【产品】业务场景常用算法学习笔记
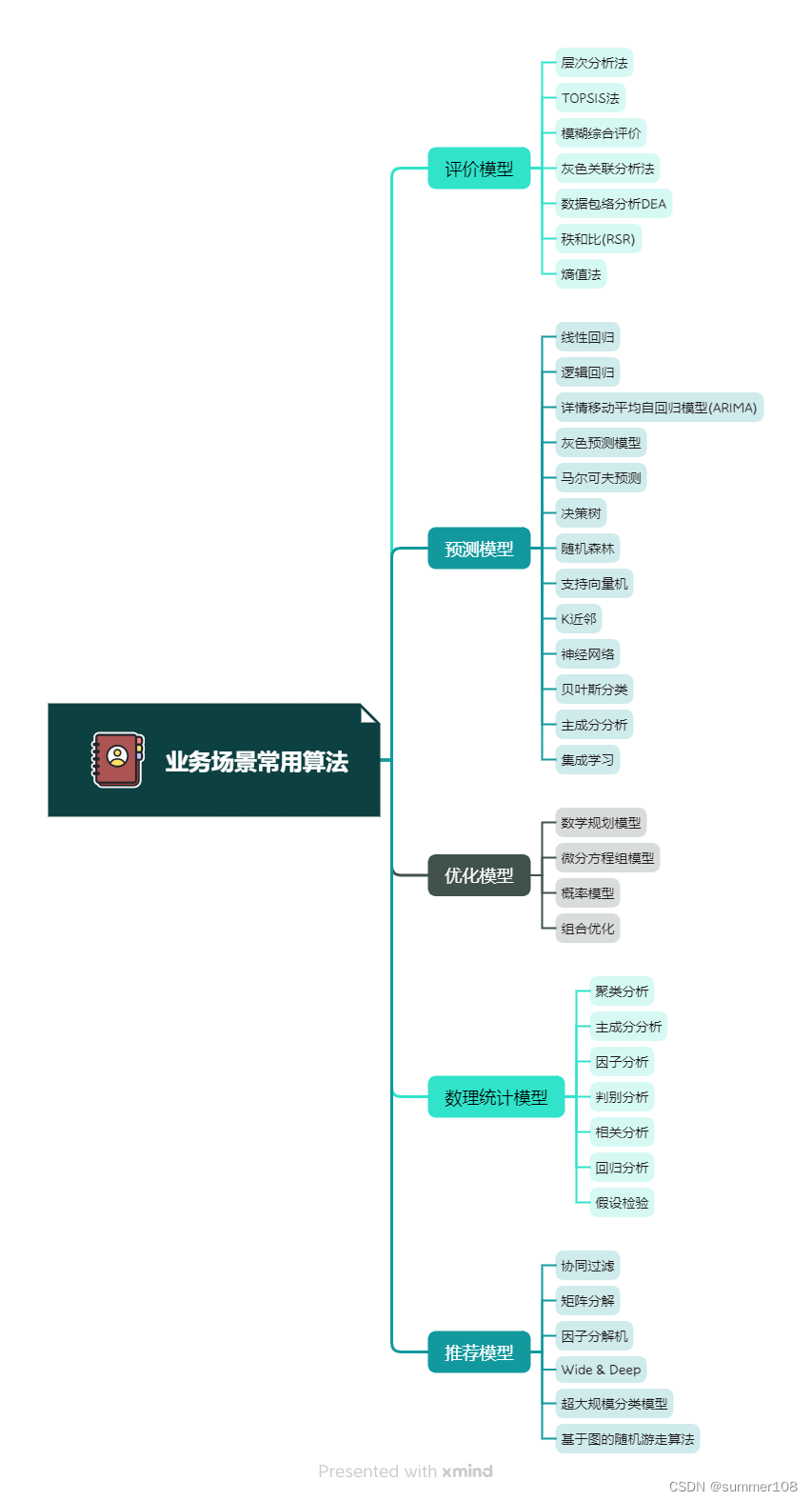
评价模型 (Evaluation Model)
评价模型用于对某个系统、方案或决策进行评估。通过构建合适的指标和评价方法,评价模型能够对不同方案的优劣进行比较和分析。在数学建模比赛中,评价模型通常根据问题的特点和需求,设计合适的评价标准和指标,对不同方案或模型的性能进行评估和比较,以帮助做出决策。
- 层次分析法:AHP层次分析法是一种解决多目标复杂问题的定性和定量相结合进行计算决策权重的研究方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。
- TOPSIS法:用于研究与理想方案相似性的顺序选优技术,通俗理解即为数据大小有优劣关系,数据越大越优,数据越小越劣,因此结合数据间的大小找出正负理想解以及正负理想解距离,并且在最终得到接近程序C值,并且结合C值排序得出优劣方案排序。
- 模糊综合评价:借助模糊数学的一些概念,对实际的综合评价问题提供评价,即模糊综合评价以模糊数学为基础,应用模糊关系合成原理,将一些边界不清、不易定量的因素定量化,进而进行综合性评价的一种方法。
- 灰色关联分析法:通过研究数据关联性大小(母序列与特征序列之间的关联程度),通过关联度 (即关联性大小) 进行度量数据之间的关联程度,从而辅助决策的一种研究方法。
- 数据包络分析DEA:是一种多指标投入和产出评价的研究方法,其应用数学规划模型计算比较决策单元(DMU) 之间的相对效率,对评价对象做出评价。比如有10个学校(即10个决策单元DMU,Decision Making Units),每个学校有投入指标(比如学生人均投入资金),也有产出指标 (比如学生平均成绩,,学生奥数比赛比例等),有的学校投入多,有的学校投入少,但是投入多或少,均会有对应的产出,那么具体那个学校的投入产出更加优秀呢,诸如此类问题,则可使用数据包络DEA模型进行分析。
- 秩和比(RSR):是指分析方法可用于评价多个指标的综合水平情况,其实质原理是利用了RSR值信息进行各项数学计算,RSR值介于0~1之间且连续,通常情况下,该值越大说明评价越“优’。
- 熵值法:熵值法是指用来判断某个指标的离散程度的数学方法。离散程度越大,该指标对综合评价的影响越大。利用信息熵这个工具,计算出各个指标的权重,为多指标综合评价提供依据。
预测模型 (Prediction Model)
预测模型能够根据过去的数据和观察结果,对未来的趋势、行为或结果进行预测和推断。预测模型常用于分析时间序列数据、趋势预测、行为模式预测等问题。在数学建模比赛中,预测模型可以根据给定的数据集或者特定规律,构建合适的数学模型,进行未来趋势预测,从而帮助做出决策或规划。
- 线性回归(Linear Regression):线性回归是一种常见的预测算法,其基本思想是通过拟合一条直线来预测一个连续的数值。线性回归可以用于解决回归问题,例如房价预测、股票价格预测等。适用情景:当自变量与因变量之间存在线性关系,连续性因变量,预测数值型数据。
