PostgreSQL 技术内幕(十二) CloudberryDB 并行化查询之路
随着数据驱动的应用日益增多,数据查询和分析的量级和时效性要求也在不断提升,对数据库的查询性能提出了更高的要求。为了满足这一需求,数据库引擎不断经历创新,其中并行执行引擎是性能提升的重要手段之一,逐渐成为数据库系统的标配特性。
Cloudberry Database(简称为“CBDB”或“CloudberryDB”)是面向分析和AI场景打造的下一代统一型开源数据库,搭载了PostgreSQL 14.4内核,采用Apache License 2.0许可协议。CBDB在Postgres的基础之上,对已有的并行执行计划进行了大量的调整和优化,实现了显著的性能提升。
在这次的直播中,HashData数据库内核研发专家介绍了Postgres的并行化原理,CBDB在并行化上的优化与改进、功能特性及实践演示。以下内容根据直播文字整理。
并行化查询介绍
PostgreSQL在很多场景下会启用并行执行计划,创建多个并行工作子进程,提升查询效率。PostgreSQL的并行化包含三个重要组件:进程本身(leader进程)、gather、workers。没有开启并行化的时候,进程自身处理所有的数据;一旦计划器决定某个查询或查询中某个部分可以使用并行的时候,就会在查询的并行化部分添加一个gather节点,将gather节点作为子查询树的根节点。
HashData研发团队在对CloudberryDB实现并行化查询时,主要对查询执行算子、Join的实现以及存储引擎并行化扫描等进行了调整和优化。

图1:非并行化查询与并行并查询对比示例
