机器学习期末复习
选择题
-
机器学习利用经验 ,须对以下()进行分析
A 天气 B 数据 C 生活 D 语言 -
归纳偏好值指机器学习算法在学习的过程中,对以下()的偏好
A 数据 B 某种类型假设 C 标记 D 运行速度 -
有的情况下 ,模型学习到了训练数据满足的特有性质,但这些性
质不是一般规律,这种现象被称为()
A 欠拟合 B 过拟合 C 欠配 D 以上三个选项都不是 -
最小二乘法估计 得到的线性回归模型 满足()性质
A 均方模型为 0 B 均方误差偏大 C 均方误差偏小 D 均方误差为 1 -
下列()是决策树的预测过程。
A 将测试示例从一个中间节点开始,沿着划分属性所构成的“判
定测试序列”下行,知道叶节点、
B 将测试实例从一个中间节点开始,沿着划分属性所构成的“判
定测试序列”上行,直到根节点。
C 将测试示例从叶节点开始,沿着划分属性 所构成的“判定测试
序列”上行,直 到根节点。
D 将测试示例从根节点开始,沿着划分属性所构成的“判定测试
序列”下行,直到叶节点。 -
BP 算法基于()策略对参数进行调整
A 梯度下降 B 梯度上升 C 最小化误差 D 误差逆传播 -
当训练样本线性不可划分时可采用()来缓解和解决
A 增加正例样本 B 核函数 C 训练误差最小 D 测试误差最小 -
朴素贝叶斯分类器中,对给定类别,模型对所有属性间的独立性
有()
A 部分不独立 B 部分独立 C 相互不独立 D 相互独立 -
KNN(L 近邻算法)属于一种典型的()算法
A 监督学习 B 无监督学习 C 半监督学习 D 弱监督 -
缓解维数灾难的操作是()
A 降维 B 升维 C 低维度嵌入 D 流型处理 -
决策树属于()模型。-
A.判别式 B.生成式 C.判别式和生成式 D.以上都不对 -
先对联合概率分布P(x, c)建模,再由此获得P(clx),属于()模型。
A.判别式 B.生成式 C.回归 D. 以上都不是 -
贝叶斯公式中,估计后验概率P(c|x)的主要困难在于估计()。
A. P(c) B. P(x|c) C.以上两者都是 D.以上两者都不是 -
下列()方法可以用来获得从原始数据集中划分出“测试集”?
A.留出法 B.交叉验证法 C.自助法 D.以上三个选项都可以 -
在训练集上的误差被称作()
A.泛化误差 B.经验误差 C.测试误差 D.以上三个选项都不对 -
当西瓜收购公司去瓜摊l收购西瓜时既希望把好瓜都收走J尽可能的少,请问他应该考虑()评价指标?
A.精度 B.查全率 C.查准率 D.F1度量 -
信息嫡是度量样本集合()最常用的一种指标。
A.纯度 B.对称差 C.大小 D.重要性 -
在属性划分中,信息增益越大,结点的纯度( )。
A.不变
B.变为零
C.提升越大
D.降低越快 -
剪枝是决策树学习算法对付()现象的主要手段。
A.标记噪声
B.数据少
C.过拟合
D.欠拟合 -
多层感知机表示异或逻辑时最少需要()个隐含层(仅考虑二元入)。
A. 1 B. 2 C. 3 D. 4
答案:BBBCD ABDAA ABBDB DACCB
名词解释:
- 奥卡姆剃刀原则: 是一种科学原则,在解释现象时,应该选择最简单的解释和假设
- 归纳偏好: 是指在遇到不完全信息或不确定性情况下,人们对于潜在解释或假设的倾向和偏好
- 线性模型: 是一种常见的机器学习模型,用于建立输入特征与输出变量之间的线性关系
- 线性回归:是一种常见的线性模型,用于建立输入特征与连续输出变量之间的线性关系
- 最小二乘法: 是一种常用的拟合方法,最小化预测值与真实值之间的残差平方和来确定模型的参数
- 类别不平衡: 是指在分类问题中,不同类别的样本数量存在较大差异
- 决策树: 是一种常见的机器学习算法,主要用于回归和分类任务,通过创建一个树形结构,将复杂的任务分解成一系列简单的决策分支,进而解决复杂的分类和回归问题。通常用于有监督的学习,可以训练数据集进行学习和预测
- 神经网络: 是一种模拟脑部神经系统的模型,由大量人工神经元相互连接构成。通过模拟神经元之间的连接和信息传递来实现复杂的信息处理,神经元之间连接的权重可以通过学习算法来进行调整,以使得神经网络可以学习和适应不同的任务和数据