- 逻辑回归(Logistic Regression):逻辑回归是一种常见的分类算法,其基本思想是通过拟合一条S形曲线来预测一个二元变量的概率。逻辑回归可以用于解决二元分类问题,例如信用风险评估、疾病诊断等。适用情景:当因变量是定类数据,预测概率。
非线性回归:当自变量与因变量之间存在非线性关系,连续性因变量,可以拟合曲线、曲面等复杂模式,预测非线性关系的数值型数据。 - 移动平均自回归模型(ARIMA):利用历史数据可以预测前来的情况。ARIMA模型可拆分为3项,分别是AR模型,I即差分,和MA模型。
- 灰色预测模型:灰色预测模型可针对数量非常少 (比如仅4个),数据完整性和可靠性较低的数据序列进行有效预测,其利用微分方程来充分挖掘数据的本质,建模所需信息少,精度较高,运算简便,易于检验,也不用考虑分布规律或变化趋势等。但灰色预测模型一般只适用于短期预测,只适合指数增长的预测,比如人口数量,航班数量,用水量预测,工业产值预测等。
- 马尔可夫预测:马尔可夫预测是一种基于马尔可夫链的预测方法。马尔可夫链是一个随机过程,具有马尔可夫性质,即未来状态的概率只取决于当前状态,与过去状态无关。马尔可夫预测利用这种性质来进行未来事件的预测。
- 决策树(Decision Tree):决策树是一种常见的分类和回归算法,其基本思想是通过构建一棵树来预测一个离散或连续的数值。决策树可以用于解决多类别分类问题、回归问题、异常检测等。
- 随机森林(Random Forest):随机森林是一种基于决策树的集成学习算法,其基本思想是通过构建多个决策树来预测一个离散或连续的数值。随机森林可以用于解决多类别分类问题、回归问题、异常检测等。
- 支持向量机(Support Vector Machine):支持向量机是一种常见的分类算法,其基本思想是通过构建一个分割超平面来将不同类别的数据分开。支持向量机可以用于解决二元和多元分类问题、回归问题等。所谓二分类模型是指比如有很多特征(自变量X) 对另外一个标签项 (因变量Y)的分类作用年龄、学历、收入、教关系,比如当前有很多特征,包括身高、育年限等共5项,因变量为是否吸烟,“是否吸烟’仅包括两项,吸烟和不吸烟。那么该5个特征项对于“是否吸烟’的分类情况的作用关系研究,则称为“二分类模型’,但事实上很多时候标签项(因变量Y)有很多个类别,比如某个标签项Y为“菜系偏好’,中国菜系有很多,包括川菜、鲁菜、粤菜、闽菜、苏菜、浙菜、湘菜和徽菜共计8类,此时则需要进行“多分类决策函数’转化,简单理解为两两类别(8个中任意选择2) 分别建立SVM模型,然后组合使用。
- K近邻(K-Nearest Neighbor):K近邻是一种基于距离度量的分类算法,其基本思想是根据相邻的K个样本的类别来预测一个新样本的类别。K近邻可以用于解决多类别分类问题、回归问题等。
