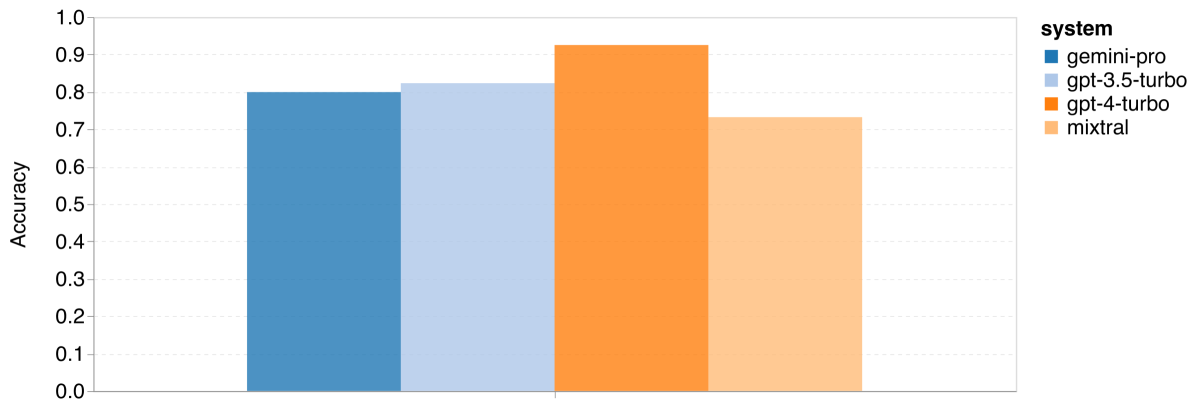
图 11:四项数学推理任务的整体准确率 (b) SVAMP
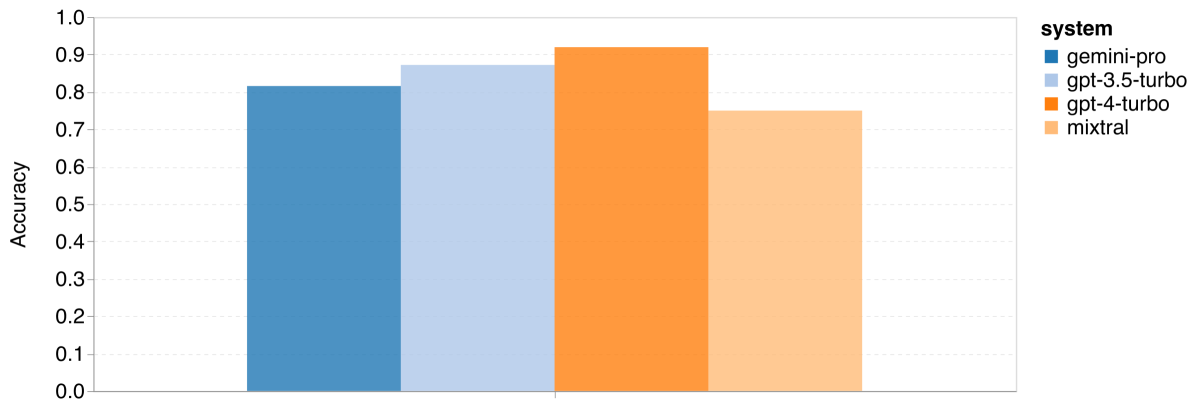
图 11:四项数学推理任务的整体准确率 (c) ASDIV
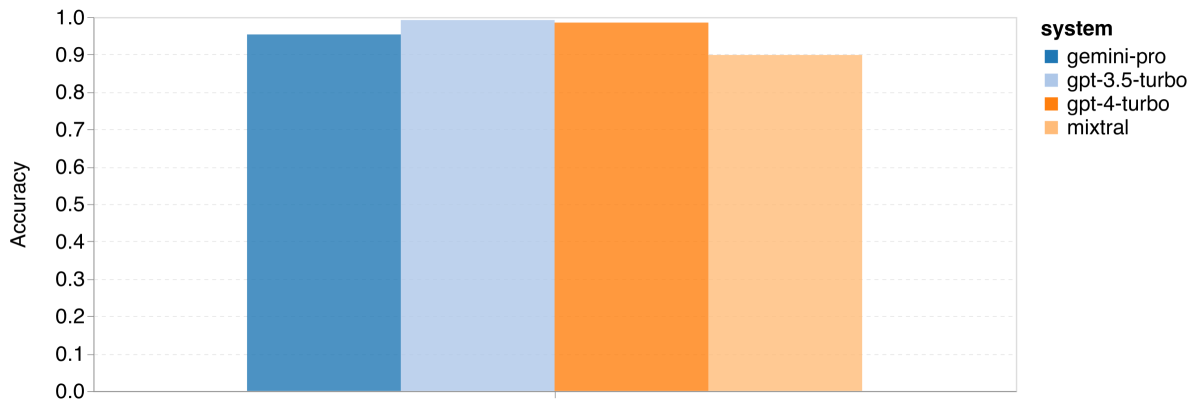
图 11:四项数学推理任务的整体准确率 (d) MAWPS
首先来看整体结果,根据 图 11,Gemini Pro 在 GSM8K、SVAMP 和 ASDIV 任务中的准确率略低于 GPT 3.5 Turbo,而与 GPT 4 Turbo 相比差距更大。这些任务包含了多样化的语言模式。在 MAWPS 任务中,所有模型的准确率都超过了 90%,但 Gemini Pro 的表现仍稍逊于 GPT 模型。特别是在这个任务中,GPT 3.5 Turbo 稍微优于 GPT 4 Turbo。另一方面,Mixtral 模型的准确率相比其他模型要低很多。
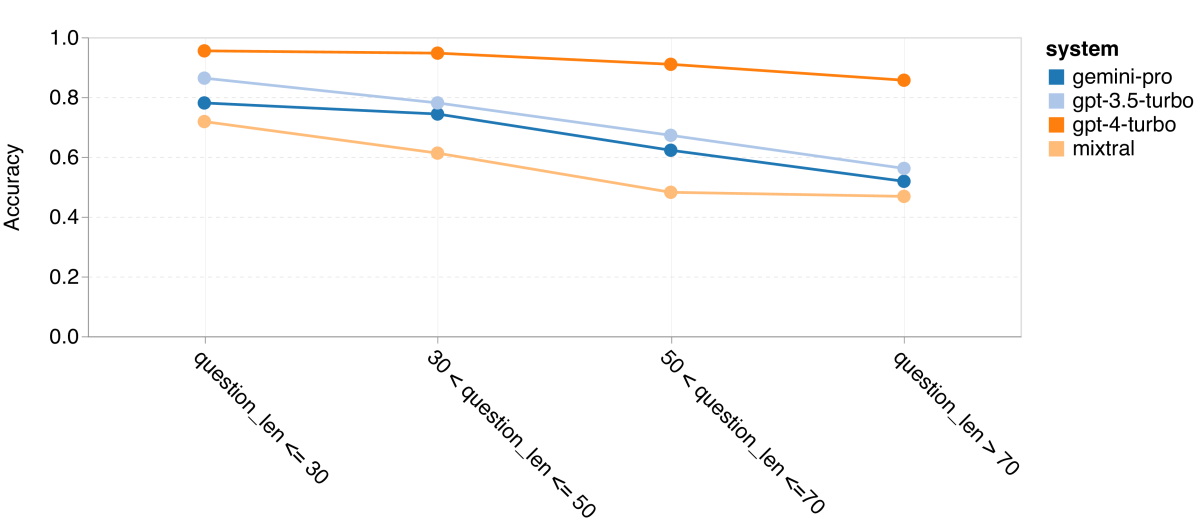
图 12:四项数学推理任务中按问题长度划分的准确率 (a) GSM8K
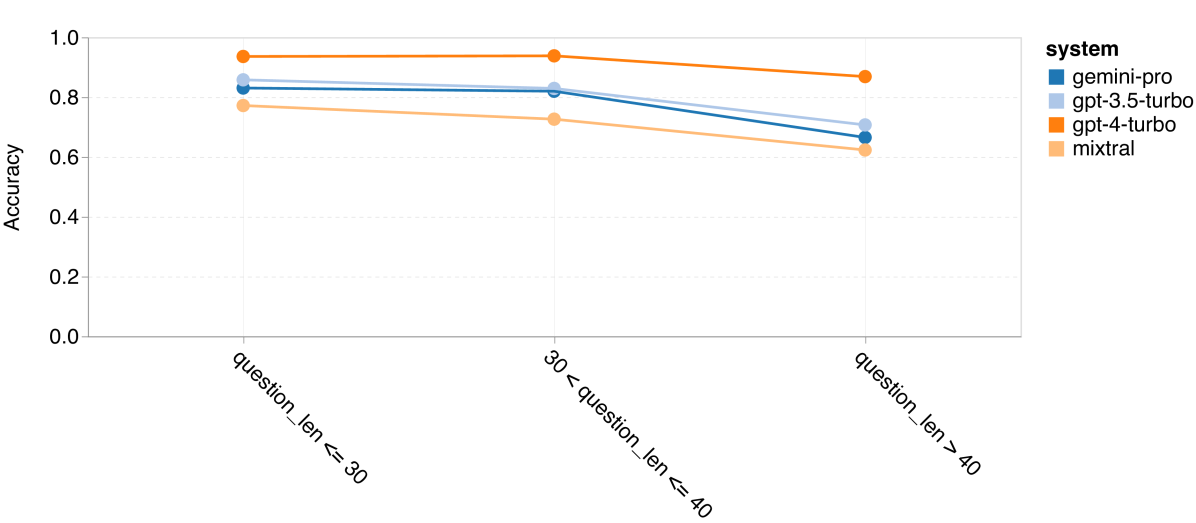
图 12:四项数学推理任务中按问题长度划分的准确率 (b) SVAMP

图 12:四项数学推理任务中按问题长度划分的准确率 (c) ASDIV
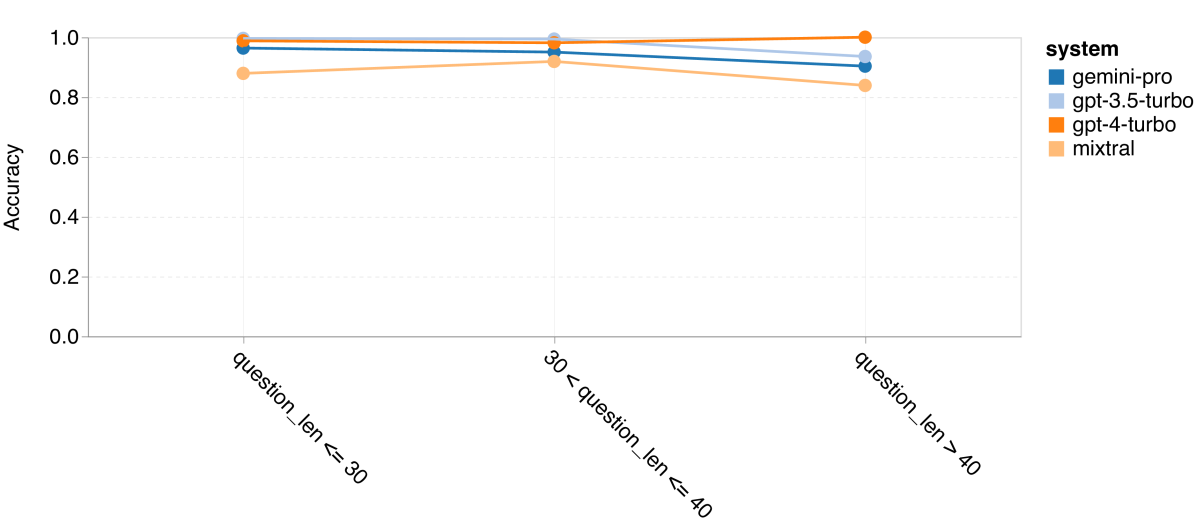
图 12:四项数学推理任务中按问题长度划分的准确率 (d) MAWPS
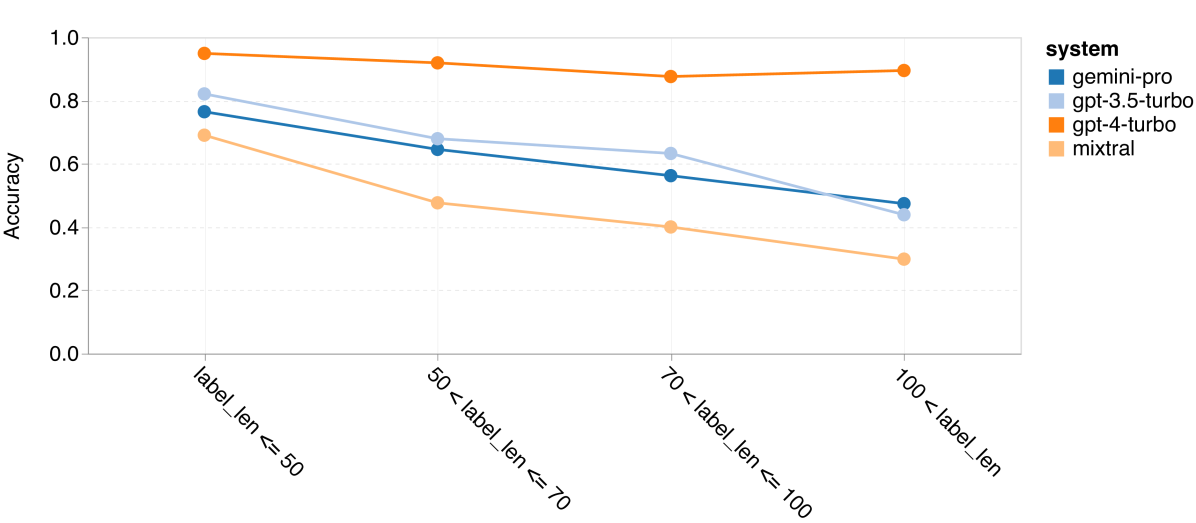
图 13:GSM8K 中按思维链条长度划分的准确率
如第 4 节所述,我们通过分析各模型在不同问题长度下的表现来评估它们的鲁棒性,详见图 12。在 BIG-Bench Hard 的推理任务中,我们发现问题越长,模型的表现越差。与之前一样,在处理较短的问题时,GPT 3.5 Turbo 的表现超过了 Gemini Pro,但在处理较长问题时,其表现下降得更快。相比之下,Gemini Pro 在处理长问题时虽然准确率略低,但表现相对稳定。
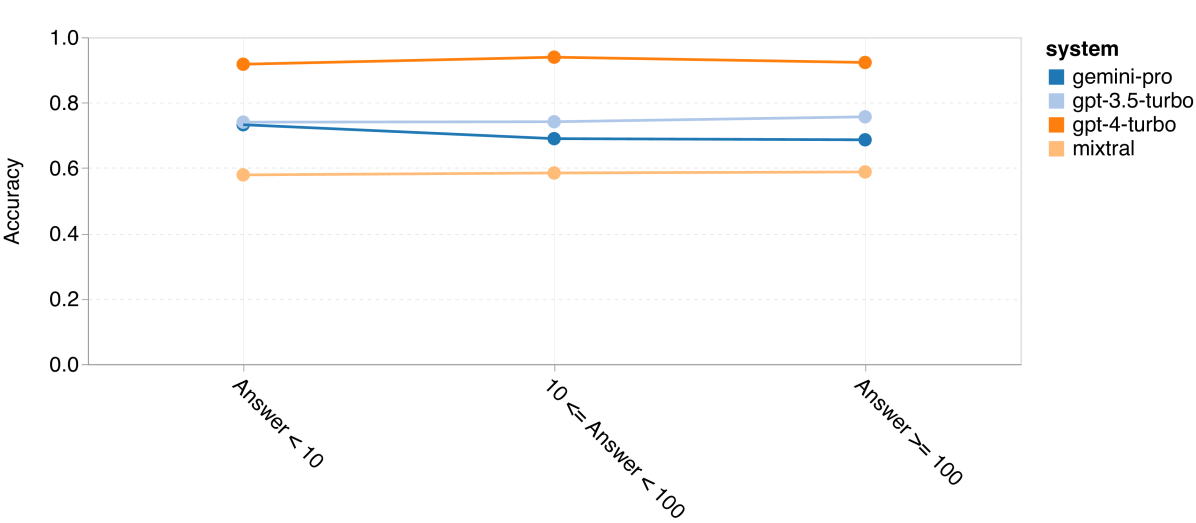
图 14: 四种数学推理任务中,答案数字个数对准确性的影响 (a) GSM8K
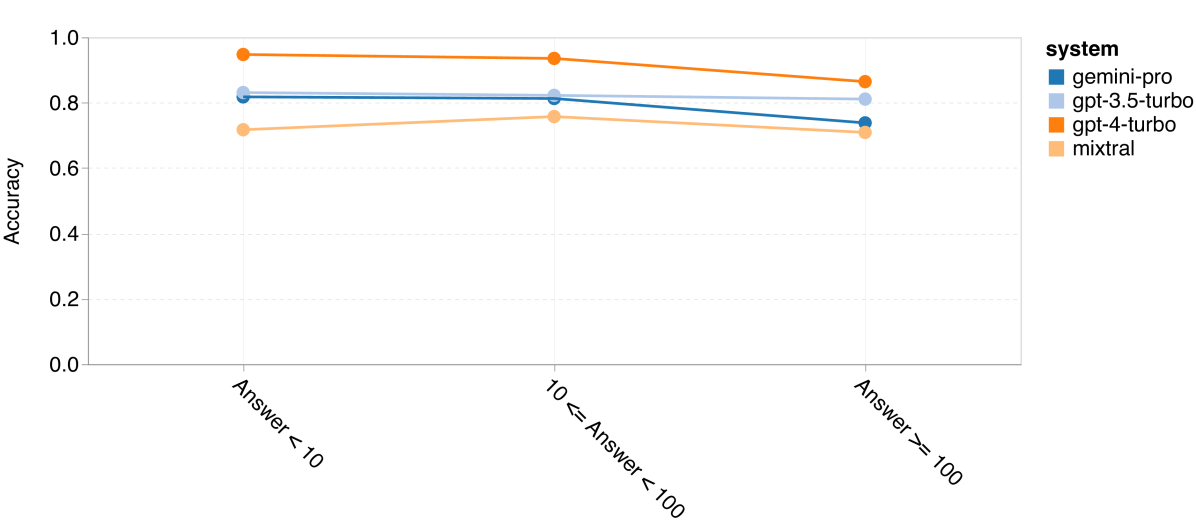
图 14: 四种数学推理任务中,答案数字个数对准确性的影响 (b) SVAMP

图 14: 四种数学推理任务中,答案数字个数对准确性的影响 (c) ASDIV
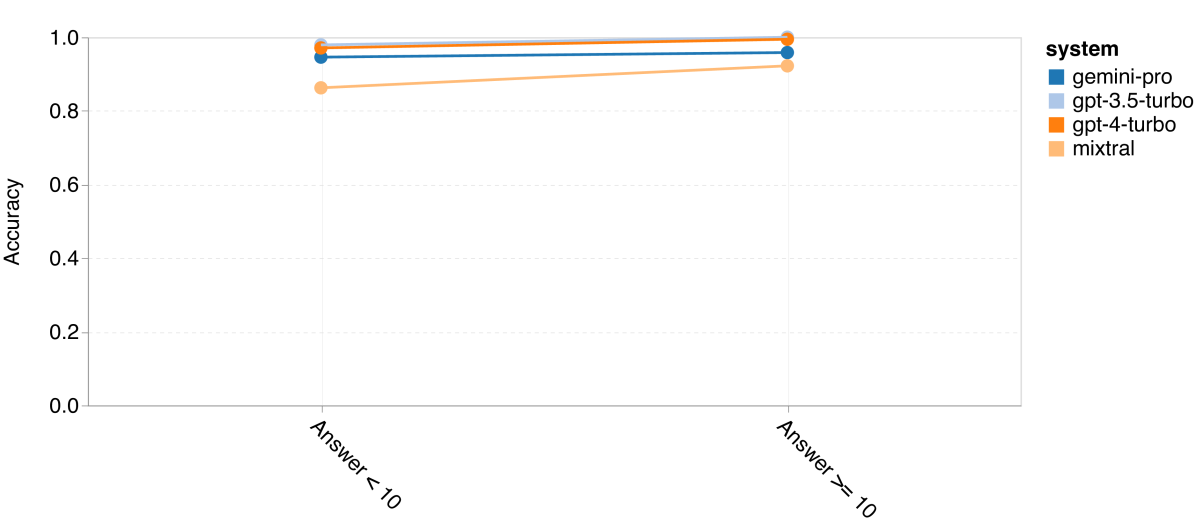
图 14: 四种数学推理任务中,答案数字个数对准确性的影响 (d) MAWPS
同时,我们也关注了大语言模型 (LLM) 在需要较长推理链条的答案时的准确率。正如图 13 所示,GPT 4 Turbo 即使在长推理链的应用中也表现出色,而 GPT 3.5 Turbo、Gemini Pro 和 Mixtral 在处理较长的推理链时则表现不佳。我们的分析还显示,在涉及超过 100 个 COT 步骤的复杂任务中,Gemini Pro 的表现优于 GPT 3.5 Turbo,但在处理较简单的任务时则稍显不足。
最后,我们研究了这些模型在生成数字不同的答案时的准确性。我们根据答案中的数字个数将其分为三类:1 位数、2 位数或 3 位数及以上(MAWPS 任务除外,因其答案不超过两位数)。图 14 显示,GPT 3.5 Turbo 在处理多位数的数学问题上更加稳健,而 Gemini Pro 在处理数字较多的问题时表现稍显下降。