- 间隔(margin): 是指支持向量机中分类器的决策边界与最近的分类样本之间的距离,间隔越大,泛化能力越强
- 贝叶斯决策论:是一种基于概率统计理论的决策方法,通过计算不同决策的期望损失来选择最优的决策,用于处理分类问题
- 急切学习: 一种机器学习的方法,在训练阶段就构造一个模型进行学习,并用它进行预测
- 懒惰学习:与急切学习相反
简答题
1.机器学习:
是人工智能的一种分支,让计算机从数据中学习和改进,以完成某种任务,目标是让计算机在经验中学习,自动发现模式和规律,并运用规律进行预测和决策
2.过拟合及缓解方法:
指模型在训练数据集上表现良好,但在新数据或测试集上表现不好的现象。通常是由于模型过于复杂,使得模型在训练的过程中过分注重与特定细节,而没有真正掌握数据的底层结构和一般规律
缓解方法:增加训练数据量,提供更多的数据样本供模型学习,减少过拟合的风险;降低模型的复杂度,减少模型的自由度;或者通过正则化限制模型的学习能力
3.有监督和无监督学习:
有监督的学习是指模型在训练数据中,每个样本都有对应的标签和目标输出,模型通过学习输入与输出的映射关系进行预测和决策
无监督的学习是指模型在训练数据中,每个样本没有对应的标签和目标输出,模型通过学习数据的内在结构和相似性进行聚类、降维或异常检测等任务
4.查准率和查全率:
查准率又称精确率,是指在预测为正类的样本中真正类所占的比例,衡量分类模型在某一分类预测上的准确性。
查全率又称召回率,是指在实际为正类的样本中真正类所占的比例,衡量分类模型在某一分类预测上的完整性。
5.P-R曲线怎么对学习器进行比较
P-R曲线是以P查准率为横轴,R查全率为纵轴绘制的曲线。通过改变分类的阈值来得到不同的P-R点,比较不同学习器的性能,可以通过曲线下的面积AUC,越接近1越好,或者F1-score来判断
6.真正例率和假正例率
真正例率(TPR)是表示实际为正例的样本中被正确预测为正例的比例,TPR=TP/TP+FN
假正例率(FPR)是表示实际为负例的样本中 被错误预测为正例的比例,FPR=FP/FP+TN
7.简述线性判别分析LDA
LDA的主要思想是选择一个投影方向,将数据投影,使得相同类别的数据尽可能紧凑,不同类别的数据尽可能分开
步骤:①计算类内散度矩阵和类间散度矩阵
②计算投影方向
③降维
8.决策树对过拟合的主要手段是什么?该手段的优缺点是什么?
主要手段是剪枝
预剪枝的优点是计算效率高和避免过拟合,缺点是容易信息丢失,导致欠拟合
后剪枝的优点是包括更好的泛化能力和不容易欠拟合,缺点是计算开销大,容易过拟合
9.简述M-P神经元模型的组成及每一部分的作用
M-P神经元是由输入部分和激活函数构成
输入部分接收外部输入信号,并赋予每个输入相应的权重
激活函数会根据输入信号的加权和是否超过神经元的阈值来决定是否激活神经元
10.神经网络对于过拟合的有效手段
正则化,通过在损失函数中加入正则化,如L1正则化或L2正则化,以惩罚模型的复杂度,防止模型过度拟合数据
早停法,通过在训练中监控验证集的性能表现,当模型性能不再提升时,停止训练,防止模型过度拟合数据
11.卷积神经网络CNN的结构和作用
输入层:接收原始数据
卷积层:提取特征
激活函数:增加非线性
池化层:减少特征图尺寸
全连接层:将特征进行分类和回归
卷积神经网络结构有:输入层、卷积层、激活函数、池化层、全连接层
12.支持向量机的基本型和稀疏性解释
包括线性SVM和非线性SVM,=> min w,b 1/2||w||2
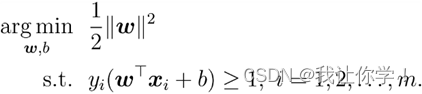
稀疏性指在训练数据时,只有少量数据成为支持向量,只有少数样本对模型有影响作用
13.朴素贝叶斯分类器和半朴素贝叶斯分类器区别
区别在于两者对于数据样本处理的特征依赖关系不同,朴素贝叶斯分类器假设特征之间相互独立;
半朴素贝叶斯分类器允许特征之间存在一定的依赖关系
14.聚类算法和性能度量
聚类算法将数据样本划分为不同的类别或簇,不同类别的样本相似度较高,同一类别的相似度较低。性能度量是检测聚类算法的质量,包括聚类准确度、轮廓系数等,聚类准确度是指分类正确的样本占样本总数的比例,轮廓系数是指簇内紧密度和簇间分离度的平衡程度
计算题
一、线性回归
(1)什么是“线性回归”目的?