- 神经网络(Neural Network):神经网络是一种模拟人类神经系统的计算模型,其基本思想是通过构建多个神经元和多层神经元之间的连接来预测一个离散或连续的数值。神经网络可以用于解决分类问题、回归问题等。神经网络有多种,包括BP神经网络、卷积神经网络,多层感知器MLP等最为经典为神经网络为多层感知器MLP,SPSSAU默认使用该模型。类似其它的机器学习模型,神经网络模型构建时首先将数据分为训练集和测试集,训练集用于训练模型,测试集用于测试模型的优劣,并且神经网络模型可用于特征重要性识别、数据预测使用,也或者训练好模型用于部署工程使用等。
- 贝叶斯分类(Bayesian Classification):贝叶斯分类是一种基于贝叶斯定理的分类算法,其基本思想是通过计算一个新样本属于某个类别的概率来进行分类。贝叶斯分类可以用于解决文本分类、垃圾邮件分类等。
- 主成分分析(Principal Component Analysis):主成分分析是一种常见的降维算法,其基本思想是通过线性变换将高维数据映射到低维空间中,从而减少特征维度,提高模型的效率。主成分分析可以用于解决图像识别、信号处理等。
- 集成学习(Ensemble Learning):集成学习是一种将多个分类器组合起来进行预测的方法,其基本思想是通过投票、加权平均等方式来获得更加准确的预测结果。集成学习可以用于解决分类问题、回归问题等。
优化模型 (Optimization Model)
优化模型旨在找到使某个目标函数取得最大或最小值的最优解。优化模型适用于求解最佳决策、资源分配、排产安排等问题。在数学建模比赛中,优化模型可以通过建立数学规划模型,确定决策变量、约束条件和目标区数,利用求解方法寻找最优解或次优解,以优化问题的方案或决策。
- 数学规划模型:一种利用数学方法求解优化问题的工具。它包括了目标函数、约束条件和决策变量三个主要部分。目标函数描述了要最大化或最小化的目标,约束条件则是对决策变量取值的限制,决策变量则是需要优化的变量。不同类型的数学规划模型包含了不同的数学方法和技巧,如线性规划、非线性规划、整数规划等。通过建立合适的数学规划模型并运用相应的求解算法,可以实现优化问题的高效求解。
- 微分方程组模型:一种描述多个变量随时间或空间的变化而产生的关系的数学模型。数学建模中常用的微分方程组模型包括生物学中的Lotka-Volterra模型、流体力学中的Navier-Stokes方程、电路分析中的Kirchhoff定律、经济学中的IS-LM模型等微分方程组模型通常由多个微分方程组成,每个微分方程描述一个变量的变化规律,并与其他微分方程相互关联。使用微分方程组模型可以描述许多自然现象和工程问题,如流体力学、电路分析、人口增长等。为了求解微分方程组模型,需要运用微积分和数值方法,如欧拉法、龙格一库塔法等,对微分方程进行数值逼近,得到近似解或精确解。