6 代码生成
在这个部分,我们探讨模型在代码生成方面的能力,通过分析两个数据集:HumanEval (Chen 等人,2021) 和 ODEX (Wang 等人,2022b)。HumanEval 主要测试模型对 Python 标准库中部分函数的理解能力;而 ODEX 则更广泛地考察模型在整个 Python 生态中使用各种库的能力。这两个数据集都是以英文书写的任务描述作为输入,通常还包含测试用例。通过这些问题,我们可以评估模型对语言、算法以及基本数学概念的理解。具体来说,HumanEval 包含 164 个测试样本,而 ODEX 则包含 439 个。
6.1 实验详情
生成参数
在进行代码生成测试时,我们遵循了 ODEX8 推荐的标准零样本(Zero-shot)评估流程。我们使用了推荐的超参数设置,即温度设置为 0.8,top_p 设置为 0.95。此外,我们还添加了一条定制指令:“不需要进一步解释,完成给定的代码。请记住,你生成的代码的首行前应该有四个空格的缩进。”这是为了确保模型输出的代码格式符合我们的要求。
评估
我们通过执行测试来进行评估,主要依据的是 Pass@1 指标。这个指标用于判断模型生成的单个代码样本是否能通过测试用例(Chen 等人,2021)。由于我们在零样本环境下对代码生成能力进行评估,模型有时可能会生成与我们的输入格式不完全一致的代码。因此,我们会对生成的代码进行一些基本的后处理,以尽可能使其符合最终验证流程的要求。这包括移除 Markdown 代码块、提取函数实现,以及剪切掉结束标记。值得一提的是,对于不正确的缩进格式,我们并不手动进行修正,而是将其视为典型的语法错误。
6.2 结果与分析
本节主要探讨整体性能表现,并对代码生成领域的一个案例进行了研究。
首先,根据 图 15 展示的总体数据,我们可以观察到 Gemini Pro 在两项任务中的首次通过率(Pass@1)低于 GPT 3.5 Turbo,且远低于 GPT 4 Turbo。这表明 Gemini 在代码生成方面的能力尚有提高空间。
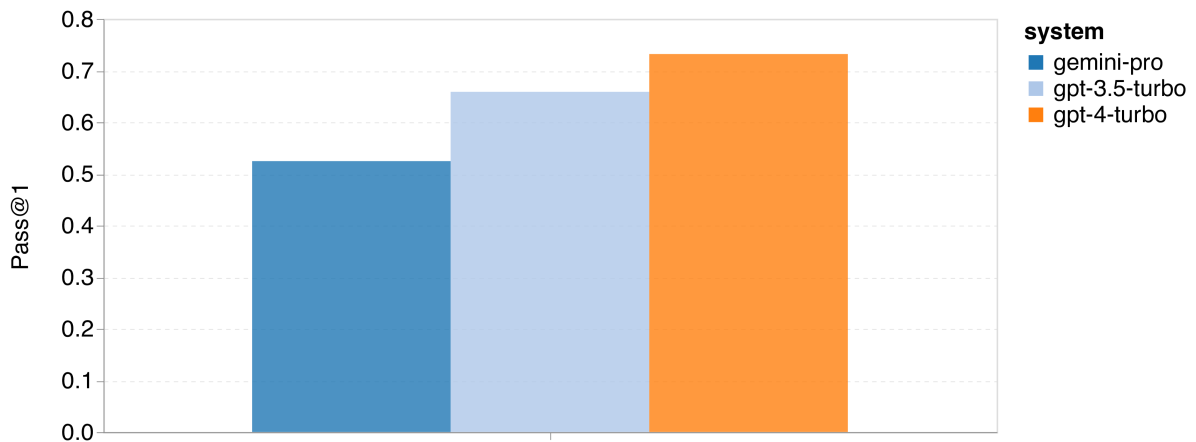
图 15:代码生成任务的整体准确率 (a)HumanEval
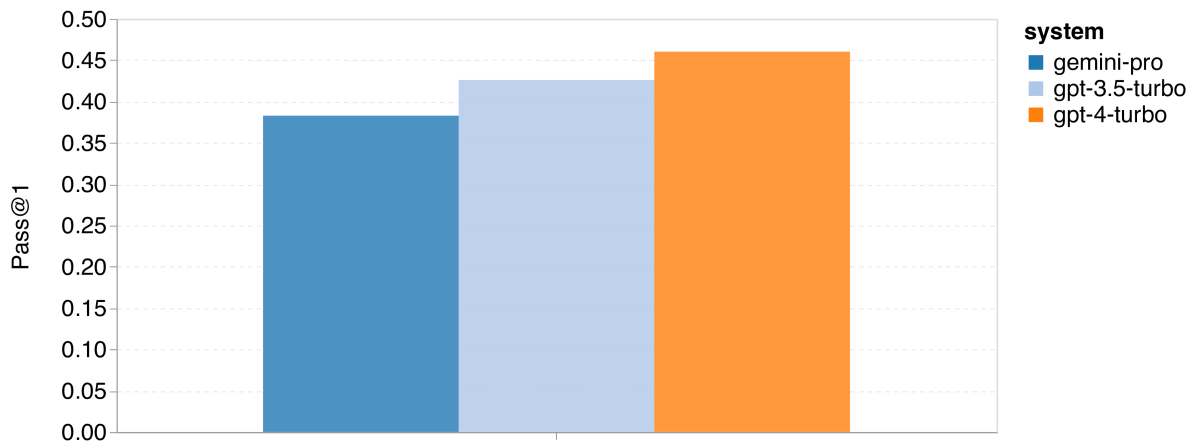
图 15:代码生成任务的整体准确率 (b)ODEX
其次,我们分析了解决方案的长度与模型性能之间的关系,如 图 15(a) 所示。解决方案的长度在一定程度上反映了代码生成任务的难度。我们发现,尽管在解决方案较短(例如不超过 100 字符的简单案例)时,Gemini Pro 的首次通过率与 GPT 3.5 相当,但在解决方案更长时,它的表现则大幅落后。这与前面章节的发现形成鲜明对比,之前我们发现 Gemini Pro 在处理长文本输入和输出时,尤其是在英语任务上,表现相对稳定。
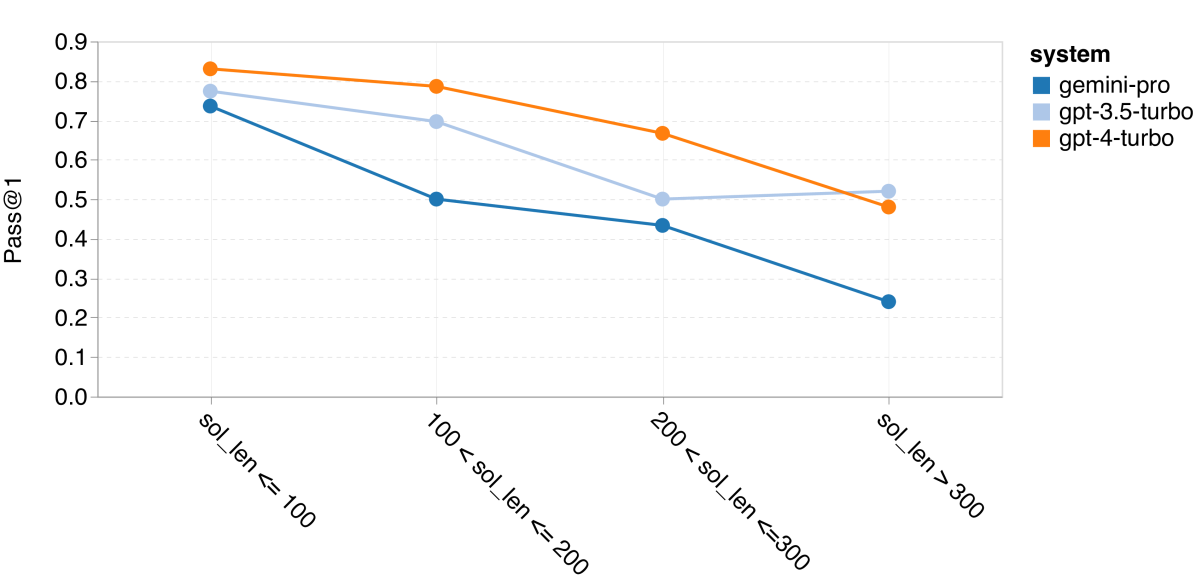
图 16:根据解决方案长度和所用库的首次通过率比较 (a)HumanEval 上根据解决方案长度的准确率
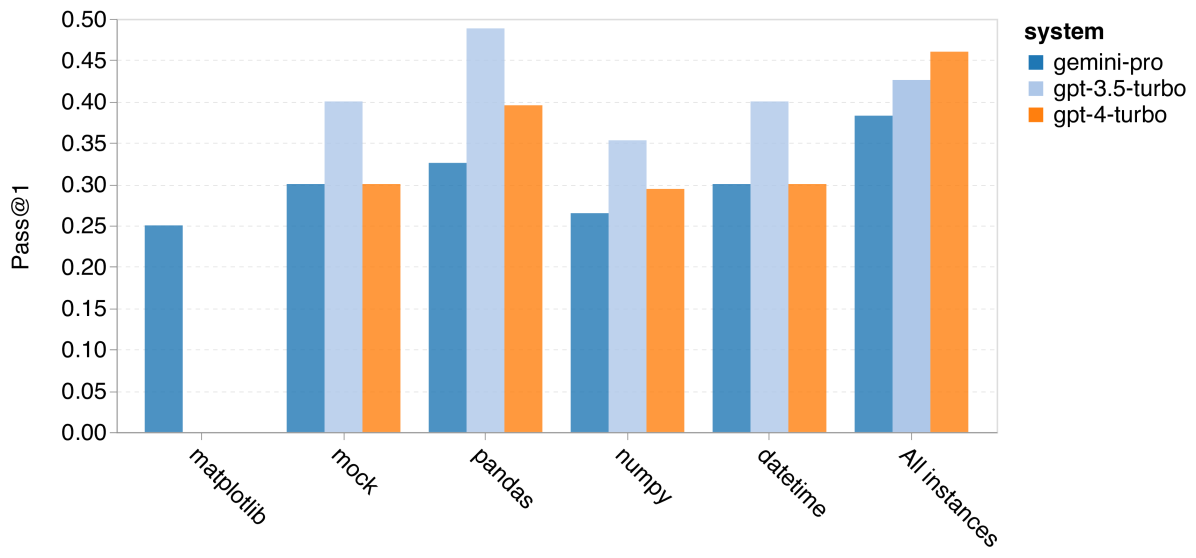
图 16:根据解决方案长度和所用库的首次通过率比较 (b)ODEX 上根据所用库的准确率
此外,我们还研究了解决方案中所需库对模型性能的影响,如 图 15(b) 所示。在大多数使用了特定库的情况下,如 mock, pandas, numpy 和 datetime,Gemini Pro 的表现不如 GPT 3.5。然而,在涉及 matplotlib 的情况下,Gemini Pro 的表现超过了 GPT 3.5 和 GPT 4,展现出在代码绘图和可视化方面的强大能力。
