KaiwuDB 时序引擎数据去重功能详解
一、背景介绍
随着物联网领域的快速发展,时序数据的产生和处理需求不断增长。时序数据是按照时间顺序收集和记录的数据,其特点在于数据具有时间戳,并且时间是数据分析和查询的一个重要维度。
在实际场景中,可能存在多条相同时间戳的数据写入数据库中。数据去重功能可以更好地纠正数据的准确性,同时能够节省存储空间,降低存储成本。
本次直播介绍了?KaiwuDB 数据去重功能开发背景、整行去重功能和部分列去重功能的实现方式及使用场景。
1.?数据去重意义
数据去重是指在数据集中删除重复的数据记录,保留唯一的数据记录的过程。
去重功能的意义主要有以下方面:
-
降低数据处理的时间和成本;
-
提高存储空间的利用率;
-
提高数据分析的准确性;
-
增强数据的质量和可靠性。
2.?数据去重背景
(1)数据整行去重
数据整行去重是指时序表可以支持时间戳下多条数据的写入去重,后写入的数据会覆盖前条数据。
数据整行去重功能打开后,第一次成功插入的数据能够被成功查询到,且若后续再次出现相同时间戳数据,该数据亦可被更新。相同时间戳的数据写入成功后,某一时间戳下仅存在一条最新数据。
(2)数据部分列去重
数据部分列去重是指时序表支持相同时间戳的不同列分批插入表,会更新整合成一条数据。
写入一条数据后,当前写入重复数据亦可被更新(整条或单列)。数据写入成功后,某一时间戳下仅存在 1 条最新数据,空的列会与其他重复数据合并。
二、KaiwuDB 去重功能
1. 概念说明
-
顺序数据:正在写入的记录时间戳比表中所有记录最大的时间戳还要大。
-
乱序数据:不满足顺序数据定义的正在写入的记录,都归属于乱序数据。
-
重复数据:重复数据一定是乱序数据,因为表中已经存储这个时间戳的记录,属于乱序数据中的一种特殊数据。
-
时序数据:按照时间顺序收集和记录的数据,其特点在于数据具有时间戳,并且时间是数据分析和查询的一个重要维度。