- 概率模型:决策模型、随机存储模型、随机人口模型、报童问题、Markov链模型等。这些模型可以描述各种实际问题中存在的随机性,如金融市场波动、天气预报误差、网络通信丢包等。通过对概率模型进行求解和分析,可以得到相应问题的概率分布、期望值、方差等统计量,并为决策、优化和风险管理提供重要的参考依据。概率模型在各个领域都有广泛的应用。
- 组合优化:数学建模中的组合优化指的是利用离散数学和算法理论方法来解决组合优化问题的数学模型。这些问题通常涉及如何从一个给定集合中选取一些元素,使得满足一定的限制条件并达到最优化目标,如最大化利润、最小化成本、最大化效率等。组合优化问题在各个领域都有广泛的应用,如物流、生产调度、网络设计、金融投资等。通过对组合优化模型进行求解,可以得到最优化方案和相应的优化目标值,并为相关领域的决策和规划提供重要的支持。
数理统计模型 (Statistical Model)
数理统计模型用于对数据进行分析、总结和推断。它能够通过建立概率模型和统计分布,对数据的特征、关系和不确定性进行描述和推断。在数学建模比赛中,数理统计模型可以通过对给定数据集的统计分析,推断出数据的分布规律、相关性、假设检验等,为问题提供支持和解决方案。
- 聚类分析:析用于将样本进行分类处理,通常是以定量数据作为分类标准;用户可自行设置聚类数量,如果不进行设置,系统会提供默认建议;通常情况下,建议用户设置聚类数量介于3~6个之间。聚类分析可以分为以下4类。
- 主成分分析:用于对数据信息进行浓缩,比如总共有20个指标值是否可以将此20项浓缩成4个概括性指标。除此之外,主成分分析可用于权重计算和综合竞争力研究。即主成分分共有三个实际应用场景:
- 信息浓缩:将多个分析项浓缩成几个关键概括性指标;
- 权重计算:利用方差解释率值计算各概括性指标的权重;
- 综合竞争力:利用成分得分和方差解释率这两项指标,计算得到综合得分,用于综合竞争力对比 (综合得分值越高意味着竞争力越强)。
- 因子分析(探索性因子分析):用于探索分析项(定量数据)应该分成几个因子(变量),比如20个量表题项应该分成几个方面较为合适用户可自行设置因子个数,如果不设置,系统会以特征根值大于1作为判定标准设定因子个数。因子分析通常有三个步骤;第一步是判断是否适合进行因子分析;第二步是因子与题项对应关系判断;第三步是因子命名。
- 判别分析(distinguish analysis):是一种机器学习算法,其原理在于利用已知信息 (已经特征对应着类别) 进行拟合训练模型,并且验证模型的质量。如果模型质量高,此时将此模型利用到其它类别的未知类别数据上使用。用于在分类确定前提下,根据数据的特征研究数据归类问题。比如结合消费者的特征数据 (比如消费金额、消费频次、购物时长、购买产品种类等) 以预测消费者属于某种类型的顾客(款式偏好型、质量在乎型、价格敏感型等)。
- 相关分析:用于研究定量数据之间的关系情况,包括是否有关系,以及关系紧密程度等。此分析方法通常用于回归分析之前:相关分析与回归分析的逻辑关系为:先有相关关系,才有可能有回归关系。
