分库分表后,id主键处理的几种方式:
1. MySQL主键自增
这个方案就是利用了MySQL的主键自增auto_increment,默认每次ID加1。
优点:
1).数字化,id递增
2).查询效率高
3).具有一定的业务可读
缺点:
1).存在单点问题,如果mysql挂了,就没法生成ID了
2).数据库压力大,高并发抗不住
2.UUID
这个方案是小伙伴们第一个能过考虑到的方案
优点:
1).代码实现简单。
2).本机生成,没有性能问题
3).因为是全局唯一的ID,所以迁移数据容易
缺点:
1).每次生成的ID是无序的,无法保证趋势递增
2).UUID的字符串存储,查询效率慢
3).存储空间大
4).ID本事无业务含义,不可读
应用场景:
1).类似生成token令牌的场景
2)不适用一些要求有趋势递增的ID场景
3.Twitter开源的雪花算法
雪花算法通过64位有特殊含义的数字来组成id。
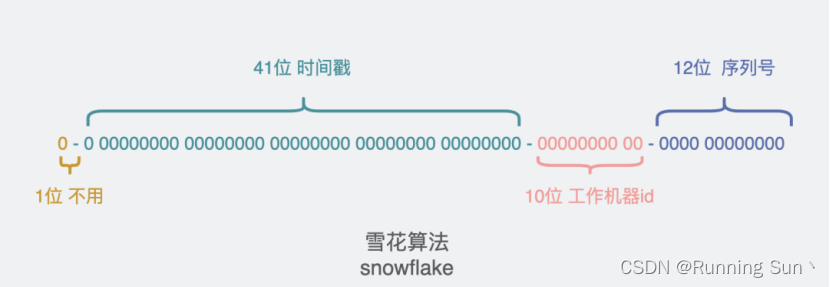
1).首先第0位不用。
2).接下来的41位是时间戳。精度是毫秒,这个大小大概能表示个69年左右,因为时间戳随着时间流逝肯定是越来越大的,所以这部分决定了生成的id肯定是越来越大。
3).再接下来的10位是指产生这些雪花算法的工作机器id,这样就可以让每个机器产生的id都具有相应的标识。
4).再接下来的12位,序列号,就是指这个工作机器里生成的递增数字。
可以看出,只要处于同一毫秒内,所有的雪花算法id的前42位的值都是一样的,因此在这一毫秒内,能产生的id数量就是2的10次方到2的12次方,大概400w,肯定是够用了,甚至有点多了。
优点:
1).此方案每秒能够产生409.6万个ID,性能快
2).时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增
3).灵活度高,可以根据业务需求,调整bit位的划分,满足不同的需求
缺点:
依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成
4.Redis生成方案
利用redis的incr原子性操作自增,一般算法为:
年份 + 当天距当年第多少天 + 天数 + 小时 + redis自增
优点:
有序递增,可读性强
缺点:
占用带宽,每次要向redis进行请求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!