如图1所示,以3个节点的集群为例,在不开启并行化进行Not in操作时,需要耗时50多秒;而在CBDB中开启并行化查询后,用时仅需119毫秒,效率大约提升600倍。
在开启并行化查询时,有以下几处变化:
- Gather Motion从3:1提升至12:1,意味着集群的每个节点上有4个进程在同时并行工作;
- Hash节点变为Parallel Hash;
- 新算子Broadcast Workers Motion 广播每一份数据到一组并行工作的进程中的一个,避免在共享Hash表的情况下出现数据重复。
- 底层的扫描由Seq Scan变为Parallel Seq Scan。
并行扫描原理
在PostgreSQL中,数据以Heap表的形式存储。在读取时,通常有顺序扫描(Seq Scan)、索引扫描(Index Scan)和位图扫描(Bitmap scan)三种扫描方式。接下来,我们对以上三种扫描方式的并行化进行介绍。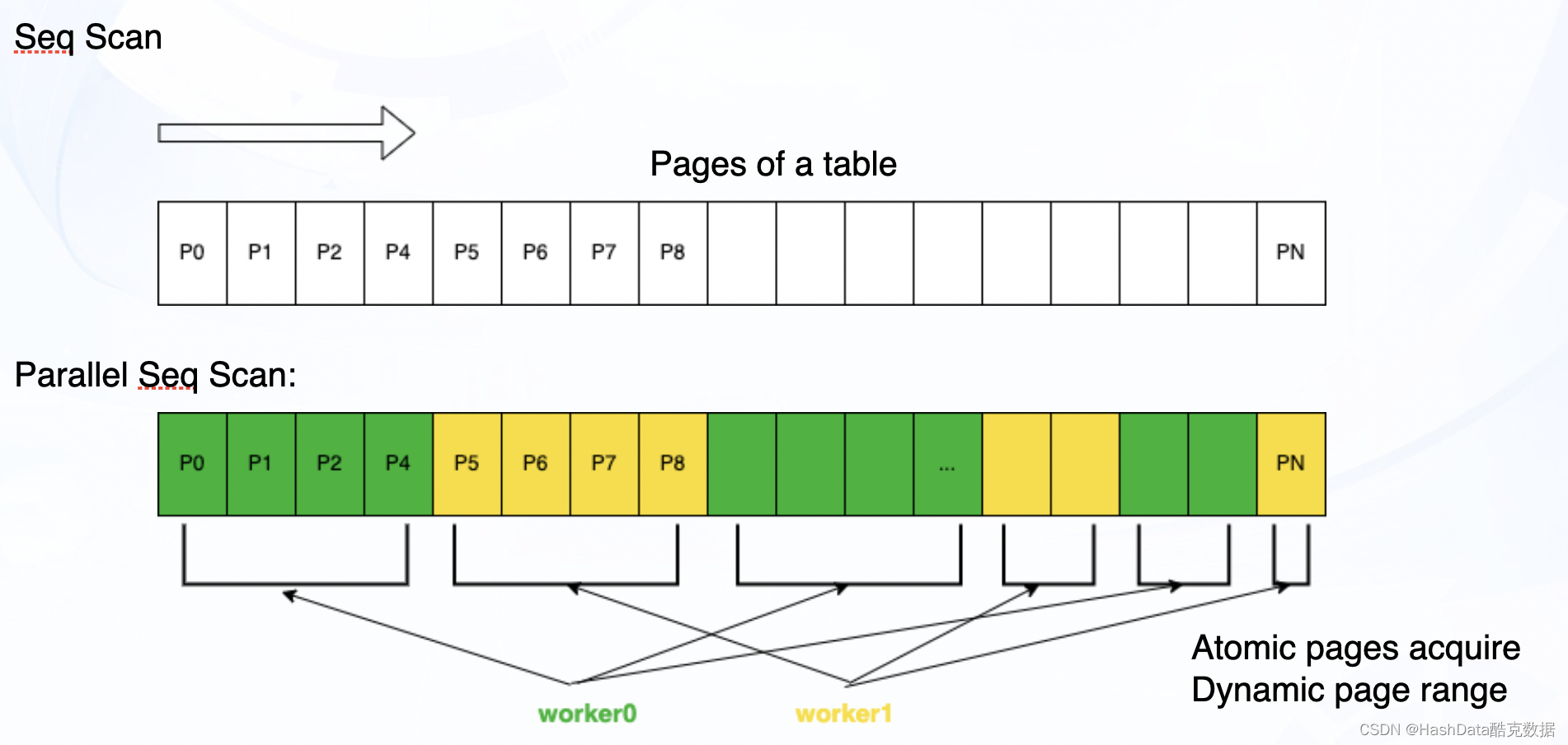
图2:PostgreSQL Heap表并行顺序扫描示意图
如图2所示,在并行顺序扫描时,两个子进程的快照是统一共享的。进程之间通过原子操作动态获得每次要读取的Page范围,避免频繁使用锁从而造成瓶颈。Page的范围并不固定,会根据数据量和读取进度进行动态调整,使得任务尽量均分在不同进程中,避免木桶效应。

图3:PostgreSQL 并行索引扫描示意图
使用索引扫描并行化查询时,子进程只需要读取对应索引的Page,每个进程每次只读取一个索引Page,再读取Heap表数据;如果Page为全体可见,可以不读取Heap表。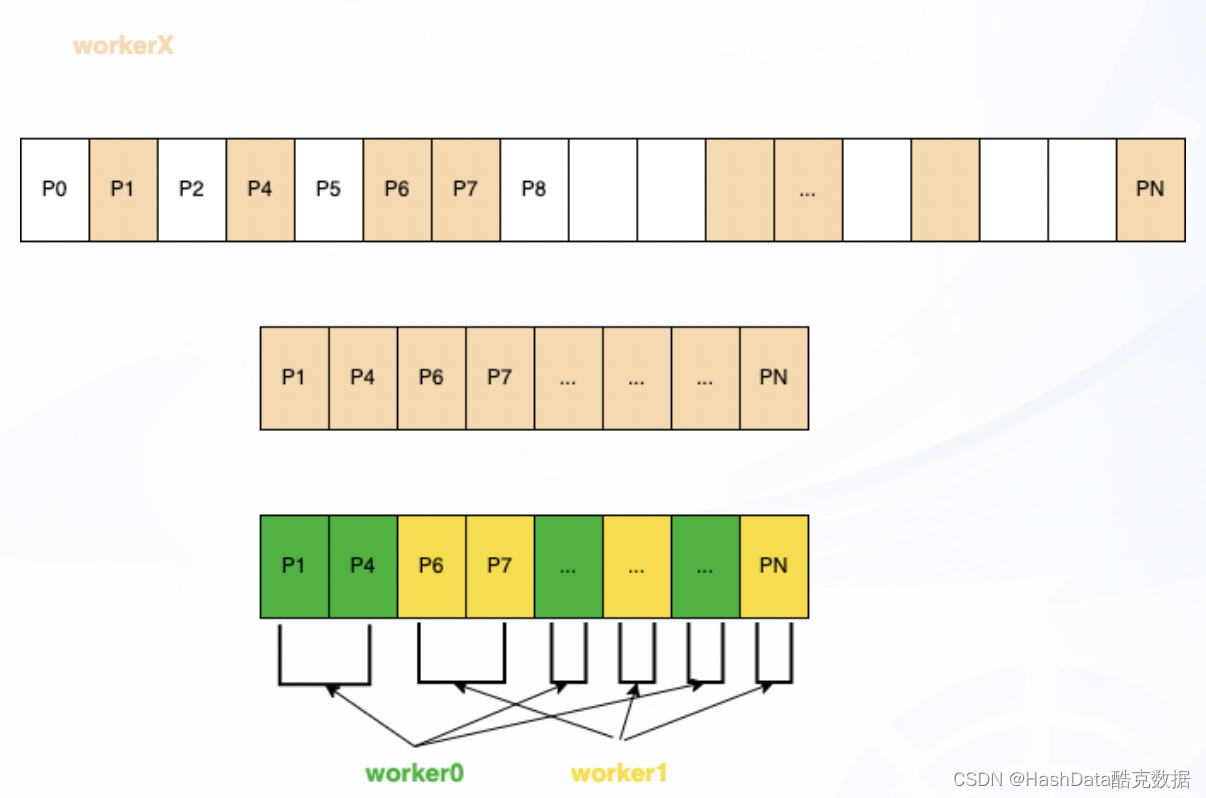
图4:PostgreSQL 并行位图扫描示意图
