vivado 约束条件效率
约束条件效率
审查约束覆盖范围编写时间约束时,重要的是保持约束的简单性并指定它们仅在相关网表对象上。低效的约束导致更大的运行时间和更大的内存消耗。低效的约束也可能导致设计受到不适当的约束,因为定时异常可能会意外地覆盖比预期更多的路径,并与其他路径发生冲突约束。当提供给时间约束的对象数量很小时,时间约束是有效的以尽可能准确和安全地覆盖期望的定时路径。大多数时候由于对象列表通常是由一些引脚或单元构建的,因此无法获得效率名称模式。但是,当为计时异常构建对象列表。Vivado提供了几种获取时间异常反馈的方法:
?方法检查XDCB-1(report_methodology)报告了时间限制引用大型对象集合(超过1000个)。
?报告异常命令(Report_exceptions)提供覆盖范围和冲突关于已经定义的定时异常的信息。
AMD建议您仔细分析以下报告:
?report_exceptions-scope_override
此报告提供了顶级时序约束的作用域时序约束的列表部分或完全覆盖。但是,它不会报告由覆盖的作用域约束另一个作用域约束(来自相同作用域或不同作用域)。例如,这个选项可用于验证IP约束是否未被某些用户的顶级覆盖约束。
?report_exceptions–覆盖范围
此报告提供每个定时异常的逻辑路径覆盖范围。对象的数量将传递给计时异常的值与起点和终点的数量进行比较有效地合作
?report_exceptions–忽略
此报告提供了被其他时间约束覆盖的时间约束的列表(用于例如由set_clock_group覆盖的set_false_path)。您应该查看重写约束以确保正确性或删除无用的约束。
?report_exceptions–ignored_object
此报告提供了由于以下原因而被忽略的起点和终点的列表:,从这些起点或到这些终点的不存在的路径。改进约束运行时
优化Pin查询
因为设计中的引脚比单元多好几倍,所以使用get_pins而不是getcells可能会对运行时产生重大影响。运行时降级可能是处理XDC约束时(例如,open_checkpoint运行时)或执行Tcl脚本。AMD建议利用引脚和单元对象之间的关系以改进大量pin查询的运行时间。它不是根据设计中所有引脚的名称来查找引脚列表,而是更多高效地首先找到所需引脚的单元格,然后通过过滤由第一查询返回的单元格的所需引脚,如下所述。
替换all_registers查询
以下是一些额外的查询建议:
?尽可能避免使用all_registers进行查询,因为它们往往会创建大量的对象。此类查询应替换为具有适当名称模式的单元格/引脚查询。
?当必须使用all_registers并且查询正在从时钟域,all_registers-clock有时可以具有与直接使用相同的覆盖范围时钟对象。例如,下面的两个命令在覆盖范围方面是等效的。然而使用getclocks的第二种形式要高效得多,因为多循环路径约束引用单个时钟对象,而不是可能的数十万个连续对象元素。
原件:
优化运行时间的排序约束
在内存中加载正时约束时,正时引擎会验证每个新约束并打印消息以标记潜在问题。某些时间限制部分使无效时序数据库(也称为时序图)和一些其他时序约束要求正确应用最新的时序数据库。一旦定时数据库过时,需要后续的定时更新,例如,更新自动推导时钟或禁用设计中的某些定时路径。查询时钟的XDC命令或遍历设计以查询网表对象需要最新的定时数据库。影响定时数据库状态的交错约束和命令可以是运行时由于定时信息被多次无效和更新,因此是密集的。对于运行时优化,AMD建议您订购时间限制和查询小心下表列出了XDC约束
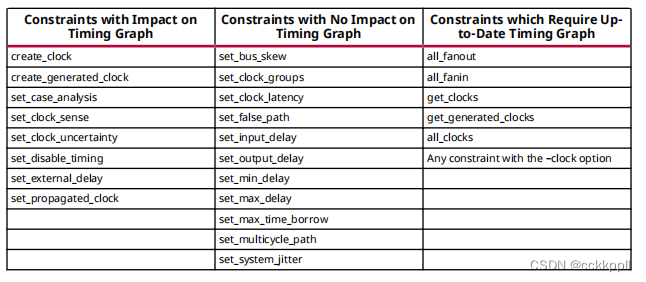
运行时最密集的组合之一是set_disable_timing与all_fanout或all_fanin。应避免这种组合。例如:
set_disable_timing–from<pin>-to[all_fanout…]set_disable _timing-from[all_fanin…]-到<pin>
基于上表,运行时优化的最佳约束顺序为:
1.XDC约束set_disable_timing、set_case_analysis和set_external_delay。
2.对时序图有影响的约束。
3.不需要时序图更新的约束。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!