最后,我们展示了几个 Gemini Pro 在代码生成方面表现不如 GPT 3.5 的具体失败案例。首先,我们发现 Gemini 在正确选择 Python API 中的函数和参数方面稍显不足。例如,在给定以下提示时:
def f_3283984():"""解码十六进制字符串 '4a4b4c' 到 UTF-8。"""
Gemini Pro 生成了以下代码,但这会导致类型不匹配的错误:
bytes(bytearray.fromhex('4a4b4c'), 'utf-8')而 GPT 3.5 Turbo 则使用了以下代码,成功实现了预期结果:
hex_string = '4a4b4c'decoded_string = bytes.fromhex(hex_string).decode('utf-8')
return decoded_string
此外,Gemini Pro 在代码实现上虽然语法正确,但在匹配更复杂的意图方面出现了更高比例的错误。例如,面对以下提示:
from typing import Listdef remove_duplicates(numbers: List[int]) -> List[int]:
"""从一个整数列表中移除所有出现不止一次的元素。
保持剩余元素的顺序与输入中的顺序相同。
>>> remove_duplicates([1, 2, 3, 2, 4])
[1, 3, 4]
"""
%**** 06_Code.tex Line 100 ****
Gemini Pro 实现了一个算法,它仅提取了唯一的数字,而没有移除那些出现多次的数字。
seen_numbers = set()unique_numbers = []
for number in numbers:
if number not in seen_numbers:
unique_numbers.append(number)
seen_numbers.add(number)
return unique_numbers
7 机器翻译
本系列实验旨在评估模型在多语言方面的能力,尤其关注它们在使用 FLORES-200 机器翻译基准(由 NLLB 团队等于 2022 年提出)时不同语言组合间的翻译能力。我们重点研究了 Robinson 等人在 2023 年分析中所用的 20 种多样化语言,这些语言在资源可用性和翻译难度上各不相同。我们对所选语言对的测试集中的 1012 个句子进行了评估。在这项研究的起始阶段,我们的研究重点仅限于将英语翻译成其他语言(英语到 X 语言)。
7.1 实验详情
生成参数
我们研究了在 20 种语言对中,采用零样本和五次尝试 (Five-shot) 提示策略的效果。遵循 Gao 等人于 2023 年提出的指导方针,我们为零样本和少样本机器翻译(MT)分别设计了特定的提示,如 表 8 所示。这些提示设置已被证明对使用大语言模型(LLMs)的用户特别有效,Robinson 等人也在 2023 年的研究中提到了这一点。我们的实验设置包括 top_p 值设为 1,温度调至 0.3,上下文长度设为无限制,以及最大 Token 数量设为 500,旨在最大化翻译模型的性能。
评估
在评估输出结果时,我们主要使用了两个指标:
spBLEU: 采用了机器翻译评估中常用的标准 BLEU (由 Papineni et al. 2002 提出),按照 Goyal et al. (2022) 的方法,通过 sacreBLEU 工具包 (Post, 2018) 和 SPM-200 tokenizer (NLLB Team et al., 2022) 来计算 spBLEU 分数。
chrF2++: 我们的主要评估指标 chrF2++ 是基于 sacreBLEU (Post, 2018) 提供的实现。我们选择 chrF2++ 是因为它可以弥补 BLEU 指标的一些不足。为了简化讨论,我们通常将这个指标简称为 chrF (Popovi?, 2017)。
