yarn历史日志_配置文件
2023-12-13 09:21:44
| yarn历史日志 |
| yarn配置文件 |
| yarn执行任务 |
1.3. YARN的历史日志
1.3.1. 历史日志概述
我们在YARN运行MapReduce的程序的时候,任务会被分发到不同的节点,在不同的Container内去执行。如果一个程序执行结束后,我们想去查看这个程序的运行状态呢?每一个MapTask的执行细节?每一个ReduceTask的执行细节?这个时候我们是查看不到的,因此我们需要开启记录历史日志的服务。 ? 历史日志服务开启之后,Container在运行任务的过程中,会将日志记录下来,保存到当前的节点。例如: 在qianfeng02节点上开启了一个Container去执行MapTask,那么此时就会在qianfeng02的$HADOOP_HOME/logs/userlogs中记录下来日志。我们可以到不同的节点上去查看日志。虽然这样可以查看,但是很不方便!因此,我们一般还会开启另外的一个服务: **日志聚合**。顾名思义,就是将不同节点的日志聚合到一起保存起来。
1.3.2. mr-historyserver
顾名思义,就是去记录MapReduce的历史日志的。接下来我们从配置开始、到日志聚合、运行任务去讲解。
1.3.2.1. 配置文件
-
mapred-site.xml
[root@qianfeng01 hadoop-3.3.1]# vi /usr/local/hadoop-3.3.1/etc/hadoop/mapred-site.xml
<!-- 添加如下配置 -->
?
<!-- 历史任务的内部通讯地址 -->
<property>
? ?<name>MapReduce.jobhistory.address</name>
? ?<value>qianfeng01:10020</value>
</property>
?
<!--历史任务的外部监听页面-->
<property>
? ?<name>MapReduce.jobhistory.webapp.address</name>
? ?<value>qianfeng01:19888</value>
</property>
?
<property>
?<name>yarn.app.mapreduce.am.env</name>
?<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
?<name>mapreduce.map.env</name>
?<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>
<property>
?<name>mapreduce.reduce.env</name>
?<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.3.1</value>
</property>-
yarn-site.xml
[root@qianfeng01 hadoop-3.3.1]# vi /usr/local/hadoop-3.3.1/etc/hadoop/yarn-site.xml
<!-- 添加如下配置 -->
?
<!-- 是否需要开启日志聚合 -->
<!-- 开启日志聚合后,将会将各个Container的日志保存在yarn.nodemanager.remote-app-log-dir的位置 -->
<!-- 默认保存在/tmp/logs -->
<property>
? ?<name>yarn.log-aggregation-enable</name>
? ?<value>true</value>
</property>
?
<!-- 历史日志在HDFS保存的时间,单位是秒 -->
<!-- 默认的是-1,表示永久保存 -->
<property>
? ?<name>yarn.log-aggregation.retain-seconds</name>
? ?<value>604800</value>
</property>
?
<property>
? ?<name>yarn.log.server.url</name>
? ?<value>http://qianfeng01:19888/jobhistory/logs</value>
</property>
1.3.2.2. 分发配置
[root@qianfeng01 hadoop-3.3.1]# scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* qianfeng02:/usr/local/hadoop-3.3.1/etc/hadoop/
[root@qianfeng01 hadoop-3.3.1]# scp -r /usr/local/hadoop-3.3.1/etc/hadoop/* qianfeng03:/usr/local/hadoop-3.3.1/etc/hadoop/1.3.2.3. 开启历史服务
# 重启YARN集群
[root@qianfeng01 ~]# stop-yarn.sh
[root@qianfeng01 ~]# start-yarn.sh
# 打开历史服务--->在规划的historyserver服务器上启动
[root@qianfeng01 ~]# mapred --daemon start historyserver
?