并行位图扫描在建立底层索引的Page范围时,只有一个进程,按照索引信息(CTID)进行顺序扫描。与PostgreSQL使用leader进程不同的是,CBDB在并行化查询时,会通过竞争的方式选择一个X进程,X进程负责建立位图,之后多个workers竞争读取数据。
图5:CloudberryDB AO表并行化查询示意图
除了Heap表之外,CBDB还引入了AO表,用来专门存储以追加方式插入的元组。如图5所示,AO表的并行扫描是通过原子操作获取Segfiles,让各个进程通过竞争的方式读取数据。
并行Join实现
并行能力的优化需要从多方面来实现,仅凭优化扫描方式能实现的性能提升有限,Join的并行化改造是另一个重要方向。
在PG中有三种Join,分别为Nestloop Join、Merge Join和Hash Join,CBDB对上述三种Join均实现了并行化。此外,一大特色是增加了共享内表的Hash Join(Parallel-aware Hash Join)。
Parallel-aware Hash Join与Hash Join相似,区别在于前者是可以共享的,进程之间相互协作共同建立共享的Hash内表。
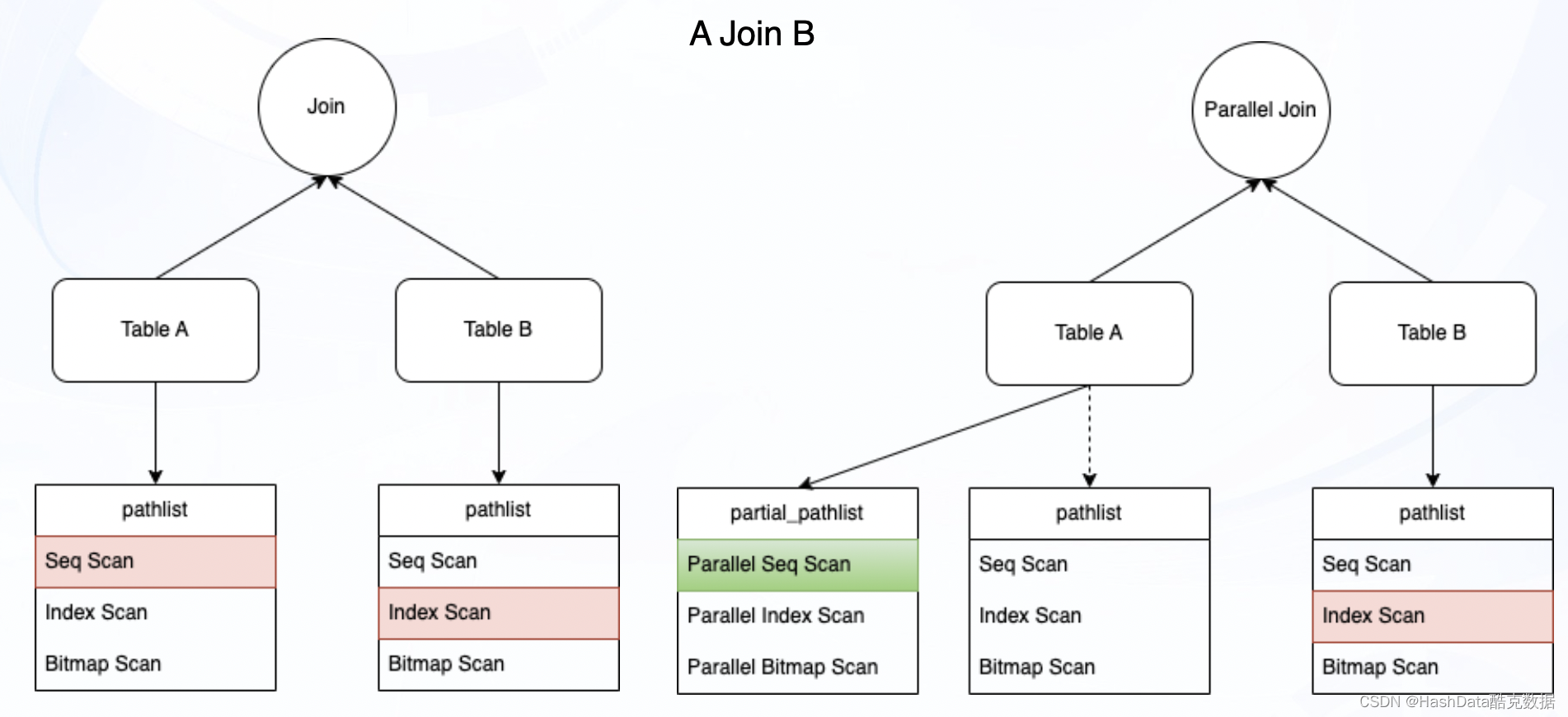
图6:Build a Join并行化实现流程示意图
如图6所示,在PG非并行的情况下,构建Join时从目标对象(Table A、Table B)各选取一条综合代价最低的执行路径,合成Join relations路径。在开启并行化后,会在上述情况下增加一条并行化最佳路径,与非并行化路径构建Join。
数据分布并行化