7.2 结果与分析
| 语言(代码) | Gemini Pro | GPT 3.5 Turbo | GPT 4 Turbo | | NLLB |
|---|---|---|---|---|---|
| 史瓦希里语(拉丁字母) | 5.71 | 11.15 | 37.20 | - | 43.30 |
| 修纳语(拉丁字母) | 4.36 | 16.07 | 42.82 | 44.40 | 43.40 |
| 中库尔德语(阿拉伯字母) | 0.01 | 19.42 | 39.58 | 47.70 | 47.20 |
| 梅加提语(天城体) | 40.37 | 38.91 | 23.83 | - | 58.50 |
| 伊博语(拉丁字母) | 5.26 | 14.05 | 41.57 | 43.50 | 41.40 |
| 豪萨语(拉丁字母) | 37.32 | 23.62 | 49.92 | 53.20 | 53.50 |
| 普什图语(阿拉伯字母) | 0.33 | 20.32 | 33.22 | - | 39.40 |
| 泰米尔语(泰米尔字母) | 0.01 | 34.52 | 48.87 | 55.80 | 53.70 |
| 格鲁吉亚语(格鲁吉亚字母) | 0.04 | 34.21 | 43.21 | 51.40 | 48.10 |
| 爱尔兰语(拉丁字母) | 4.60 | 47.66 | 56.81 | 60.10 | 58.00 |
| 库尔德语(拉丁字母) | 10.78 | 25.98 | 31.96 | 40.00 | 39.30 |
| 瓦瑞语(拉丁字母) | 59.14 | 49.94 | 54.92 | - | 57.40 |
| 阿拉伯语(阿拉伯字母) | 49.79 | 46.93 | 46.45 | - | 51.30 |
| 林堡语(拉丁字母) | 39.90 | 40.30 | 41.32 | - | 47.90 |
| 乌克兰语(西里尔字母) | 57.92 | 54.67 | 57.09 | 58.60 | 56.30 |
| 法语(拉丁字母) | 71.46 | 71.15 | 70.92 | 72.70 | 69.70 |
注:此表格展示了不同语言在多种语言模型中的表现评分。分数越高表示模型处理该语言的能力越强。"-" 表示该模型未对此语言进行评分。
| 语言(代码) | Gemini Pro | GPT 3.5 Turbo | GPT 4 Turbo | | NLLB |
|---|---|---|---|---|---|
| 拉脱维亚语(拉丁字母) | 59.67 | 55.01 | 58.05 | - | 54.80 |
| 罗马尼亚语(拉丁字母) | 65.58 | 64.20 | 64.58 | 65.00 | 61.30 |
| 托克皮辛语(拉丁字母) | 31.13 | 37.33 | 48.36 | - | 41.60 |
| 伊拉克阿拉伯语(阿拉伯字母) | 48.47 | 44.50 | 40.71 | - | 31.90 |
表 4: 机器翻译性能(字符级重叠率 F 得分,百分比)跨模型对所有语言使用零样本 (0-shot) 提示的表现。在此表中,最佳得分以加粗形式呈现,次佳得分下划线标记。
注:此表格展示了不同语言在多种语言模型中的机器翻译性能。分数越高表示模型翻译该语言的效果越好。"-" 表示该模型未对此语言进行评分。最佳得分和次佳得分分别表示为各语言中得分最高和第二高的模型。
| 语言 | Gemini Pro | GPT 3.5 Turbo | GPT 4 Turbo | | NLLB |
|---|---|---|---|---|---|