找到一条直线或一个平面或更高维的超平面,使得预测值与真实值之间的误差最小化。
(2)给出单一属性的线性回归目标函数。
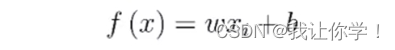
(3)若用最小二乘法求解线性回归模型,给出最小二乘法的闭式解(w和b)及其推导过程。

二、决策树
(1)简述决策树学习的目标,并列举两种度量样本集合纯度最常用的指标。
目标:在训练数据集上构建一棵决策树,使得该决策树能够对新的未知数据进行分类或回归预测,同时保证分类或预测的准确性。
指标举例:基尼指数、信息增益。
(2)“信息熵”是度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为pk,k=1,2,…∣Y∣,写出D的信息熵Ent(D)的公式表达。
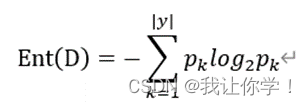
(3)假定离散属性a有V个可能的取值{a1,a2,…,aV},使用a来对样本集D进行划分,写出属性a对样本集合D进行划分所获得的信息增益的公式表达。
Gain(D,a) = Ent(D) - ∑p(v) * Ent(D_v)
(4)以属性“根蒂”为例,其对应的3个数据子集分别为D1(根蒂=蜷缩),D2(根蒂=稍蜷),D3(根蒂=硬挺),分别写出计算,Ent(D1)、Ent(D2)和Ent(D3)的过程。
D1(根蒂=蜷缩)有8个,其中正例5个,反例3个,D2(根蒂=稍蜷)有7个,其中正例3个,反例4个,D3(根蒂=硬挺)有2个,正例0个,反例2个,由此得出:
Ent(D1)= -((5/8)*log2(5/8)+ (3/8)*log2(3/8))
Ent(D2)= -((3/7)*log2(3/7)+ (4/7)*log2(4/7))
Ent(D3)= -((0/2)*log2(0/2)+ (2/2)*log2(2/2))
三、贝叶斯
两类的先验概率分别为:0.8和0.2。现有一待识别的鱼,其鱼的光泽度指标x,从类条件概率密度分布曲线上查得鲈鱼:P(x|c1) = 0.15;鲑鱼: P(x|c2) = 0.5。
(1)简述朴素贝叶斯分类器原理。
朴素贝叶斯分类器基于贝叶斯定理与特征条件独立假设,通过计算给定样本属于某个类别的概率,选择概率最大的类别作为预测类别。
(2)请给出后验概率P(c|x)和贝叶斯判定准则的具体式子。
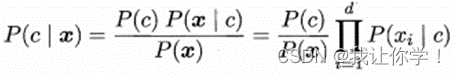
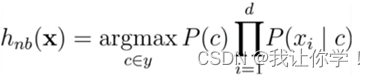
(3)使用贝叶斯决策对鱼的类别进行预测。
P(c1|x) = (0.8×0.15)/(0.8×0.15+0.2×0.5)=0.12/(0.12+0.1) = 0.545
P(c2|x) = (0.2×0.5)/(0.8×0.15+0.2×0.5)=0.1/(0.12+0.1) = 0.454
由于P(c1|x)>P(c2|x),根据贝叶斯判定准则,将该鱼判定为鲈鱼。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!