Transformer-MM-Explainability
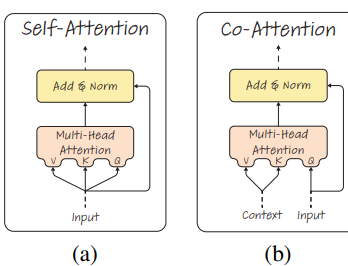
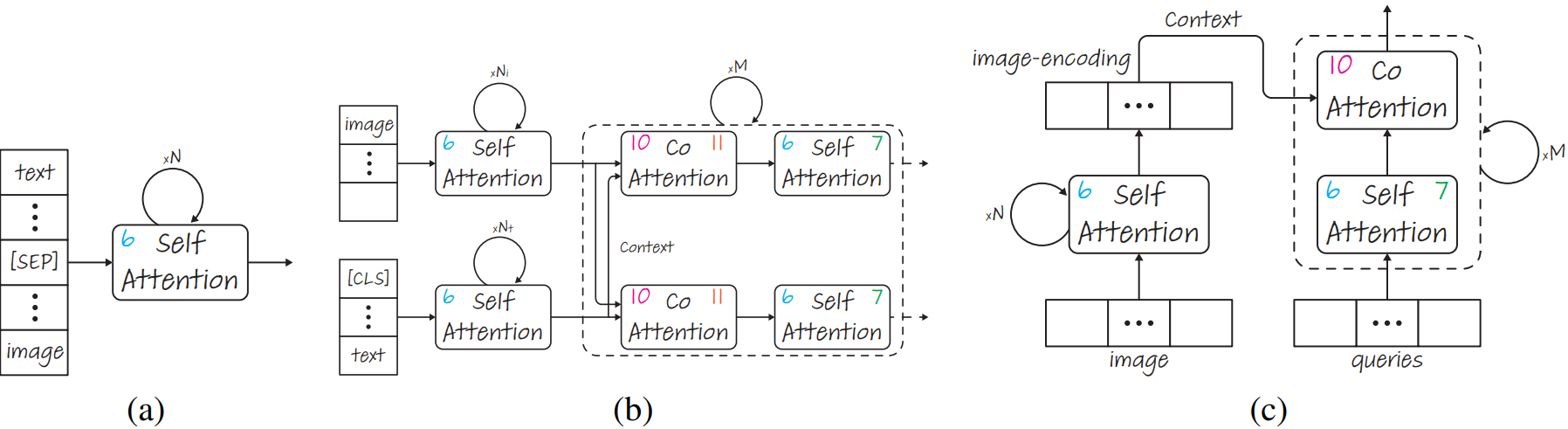
two modalities are separated by the [SEP] token,the numbers in each attention module represent the Eq. number.
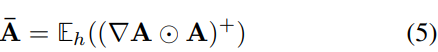
E
h
_h
h? is the mean,
?
\nabla
?A :=
?
y
t
?
A
{?y_t}\over?A
?A?yt??for
y
t
y_t
yt? which is the model’s output.
⊙
\odot
⊙ is the Hadamard product,remove the negative contributions before averaging.
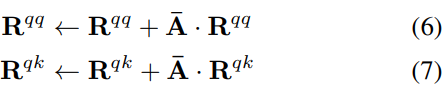
aggregated self-attention matrix R
q
q
^{qq}
qq,previous layers’ mixture of context is embodied by R
q
k
^{qk}
qk.
感想
作者的实验在coco和ImageNet验证集上做的,不好follow
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!