| 斯威士语 (ssw_Latin) | 19.74 | 7.62 | 38.07 | - | 43.30 |
| 修纳语 (sna_Latin) | 4.36 | 15.84 | 42.95 | 44.40 | 43.40 |
| 中库尔德语 (ckb_Arab) | 0.01 | 24.56 | 40.71 | 47.70 | 47.20 |
| 马加伊语 (mag_Deva) | 47.54 | 39.25 | 45.33 | - | 58.50 |
| 伊博语 (ibo_Latin) | 5.26 | 16.29 | 41.65 | 43.50 | 41.40 |
| 豪萨语 (hau_Latin) | 5.32 | 24.22 | 50.11 | 53.20 | 53.50 |
| 普什图语 (pbt_Arab) | 0.33 | 21.35 | 34.11 | - | 39.40 |
| 泰米尔语 (tam_Tamil) | 0.01 | 34.86 | 48.69 | 55.80 | 53.70 |
| 格鲁吉亚语 (kat_Geor) | 0.04 | 33.61 | 43.17 | 51.40 | 48.10 |
| 爱尔兰语 (gle_Latin) | 4.60 | 47.30 | 57.25 | 60.10 | 58.00 |
| 库尔德语 (kmr_Latin) | 4.91 | 26.10 | 32.76 | 40.00 | 39.30 |
| 沃雷语 (war_Latin) | 48.94 | 50.85 | 56.26 | - | 57.40 |
| 阿拉伯语 (ajp_Arab) | 50.72 | 47.49 | 48.12 | - | 51.30 |
| 林堡语 (lim_Latin) | 46.92 | 43.25 | 45.21 | - | 47.90 |
| 乌克兰语 (ukr_Cryl) | 57.79 | 55.19 | 56.85 | 58.60 | 56.30 |
| 法语 (fra_Latin) | 71.80 | 71.34 | 70.79 | 72.70 | 69.70 |
| lvs_Latin | 59.93 | 55.05 | 58.34 | - | 54.80 |
| ron_Latin | 66.11 | 64.19 | 64.42 | 65.00 | 61.30 |
| tpi_Latin | 35.90 | 37.39 | 50.67 | - | 41.60 |
| acm_Arab | 49.78 | 45.88 | 46.45 | - | 31.90 |
表 5: 本表展示了使用少样本(5-shot)提示进行的多语言机器翻译测试的性能表现,这里使用的是 chRF(字符级 F 分数)百分比来评估。不同语言的翻译效果通过这个分数来衡量,其中最高分以粗体标出,次高分则用下划线标注。简要来说,这个分数反映了翻译质量的高低,分数越高意味着翻译越准确。
总体表现
在 表 4 和 表 5,我们对 Gemini Pro、GPT 3.5 Turbo 和 GPT 4 Turbo 进行了与 Google Translate 等成熟翻译系统的比较分析。同时,我们还对开源机器翻译 (MT) 模型的佼佼者 NLLB-MoE(NLLB 团队,2022)进行了基准测试,该模型以覆盖众多语言而闻名。结果显示,Google Translate 通常优于其他模型,尤其在 9 种语言上表现出色。而 NLLB 在“零样本 (Zero-shot)”和“少样本 (Few-shot)”设置中,在 6 到 8 种语言上表现优秀。尽管通用语言模型 (LLM) 表现出竞争力,但它们在翻译非英语语言方面还未能超过专门的机器翻译系统。
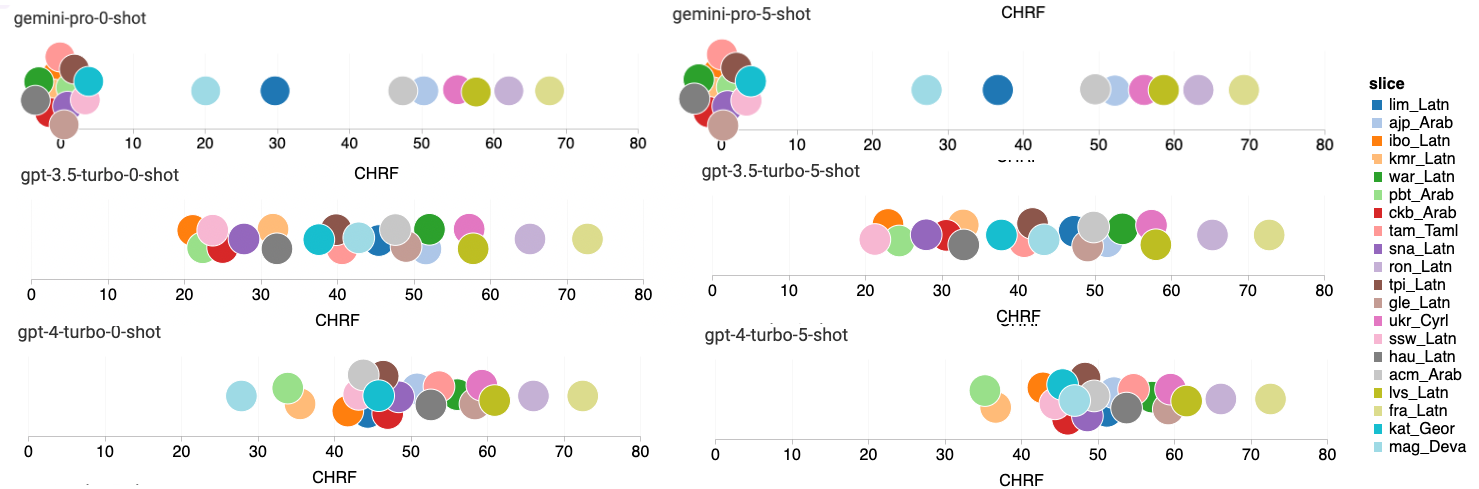