- 回归分析:相关分析描述分析项之间是否有关系,回归分析(线性回归分析)研究影响关系情况,回归分析实质上就是研究X(自变量,通常为量数据)对Y(因变量,定量数据)的影响关系情况,有相关关系不一定有回归影响关系。
- 假设检验:方法有很多,比如单样本t检验:用于检验一个样本均值是否与已知的总体均值相等。方差分析:用于比较多个样本均值之间是否存在显著差异。通常用于分析实验结果,判断实验处理因素对结果的影响是否显著。卡方检验:用于检验观察频数与期望频数之间的差异是否显著。通常用于分析分类变量之间的关系,如性别与收入、教育程度等。
推荐模型
推荐是根据用户兴趣和行为特点,向用户推荐所需的信息或商品,帮协助用户在海量信息中快速发现真正所需的商品。
-
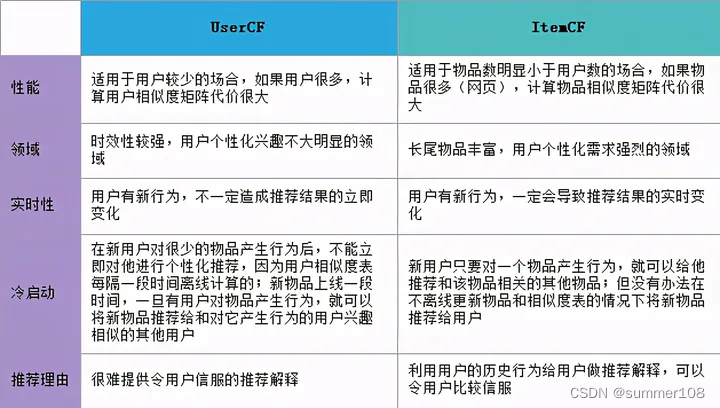
协同过滤(CF,Collaborative Filtering)
一种完全依赖用户和物品之间行为关系的推荐算法。我们从它的名字“协同过滤”中,也可以窥探到它背后的原理,就是 “协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息”。
-
矩阵分解(MF,Matrix Factorization):每个用户或者每个物品都可以用一个长度为 k 的向量表示。
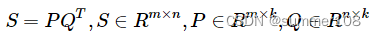
-
模型 一:NCF(Neural CF)
输入层(Input Layer)需要对用户(User)和物品(Item)进行独热编码(one-hot),矩阵 P 和 矩阵 Q 是模型中的参数。输出层(Output Layer)是 softmax 层,神经元个数是 1. 当输出 y 为 1 时,表示用户 u 和 物品 i 是相关的,也就是说,物品 i 可以推荐给用户 u;当输出为 0 时,表示用户 u 和 物品 i 是无关的,也就是说,物品 i 不建议推荐给用户 u。 -
模型二:DCF(Deep CF)
把用户和物品的隐向量直接当作神经网络中的参数去求解,而输出层根据余弦相似度的结果去判断用户 i 和物品 j 的相似度。 -
缺点:首先,每遇到一个新的业务,都需要重新搭建模型,如推导出新的参数学习算法,并在学习参数过程中调节各种参数,不能很好地复用。其次,MF 模型不能很好地利用特征工程法( feature engineering)来完成学习任务。
-
-
因子分解机(FM,Factorization Machine)
- 模型一:FM
LR - 线性组合加上交叉项 - 特征组合。
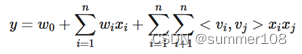
- 模型二:GBDT + FM
GBDT,全称 Gradient Boosting Decision Tree(梯度提升决策树),它是一个集成模型,使用多棵决策树,每棵树去拟合前一棵树的残差来得到很好的拟合效果。
