浏览器的一些思考(12.13)
1.在没有浏览器之前是什么样子的?
在没有浏览器之前,人们访问互联网主要通过终端机或图文电视系统。
终端机是一种没有显示器、键盘和鼠标的计算机,只能通过终端模拟器来显示和操作。终端模拟器可以模拟终端机的功能,让用户能够在本地计算机上通过键盘和鼠标来访问远程主机。
在终端机上访问互联网,用户需要输入命令来操作。例如,要访问一个网站,用户需要输入网址,然后按回车键。终端机会将网址发送到远程主机,远程主机会返回网页的内容,终端机会显示网页的内容。
在终端机上访问互联网,只能看到文字,没有图形。而且,操作比较复杂,需要记忆很多命令。
图文电视系统是一种只接受数据,不发送数据的电视系统。图文电视系统可以接收远程主机发送的图文信息,并显示在电视屏幕上。
在图文电视系统上访问互联网,只能看到文字和图形,没有交互功能。而且,图文电视系统的普及率比较低。
因此,在没有浏览器之前,人们访问互联网的方式比较有限,体验也比较差。
具体的来说,在没有浏览器之前,人们访问互联网时会遇到以下问题:
- 操作复杂:在终端机上访问互联网,用户需要记忆很多命令,操作比较复杂。
- 只能看到文字:在终端机上访问互联网,只能看到文字,没有图形,体验比较差。
- 只能访问文字网站:在终端机上访问互联网,只能访问提供文字内容的网站,不能访问提供图形、视频等内容的网站。
1993年,第一个网页浏览器 Mosaic问世,彻底改变了人们访问互联网的方式。Mosaic可以显示图形和交互功能,让访问互联网变得更加简单和方便。浏览器的出现,也标志着互联网进入了新的时代。
以下是一些在没有浏览器之前访问互联网的具体例子:
- 在终端机上访问新闻网站:用户需要输入网址,然后按回车键。终端机会将网址发送到新闻网站的服务器,服务器会返回网页的内容,终端机会显示网页的内容。网页的内容只能是文字,没有图形。
- 在终端机上访问搜索引擎:用户需要输入搜索关键词,然后按回车键。终端机会将搜索关键词发送到搜索引擎的服务器,服务器会返回搜索结果的网页,终端机会显示网页的内容。网页的内容只能是文字,没有图形。
- 在图文电视系统上访问天气预报:用户需要选择天气预报的频道,然后等待图文电视系统显示天气预报的内容。天气预报的内容只能是文字和图形,没有交互功能。
2.浏览器的发展
维基百科:
https://zh.wikipedia.org/wiki/%E6%B5%8F%E8%A7%88%E5%99%A8%E5%A4%A7%E6%88%98
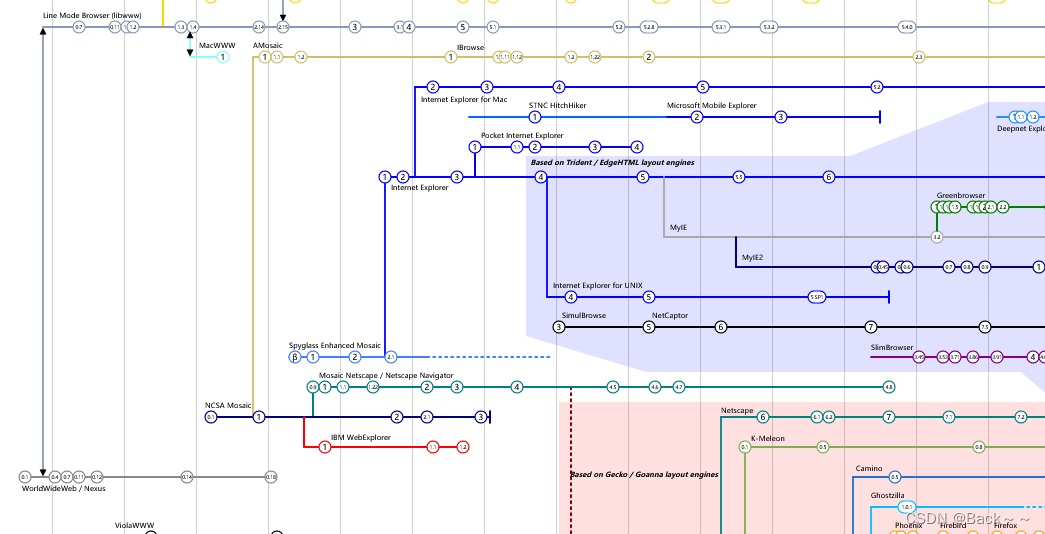
浏览器的发展可以分为以下几个阶段:
https://upload.wikimedia.org/wikipedia/commons/7/74/Timeline_of_web_browsers.svg
{kind=link}
萌芽期(1991-1994)
1991年,英国计算机工程师蒂姆·伯纳斯·李(Tim Berners-Lee)在欧洲核子研究组织(CERN)工作时,开发出首个Web服务器与图形化网页浏览器,命名为WorldWideWeb。WorldWideWeb只能在UNIX操作系统上运行,而且功能比较简单。
1992年,Erwise发布,被称为世界上第一个图形化网页浏览器。Erwise可以显示图片,但功能仍然比较简单。
1993年,Mosaic发布,是第一个获得普遍使用和能够显示图片的网页浏览器。Mosaic的出现是后期互联网热潮的火种之一。
第一次浏览器大战(1995-2002)
1995年,微软公司发布了Internet Explorer 1.0,作为Windows 95的插件形式出现。Internet Explorer的出现,标志着浏览器的商业化时代的到来。
1995年,网景通信公司(Netscape)发布了Netscape Navigator 1.0,与Internet Explorer形成了竞争。Netscape Navigator的优势在于功能强大、支持多种操作系统。
在接下来的几年里,Internet Explorer和Netscape Navigator的市场份额一直在激烈竞争。最终,Internet Explorer凭借微软公司的强大优势,占据了浏览器市场的主导地位。
第二次浏览器大战(2003-2012)
2003年,谷歌公司发布了Chrome浏览器,以其快速、安全、易用的特点迅速崛起。
2004年,苹果公司发布了Safari浏览器,专为Mac OS X和iOS操作系统设计。
在接下来的几年里,Chrome、Safari等浏览器的市场份额不断增长,挑战了Internet Explorer的霸主地位。
第三次浏览器大战(2013-至今)
2013年,Microsoft发布了Edge浏览器,取代了Internet Explorer。Edge浏览器采用了新的HTML5架构,支持WebAssembly等新技术。
2016年,Firefox浏览器发布了Quantum版本,采用了新的Gecko内核,性能大幅提升。
在接下来的几年里,Chrome、Firefox、Edge等浏览器的市场份额继续增长,互联网浏览器市场竞争更加激烈。
3.浏览器的工作原理是什么?