图 17: 不同语言对的机器翻译性能(chRF (%) 分数)
图 17 展示了不同通用语言模型在各语言对中的比较性能。GPT 4 Turbo 与 NLLB 相比,在与 GPT 3.5 Turbo 和 Gemini Pro 的性能比较中显示出一致的差异。这一发现反映了有关 GPT 4 Turbo 多语言性能的最新研究 OpenAI (2023)。GPT 4 Turbo 在低资源语言上取得了显著进步(参考 NLLB 团队的研究 2022),而在高资源语言上,LLM 的性能与之相似。相比之下,Gemini Pro 在 20 种语言中的 8 种上超过了 GPT 3.5 Turbo 和 GPT 4 Turbo,在 4 种语言上达到最高表现。然而,Gemini Pro 在约 10 种语言对中表现出阻塞回应的倾向,这一现象我们将在后续的分析中进一步探讨。
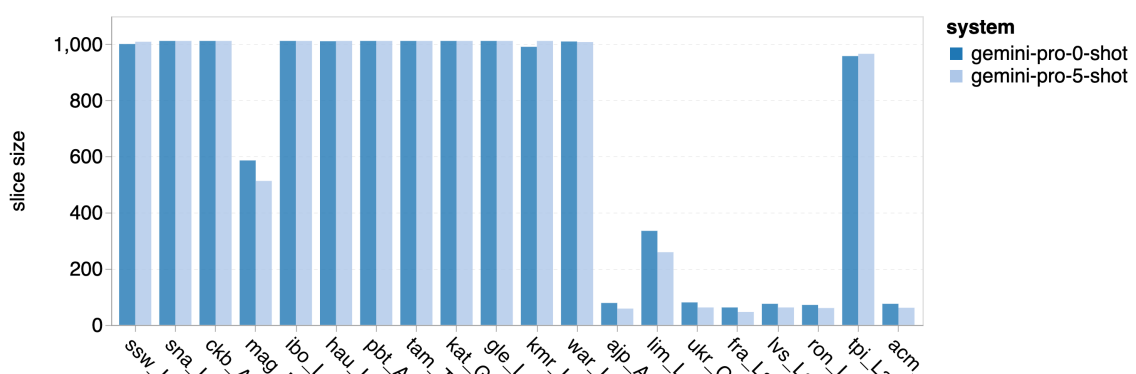
图 18: Gemini Pro 屏蔽的样本数
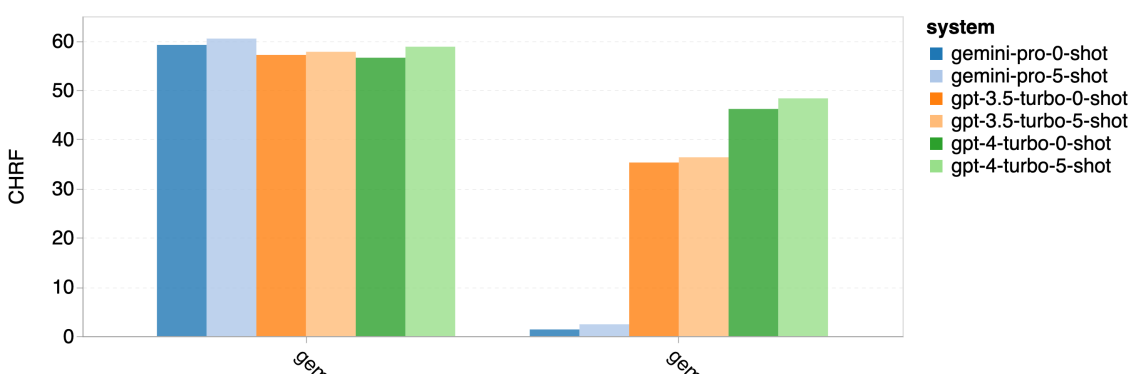
图 19: 在屏蔽与非屏蔽样本上的 chrf (%) 性能表现
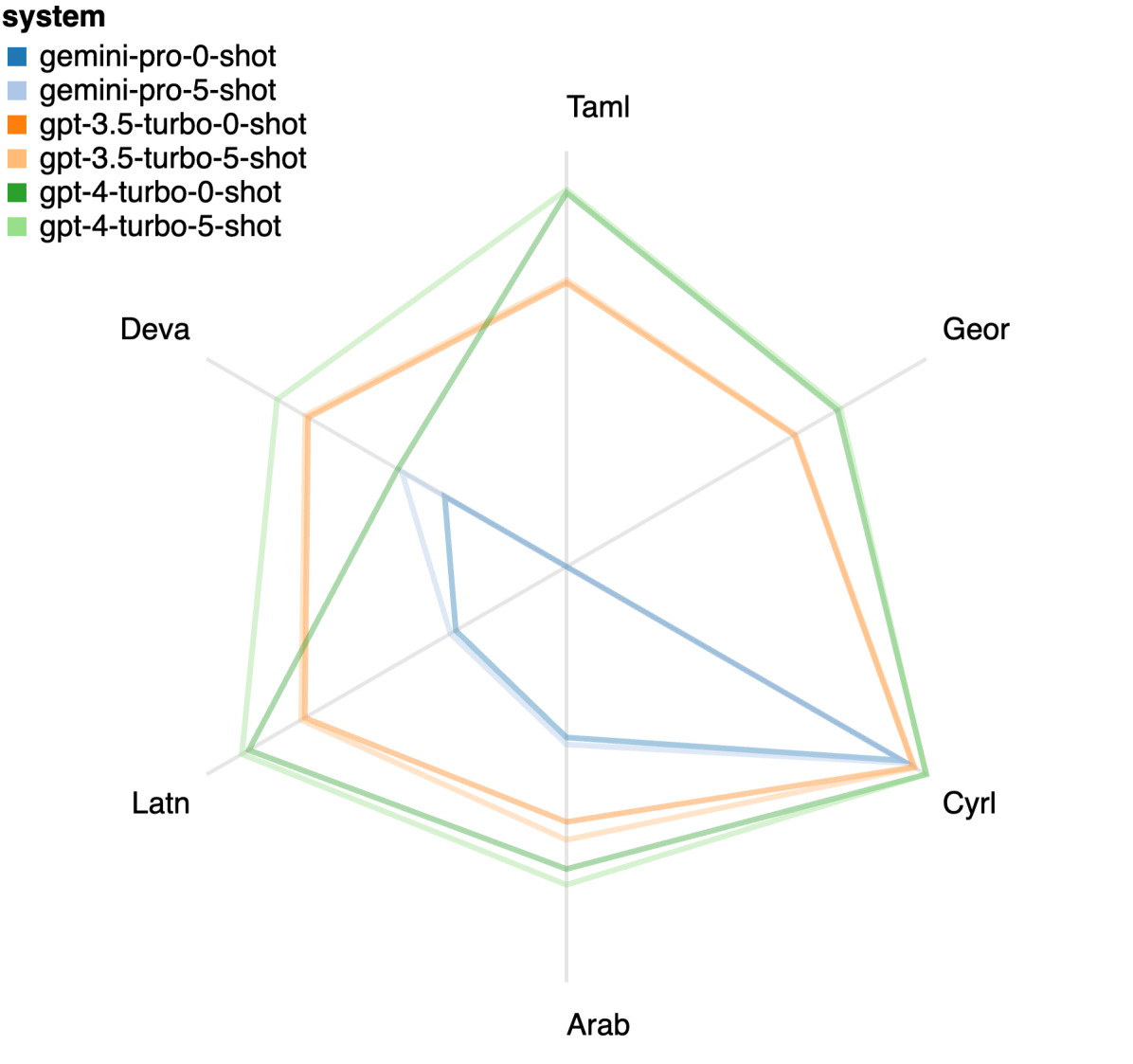
图 20: 按照脚本分类的性能表现 (chrf (%))
Gemini 的响应屏蔽情况
图 18 揭示了 Gemini Pro 在特定语言上性能不佳的原因:在置信度较低的情况下,它倾向于屏蔽响应。当 Gemini Pro 无论是在零样本还是五样本配置下产生了一个“屏蔽响应”错误时,我们就认为该响应被屏蔽了。通过对 图 19 的进一步分析,我们发现在置信度较高的非屏蔽样本中,Gemini Pro 的表现略胜于 GPT 3.5 Turbo 和 GPT 4 Turbo。具体来说,它在五样本模式下比 GPT 4 Turbo 高出 1.6 chrf,在零样本模式下高出 2.6 chrf;同时在五样本和零样本模式下,分别比 GPT 3.5 Turbo 高出 2.7 chrf 和 2 chrf。然而,我们对 GPT 4 Turbo 和 GPT 3.5 Turbo 在这些样本上的初步评估表明,这些样本通常更难以翻译。特别是在某些情况下,Gemini Pro 在零样本模式下会屏蔽响应,而在五样本模式下则不会,反之亦然,这一点在这些特定样本上尤为明显。
其他发现
在对模型进行分析时,我们注意到,少样本环境下的提示一般能稍微提升模型的平均性能。这种性能提升在不同模型间表现出不同的方差增加趋势,顺序为:GPT 4 Turbo < GPT 3.5 Turbo < Gemini Pro。特别地,Gemini Pro 在使用 5 次提示 (5-shot) 的情况下,在那些表现出较高准确度的语言中比不使用提示 (0-shot) 时表现更佳。然而,在某些特定语言,例如 hau_Latin,该模型的准确度显著降低,导致无法有效回应(具体参见 表 5)。
在 图 20 中,我们根据语言家族或书写系统的分类,展示了一些明显的趋势。一个重要的观察是,在使用西里尔字母脚本的语言中,Gemini Pro 与其他模型相比表现出较强的竞争力,但在其他书写系统的语言中表现不尽如人意。而 GPT-4 在不同书写系统的语言中普遍表现出色,特别是在少样本环境下的效果更加显著。这种效果在使用梵文脚本的语言中表现得尤为明显。
详见图注
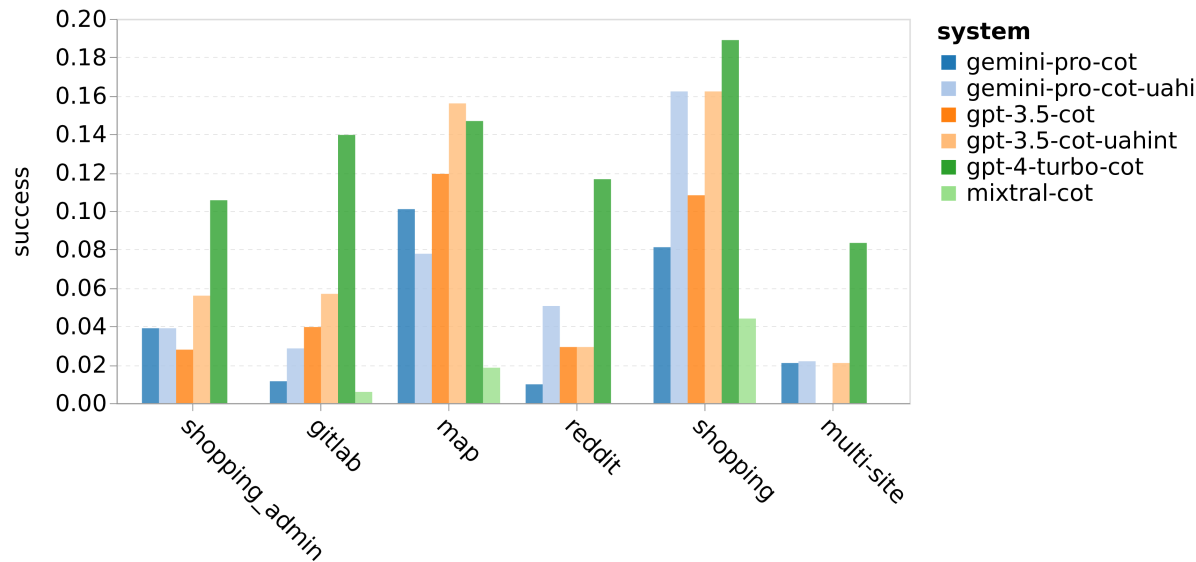
图 21: 在不同网站组别中各模型的网络代理成功率评估
8 网络代理
| 链式推理 (CoT) | 用户助理提示 (UA Hint) | 模型 | 成功率 (SR) | 调整后成功率 (SR_AC_AC) |
|---|---|---|---|---|