在Greenplum 中,数据分布有Partitioned、Replicated、Bottleneck三种情况,它们之间可以通过Motion改变Locus的属性进行互相转化,实现数据重分布,CBDB也沿用了这一特性。
图7:CBDB数据分布特性示意图
在CBDB构建Join的时候,可以通过改变Locus进行数据相容。在转化过程中遵循两个原则:
- 在Join时,要保证数据不重复、不丢失;
- 要选择代价最小的方式。
与Greenplum 不同的是,CBDB在开启并行化之后,新建了三个新的Locus 并行模式,实现不同的数据分布:HashedWorkers、SegmentGeneralWorkers和ReplicatedWorkers。 HashedWorkers Locus表示数据分布在同一组进程之间是随机的,但是合并后数据分布变成Hashed Locus。同理,SegmentGeneralWorkers 和ReplicatedWorkers也代表了数据在进程间随机,合并后满足各自的分布状态。
此外,CBDB还实现了并行刷新物化视图、并行Create Table AS、多阶段并行化Aggregation/Limit等。通过以上诸多并行优化措施后,CBDB性能得到大幅度的提升,在特定场景下甚至可以实现千百倍的查询效率提升,支持企业海量数据的复杂分析需求。
图8:CBDB并行化性能曲线图
并行化查询是CBDB在研发立项之初就确定的产品方向,我们希望能够通过多线程并行执行来充分释放现代多核大内存的硬件能力,降低包括IO以及CPU计算在内的处理时间,实现响应时间的大幅下降,更好地提升用户使用体验和业务敏捷度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!