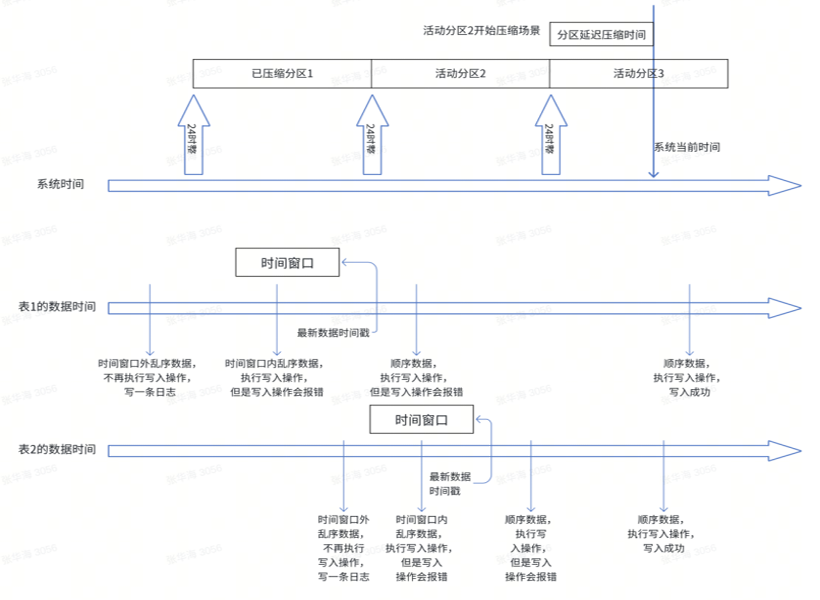
如图中所示,写入以存储的最新数据的时间戳作为分割线,往后的数据都是顺序数据范围,而分割线之后的数据都是乱序数据。
2.?去重的前提-乱序数据处理
乱序数据处理功能是指支持对时序表写入的数据乱序场景进行处理。比如在特定时间窗口内( 10 分钟或 1 小时)内的乱序数据会存储下来,时间窗口外的按照特定的规则处理(过滤掉数据,写入一条告警日志)。
乱序数据处理功能是为了能按照数据时间戳分区,使得数据库尽可能禁止向压缩分区写数据。
乱序数据的处理是基于乱序时间窗口来做的,乱序时间窗口指表最新数据时间戳的时间点一直到往前的一段时间的时间范围,每个表的时间窗口都不一样,如果表没有新数据的写入,则它的时间窗口不会变。
如图中所示,超过时间窗口的乱序数据是不能够写入成功的。顺序数据写入能够正常写入成功,但是如果是往已压缩分区写数据,能够写入成功,会在 log 中打印一条乱序数据。
3. 数据去重功能
重复数据是乱序数据中特殊数据类型,数据去重功能是对乱序数据处理机制的补充和完善。数据去重处理的数据范围是乱序时间窗口内的重复数据,乱序时间窗口外的重复数据会被丢弃掉。
数据去重处理也会保留之前乱序数据处理中对重复数据的处理策略,并在此基础上,扩展出更新、拒绝、忽略等去重策略。
(1)重复数据查询算法
数据去重功能也是基于乱序时间窗口机制实现的。基于此机制,KaiwuDB 实现了重复数据查询算法:
-
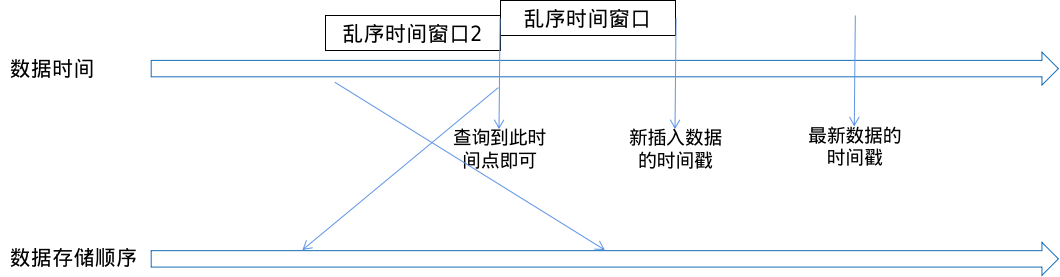
从数据时间线上来说,只要查询时间范围为【正在插入的数据时间戳 - 乱序时间窗口,正在写入的数据时间戳】内的记录,并判断是否时间戳相同,就能过滤出正在插入的重复记录。
-
从最新数据的时间戳往时间戳小的方向遍历,(正在插入的数据时间戳 - 乱序时间窗口)这个时间戳的记录不一定存在,因此,需要遍历找到比(正在插入的数据时间戳 - 乱序时间窗口)小的时间戳即可。(算法 1)
-
但由于插入的数据是乱序的,可能存在如下图乱序时间窗口 2 内的乱序,大于(正在插入的数据时间戳 - 乱序时间窗口)记录会存储在(正在插入的数据时间戳 - 乱序时间窗口)时间戳的前面,算法 1 就不能遍历到。
此种情况最坏结果是两个乱序时间窗口串联,即乱序时间窗口2的结束时间与乱序时间窗口的开始时间相同,此时,需要遍历找到比(正在插入的数据时间戳 - 2 * 乱序时间窗口)小的时间戳。
通过重复数据查询算法,得到相同时间戳的记录为重复记录,放入重复记录数组中。
(2)整行去重
通过重复数据查询算法查询到相关重复数据后,如果是整行去重,在写入时,会将最新的数据写入数据库中,写入成功后,将查到的重复数据做删除标记,后续会删除。
写入流程如图所示:

(3)部分列去重
部分列去重策略,会补齐正在插入记录中数值为空的列。当正常插入记录的第 X 列为空时,我们遍历重复记录数组,找到第 X 列不为空的数值,当有多个数值时,取最近插入的记录中的第 X 列的数值。
如下图,重复记录 1 插入早于重复记录 2,当正在插入的记录如下图时,部分列去重规则产生的新记录每列取值为标绿的数值。

三、KaiwuDB 去重功能应用场景
1. 默认去重策略
-
场景说明:没有配置去重策略,启动 KaiwuDB 并插入三条时间戳相同的记录。
-
用户行为:没有在配置文件中设置去重参数
-
系统行为:KaiwuDB 启动默认的去重策略:不去重,三条记录都可以写入成功,并且都能被查询到。
2.?配置去重策略为 reject
-
场景说明:配置去重策略,启动 KaiwuDB,连续三次执行 insert 语句插入时间戳相同的记录。
-
用户行为:参数配置为 reject - 禁止插入重复数据。
-
系统行为:第一条记录插入成功,后面两条记录插入时报错只有第一条记录存储,并且可以被查询到。
3. 配置去重策略为 override
-
场景说明:配置去重策略,启动 KaiwuDB,一条 insert 语句中同时插入三条时间戳相同的记录。
-
用户行为:参数配置为 override - 只保留最新整行记录。
-
系统行为:Insert 语句执行成功,查询时,只有第三条记录能够被查询到。
4. 配置去重策略为 merge
-
场景说明:配置去重策略,启动 KaiwuDB,插入三条时间戳相同的记录。
-
用户行为:参数配置为 merge - 历史数据合并。
-
系统行为:三条 insert 语句执行成功,查询时,只返回一条合并记录。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!