# 开启之后,通过jps可以查看到 JobHistoryServer 进程,表示开启成功1.3.2.4. 执行任务
[root@qianfeng01 ~]# yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /input /output/00
我们以官方案例wordcount为例,现在在运行完这个任务后,就会在WebUI上看到这个任务。我们可以点击任务的ID进入到任务的详情页,此时可以查看日志。
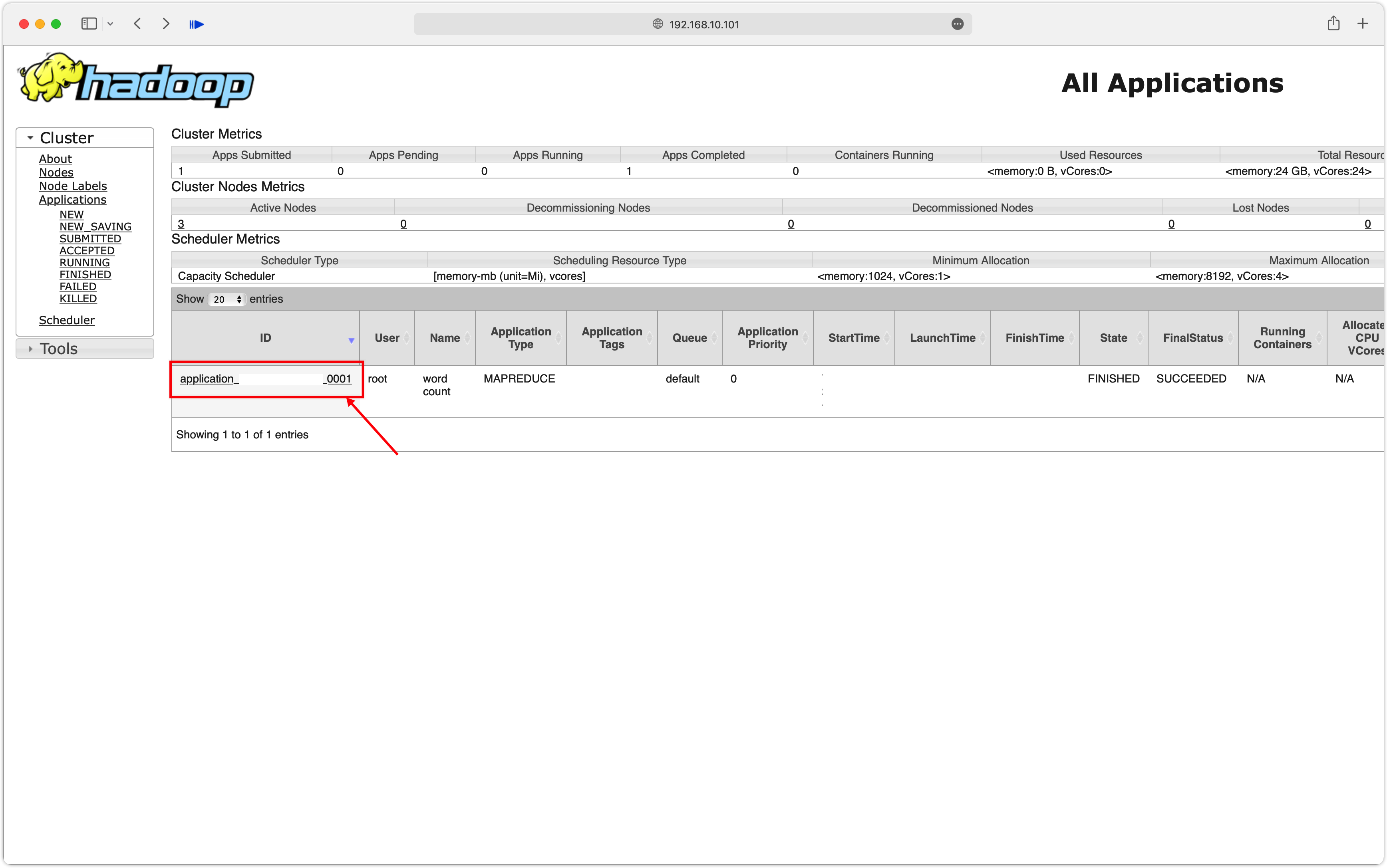
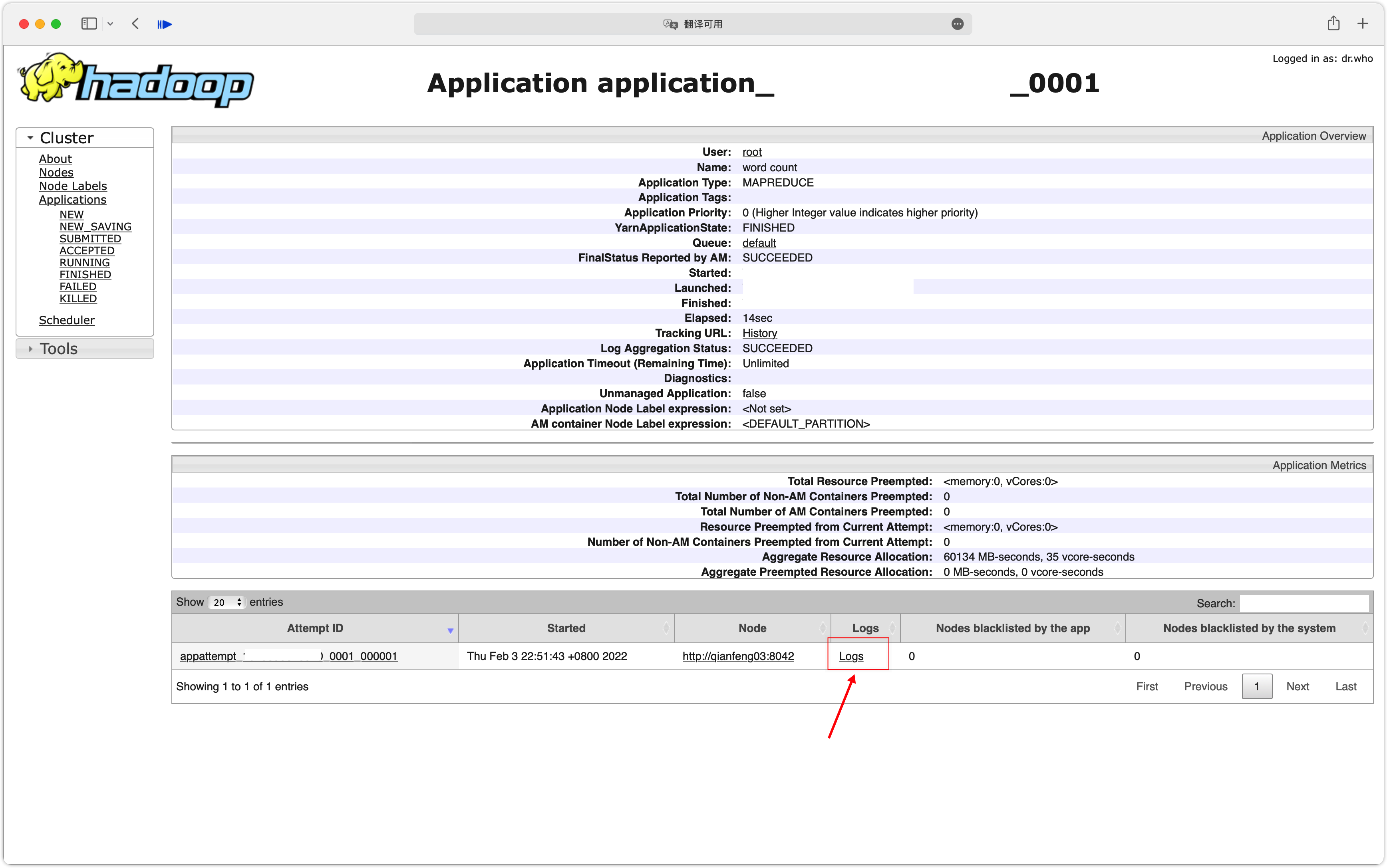
也可以在http://192.168.10.101:19888查看每一个MapTask、ReduceTask的日志


文章来源:https://blog.csdn.net/HYSliuliuliu/article/details/134942099
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!