目标检测-One Stage-RetinaNet
前言
根据前文目标检测-One Stage-YOLOv2可以看出YOLOv2的速度和精度都有相当程度的提升,但是One Stage目标检测模型仍存在一个很大的问题:
- 前景(positive)和背景(negatives)类别的不平衡
ps:假设我们有一个医学图像分类任务,要识别是否患有一种罕见的疾病。在这个场景中,正类别是患有疾病的图像,负类别是健康的图像。由于罕见疾病的患者数量相对较少,数据集中正类别的样本数量远远少于负类别。这就是前景和背景的类别不平衡问题。
RetinaNet 针对上述缺点做了改进
提示:以下是本篇文章正文内容,下面内容可供参考
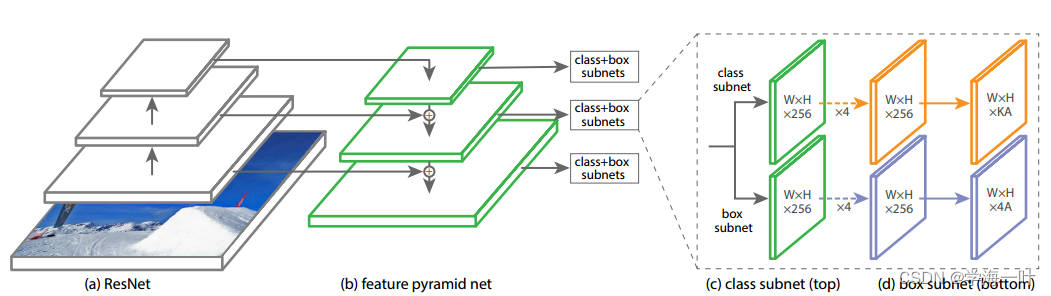
一、RetinaNet的网络结构和流程
- 将影像输入卷积网络(ResNet)+特征金字塔网络(FPN)得到多尺度特征图(P3-P7, 3 2 2 32^2 322 to 51 2 2 512^2 5122 )
ps:和SSD的多尺度特征图相比加入了自顶而下的特征融合机制
- 引入anchor机制,每个特征点对应9个anchor(3种横纵比×3种尺寸)
- 将上一步得到的anchor输入不同的分类和边框回归器
- 使用非极大值抑制NMS去除冗余窗口
二、RetinaNet的创新点
- 最核心的就是提出Focal Loss损失函数来解决前景和背景类别的不平衡问题
在One Stage目标检测网络中损失函数中一般分为两部分(分类损失+回归损失),正负样本都会计算分类损失,然后仅对正样本进行回归损失的计算。
Balanced Cross Entropy
正负样本都计算分类损失,会造成的问题是,负样本是远远多于正样本的,为了解决这种类别不平衡问题,可以采用平衡交叉熵损失(Balanced Cross Entropy),即在交叉熵损失的基础上,引入一个权重因子 α ,当类标签是 1 时,权重因子是 α ,当类标签是 -1 时,权重因子是 1 ? α 。
B C E ( p , y ) = ? α t ? l o g ( p t ? ) BCE(p,y)=?α_t?log(p_t?) BCE(p,y)=?αt??log(pt??)
其中pt = p if y=1 else pt = 1-p,p范围在 [0, 1] ,
a
1
?
a
=
n
m
\frac{a}{1-a}=\frac{n}{m}
1?aa?=mn? ,m为正样本数,n为负样本数
Balanced Cross Entropy 解决了正负样本的比例失衡问题(positive/negative examples),但是这种方法仅仅解决了正负样本之间的平衡问题,并没有区分简单还是难分样本(easy/hard examples)。当容易区分的负样本(easy negatives)的泛滥时,整个训练过程都是围绕容易区分的样本进行(小损失积少成多超过大损失),而被忽略的难区分的样本才是训练的重点。
Focal Loss
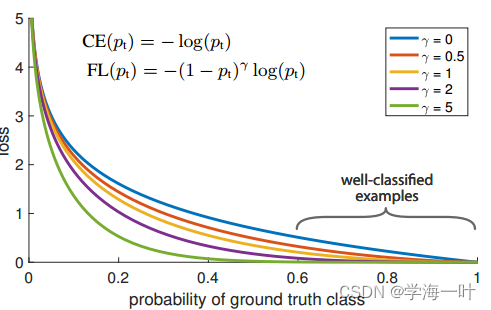
因此,Focal Loss将权重因子 α修改为调制因子 ( 1 ? p t ? ) γ (1?p_t?)^γ (1?pt??)γ ,整个公式如下
F L ( p t ? ) = ? ( 1 ? p t ? ) γ l o g ( p t ? ) FL(p_t?)=?(1?p_t?)^γlog(p_t?) FL(pt??)=?(1?pt??)γlog(pt??)
γ \gamma γ 也是一个参数,范围在 [0, 5], p t p_t pt?趋向于1时(概率大),说明该样本比较容易区分,此时,调制因子趋向于 0 的样本的loss贡献值会很小,反之则知难区分的样本loss贡献值占比大,当 γ = 0 \gamma = 0 γ=0 的时候,FL 就是原来的交叉熵损失 CE,随着 γ \gamma γ 的增大,调整速率也在变化,实验表明,在 γ = 2 \gamma = 2 γ=2 时,效果最佳
总结
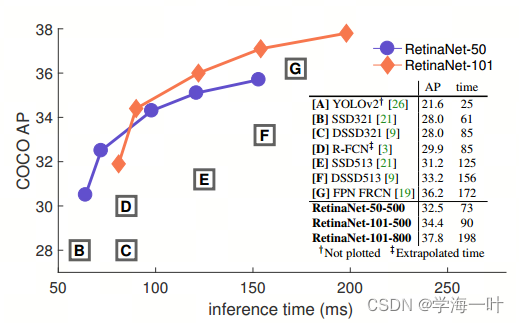
在coco test-dev数据集上,RetinaNet达到当时的SOTA(最高39.1mAP,图中未给出)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!