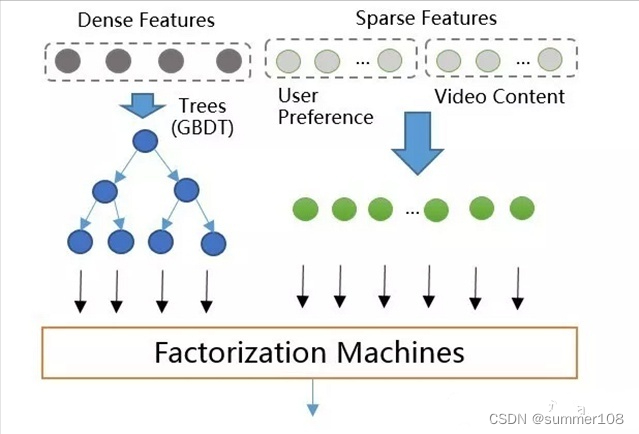
- 模型一:FM
-
Wide & Deep:
谷歌在 2016年发表了一篇论文“Wide & Deep Learning for Recommender Systems”,业务场景是 Google Play 基于用户 query,推荐合适的 item。
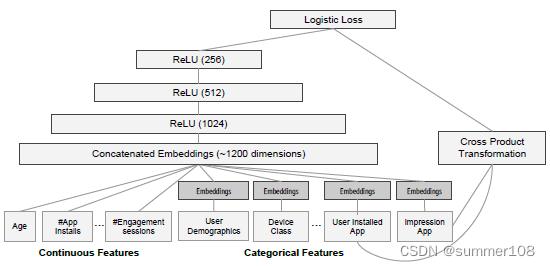
上图模型分为两部分:分别是左边的 Deep 和右边的 Wide。模型的输入数据包含连续特征(连续值),如年龄、已安装的 APP 数量、已连接的会话数等和类别特征,如用户画像、设备类型、已安装的 APP 和用户可能感兴趣的 APP。
Wide 模型中,将用户已安装的 APP 和可能感兴趣的 APP 做叉积运算,然后连接到 softmax 层。
Deep 模型中,由于输入特征维度很大,先经过嵌入层(Embedding)降维处理,然后特征聚合,经过全联接层,最后一层也是 softmax 层。
Wide 是一个 LR(Logistic Regression)模型,它是一个线性模型,利用了交叉特征(AND),显然具备较强的记忆能力(memorization)。
而 Deep 是一个 DNN 模型,它可以通过针对稀疏特征学习的低维密集嵌入更好地推广到看不见的特征组合,因此几乎不需要人工特征工程,具备较强的泛化能力(generalization)。但是当交互信息较少时,它会过拟合(overfit),学习到一些本来不存在的关联。
-
超大规模分类模型:
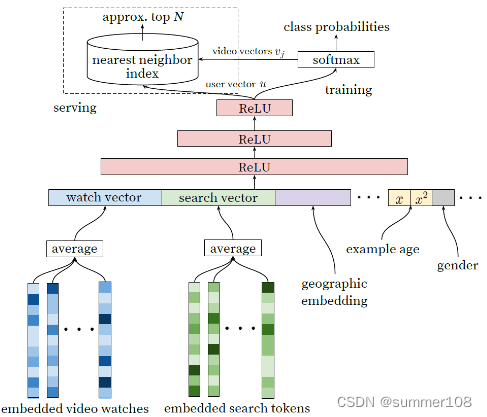
YouTube 在2016年发表的论文《Deep Neural Networks for YouTube Recommendations》中提出了基于深度学习的一个超大规模分类模型(Candidate Generation,类似 skip-gram,采用方法:hierarchical softmax 和 negative sample),它把召回阶段建模为一个分类模型,其目标是根据上下文 C,用户 U,从集合 V 中找到时刻 t 最可能被观看的视频 Wt
-
基于图的随机游走算法:
二分图模型的代表是 Personal Rank 和 Page Rank 算法,其核心思想是:建立用户和物品之间的二分图,如果样本中某个用户关联了某个物品,那么该用户点和物品点之间建立一条边;对于图中的每个点,以一定的概率 a 停留在原地,以概率 1 - a 走向与它相邻的节点,这是一个马尔可夫过程,经过多轮迭代之后,最终每个点的到达概率都会收敛到某个值。
以上内容结合网络上各位前辈总结的,后续会随着学习的深入不断补充。(下次应该把文本挖掘常用算法补进来)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!