下面这偏文章 讲得详细
https://zhuanlan.zhihu.com/p/47407398
浏览器的工作原理可以分为以下几个步骤:
搜索引擎是如何检索到网页的? - YouTube精选字幕的回答 - 知乎
https://www.zhihu.com/question/27206471/answer/2667429815
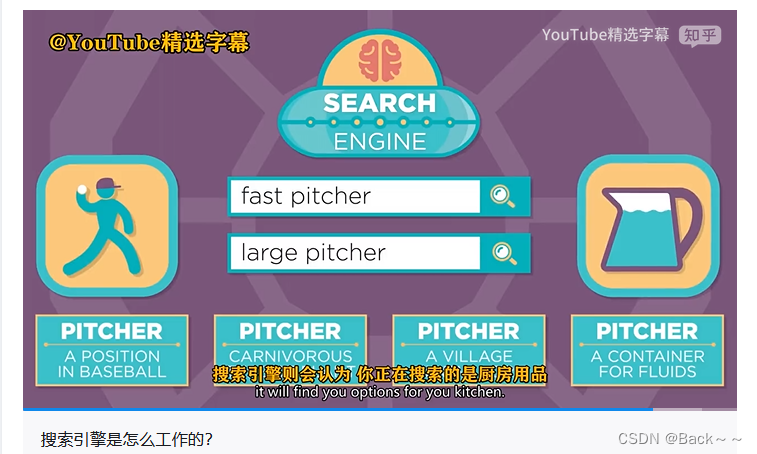
- 解析网址:浏览器首先会解析用户输入的网址,将网址转换为服务器的 IP 地址和端口号。
- 建立连接:浏览器会通过 TCP 协议建立与服务器的连接。
- 发送请求:浏览器会向服务器发送请求,请求服务器返回网页的内容。
- 接收响应:服务器会返回网页的内容,浏览器会接收网页的内容。
- 解析网页:浏览器会解析网页的内容,将网页的内容转换为图形、文本、视频等形式。
- 显示网页:浏览器会将解析后的网页内容显示在用户的屏幕上。
具体来说,浏览器的工作原理如下:
- 解析网址
当用户在浏览器中输入一个网址时,浏览器会首先解析网址。网址的格式为:
协议://主机名[:端口号]/路径
例如,网址 “https://www.baidu.com” 可以解析为:
协议:https
主机名:www.baidu.com
端口号:443
路径:/
浏览器会根据协议选择合适的网络协议来建立与服务器的连接。例如,对于 HTTPS 协议,浏览器会使用 TLS 协议来建立加密连接。
- 建立连接
浏览器会通过 TCP 协议建立与服务器的连接。TCP 协议是一种可靠的连接协议,可以保证数据的传输完整性和顺序性。
- 发送请求
浏览器会向服务器发送请求,请求服务器返回网页的内容。请求的内容包括:
- 请求方法:GET 或 POST
- 请求头:包含请求的相关信息,例如用户代理、浏览器版本等
- 请求体:包含请求的数据,例如搜索关键词
- 接收响应
服务器会返回网页的内容,浏览器会接收网页的内容。网页的内容通常是一段 HTML 代码,浏览器会解析 HTML 代码,将网页的内容转换为图形、文本、视频等形式。
- 解析网页
HTML 代码是网页的结构,它定义了网页的布局、元素和属性。浏览器会使用 HTML 解析器来解析 HTML 代码。
- 显示网页
浏览器会将解析后的网页内容显示在用户的屏幕上。浏览器使用渲染引擎来显示网页内容。
除了上述基本的工作原理之外,浏览器还提供了一些其他功能,例如:
- 安全功能:浏览器可以使用 SSL 协议来加密用户的通信,保护用户的隐私。
- 扩展功能:浏览器可以通过扩展来增加新的功能,例如广告拦截、屏幕截图等。
浏览器的工作原理比较复杂,但总体来说,浏览器的工作原理可以分为以上几个步骤。


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!