| ? | ? | Gemini-pro | 7.09 | 3.52 |
| ? | ? | Gemini-pro | 5.23 | 4.83 |
| ? | ? | GPT-3.5-turbo | 8.75 | 6.44 |
| ? | ? | GPT-3.5-turbo | 6.41 | 6.06 |
| ? | ? | GPT-4-turbo | 15.16 | 14.22 |
表 6: 在 WebArena 上的性能表现。
最后,我们研究了每种模型充当网络导航代理的能力,这是一项既需要长远规划也需要复杂数据理解的任务。我们采用了 WebArena(Zhou et al., 2023b)作为基于执行结果的仿真环境,其成功标准依据实际执行结果。分配给代理的任务包括信息搜寻、网站导航以及内容和配置操作。这些任务跨越了多种网站,例如电子商务平台、社交论坛、协同软件开发平台(如 gitlab)、内容管理系统和在线地图。
生成参数
我们采用 WebArena 的测试方法对 Gemini 进行测试。我们使用了 Zhou et al. (2023b) 提出的两次射击链式思考 (CoT) 样式提示,每个提示包含两个 CoT 示例。此外,我们还区分了模型是否在认为任务无法实现时指令终止执行(WebArena 中称为“不可实现”提示,即 UA)。
简而言之,我们从 WebArena 选取了两个提示进行测试:p_cot_id_actree_2s 和 p_cot_id_actree_2s_no_na,分别是带 UA 提示和不带 UA 提示的 CoT 提示。为了保证 GPTs 和 Gemini 之间的结果可比性,我们为所有模型设置了相同的最大观察长度上限,即使用 gpt-4-1106-preview 分词器的 1920 Token。在超参数设置上,我们遵循了各大语言模型提供商的默认建议。对于 Gemini 模型,推荐的默认温度为 0.9,top-p 为 1.0;而 WebArena 对于 GPT 模型的推荐默认值是温度 1.0,top-p 为 0.9。
评估程序
只要 AI 智能体实现了最终目标,无论其中间步骤如何,其行动序列即被视为正确。我们采用 WebArena 的评估方式,通过智能体的最终输出判断任务是否成功完成。Gemini API 对少量回应进行了屏蔽(约占总测试案例的 2%),在我们的实验中,这些被视为失败的尝试。
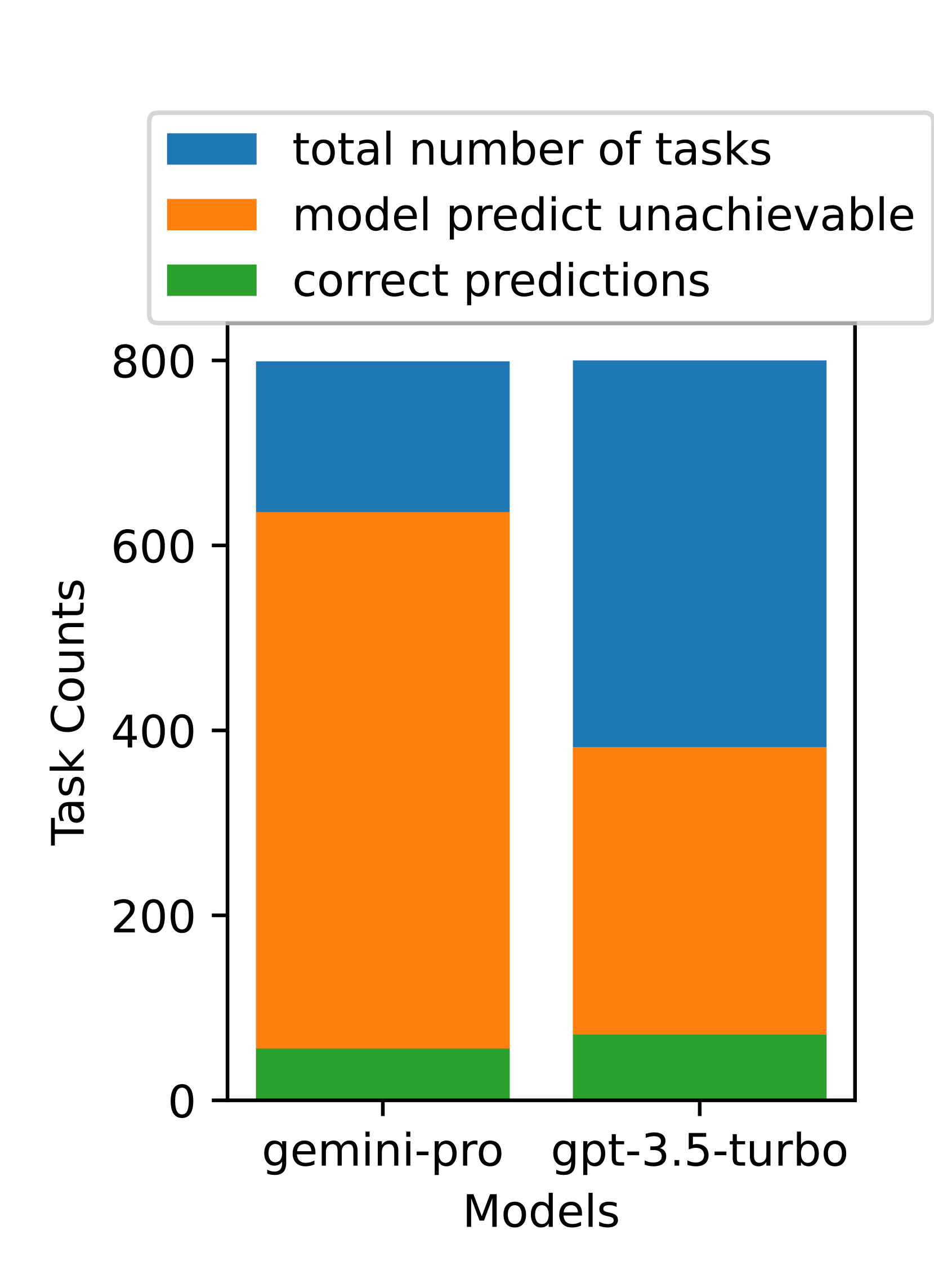
图 22: UA 预测计数
8.2 结果与分析
我们对 Gemini-Pro 在多方面的表现进行了评估:总体成功率、不同任务类型的成功率、回应的长度、任务处理的步骤数量,以及预测任务无法完成的频率。Gemini-Pro 的整体性能见于表 6。与 GPT-3.5-Turbo 相比,Gemini-Pro 的表现相似,但略有不足。类似于 GPT-3.5-Turbo,在提醒任务可能无法完成(即“无法实现提示”)的情况下,Gemini-Pro 表现更佳。在有“无法实现提示”的情况下,Gemini-Pro 的整体成功率达到了 7.09%。
如果我们按照网站类别细分,正如图 21 所示,我们可以发现在 gitlab 和 maps 上,Gemini-Pro 的表现不如 GPT-3.5-Turbo,而在购物管理、reddit 以及一般购物方面与 GPT-3.5-Turbo 相当。在跨多个网站的任务上,Gemini-Pro 的表现优于 GPT-3.5-Turbo,这与我们之前的发现相符,即 Gemini 在更复杂的子任务上稍有优势。
总体来看,如图 22 所示,Gemini-Pro 更倾向于预测任务无法完成,尤其是在有“无法实现提示”的情况下。当给出“无法实现提示”时,Gemini-Pro 预测超过 80.6% 的任务为无法完成,而 GPT-3.5-Turbo 的这一比例为 47.7%。值得注意的是,数据集中实际无法完成的任务比例仅为 4.4%,这意味着两者都高估了无法完成任务的实际比例。
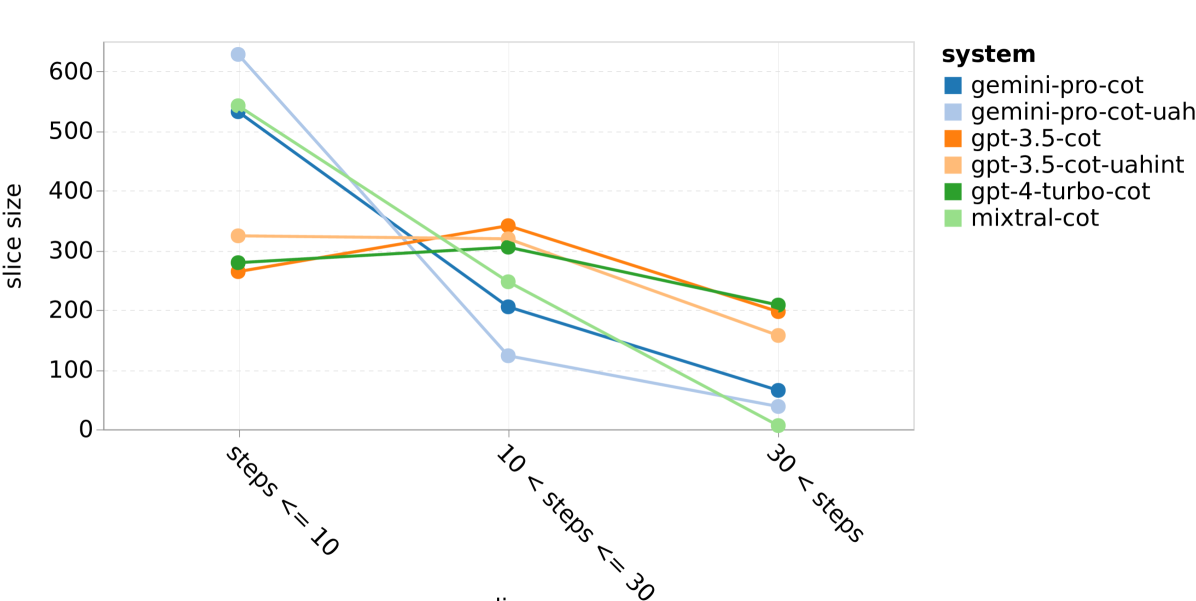
图 23:WebArena 上模型的表现情况 (a) 每个任务平均所需步骤数
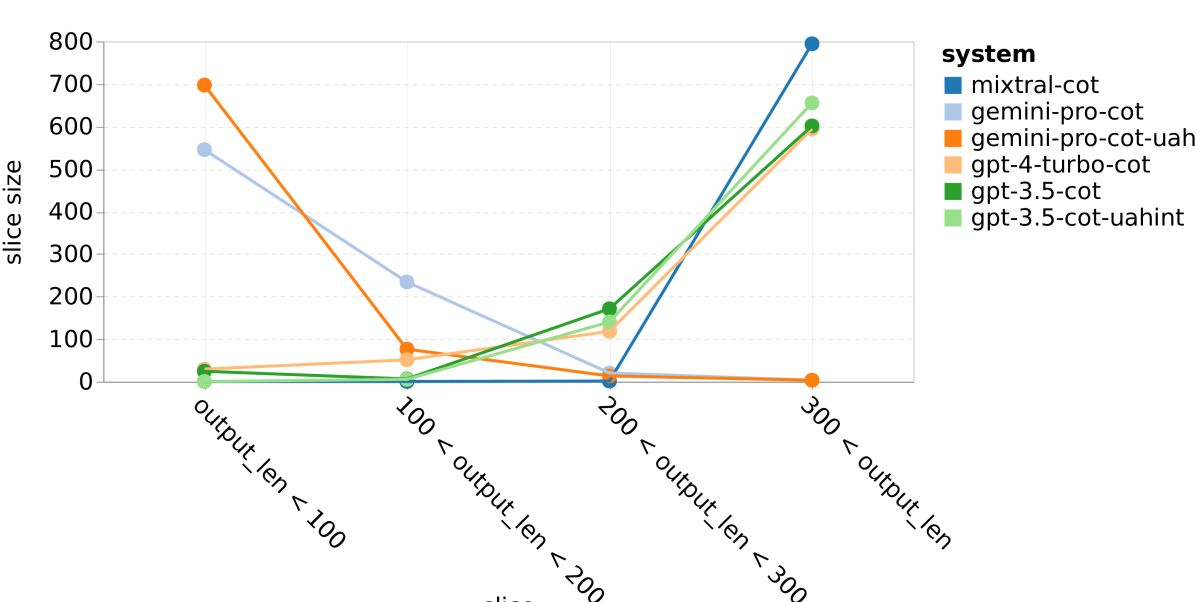
图 23:WebArena 上模型的表现情况 (b) 回应的平均长度
我们还发现,Gemini Pro 更倾向于使用简短的短语进行回应,并且在得出结论前的步骤较少。正如 22(a) 所展示的,Gemini Pro 超过一半的处理过程不超过十步,而 GPT 3.5 Turbo 和 GPT 4 Turbo 的大部分处理过程在 10 至 30 步之间。类似地,大多数 Gemini 的回应不足 100 个字符,而 GPT 3.5 Turbo、GPT 4 Turbo 和 Mixtral 的回应则多在 300 个字符以上 22(b)。Gemini 倾向于直接预测行动,而其他模型则先进行推理后给出行动预测。
结论
在本文中,我们首次全面且深入地探讨了谷歌的 Gemini 模型,将其与 OpenAI 的 GPT 3.5 和 4 模型以及开源 Mixtral 模型进行了比较。
主要发现
我们得出了以下几点结论:
-
在模型规模和类别上,Gemini Pro 与 GPT 3.5 Turbo 相似,它在准确性上大体与 GPT 3.5 Turbo 相当,但略逊一筹,远不及 GPT 4。在我们测试的所有任务中,它都优于 Mixtral。
-
特别指出,Gemini Pro 在多项选择题的回应顺序偏差、处理大数字的数学推理、代理任务的提前终止以及因严格内容过滤导致的失败回应等方面,表现略逊于 GPT 3.5 Turbo。
-
然而,也有亮点:在特别长和复杂的推理任务上,Gemini 的表现优于 GPT 3.5 Turbo;并且,在任务回应不受过滤时,Gemini 在多语言任务上也表现出色。
局限性
最后,我们要指出这些结论存在一些局限性。
首先,我们的研究相当于是对当前不断变化且不稳定的基于 API 的系统的一个时间点的快照。所有这里的结果都是基于 2023 年 12 月 18 日的数据,但随着模型和相关系统的升级,未来这些结果可能发生变化。
其次,这些结果可能受我们选择的特定提示语和生成参数的影响。通过进一步优化提示语设计,或采用多样本和自洽性检验(如 Gemini Team 在 2023 年所做的),结果可能会有显著不同。然而,我们认为,多个任务中一致的结果和标准化的提示语,足以证明我们测试的模型在鲁棒性和泛化指令跟随能力上的可靠性。
最后,不讨论数据泄露(Data Leakage)问题的基准测试论文将是不完整的,这是目前评估大语言模型(Large Language Model)时普遍面临的挑战(Zhou et al., 2023a)。虽然我们没有直接测量数据泄露情况,但我们试图通过在多种不同任务上进行评估来减少这一问题的影响,特别是那些其输出不是源自或在互联网上广泛可见的任务(例如 WebArena)。
展望
根据本文的研究,我们建议研究人员和实践者仔细研究 Gemini Pro 模型,将其作为与 GPT 3.5 Turbo 相当的工具。Gemini 的 Ultra 版本尚未发布,但据称能与 GPT 4 相媲美,因此一旦这一模型推出,对其进行进一步的研究将是非常有价值的。
致谢
作者感谢 Zhiruo Wang 在处理 ODEX 数据集方面的帮助,以及 Shuyan Zhou 在 WebArena 实验上的高层指导。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!