【Hadoop_03】HDFS概述与Shell操作
1、集群配置
(1)集群启动/停止方式总结
1)各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
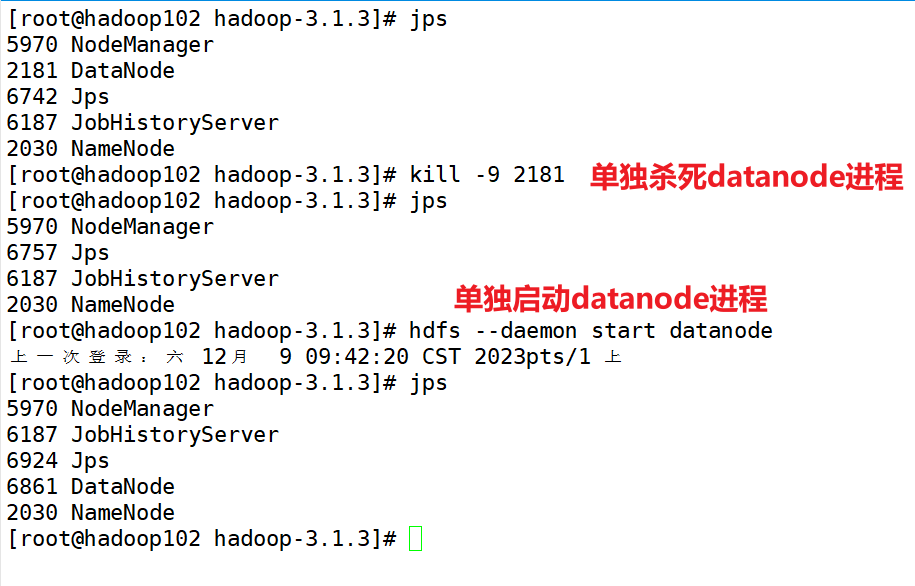
一般都是按照集群来启动,不然如果有100+台服务器的话,就无法启动了
(2)编写Hadoop集群常用脚本
在写脚本的时候,能写绝对路径就不要写相对路径。
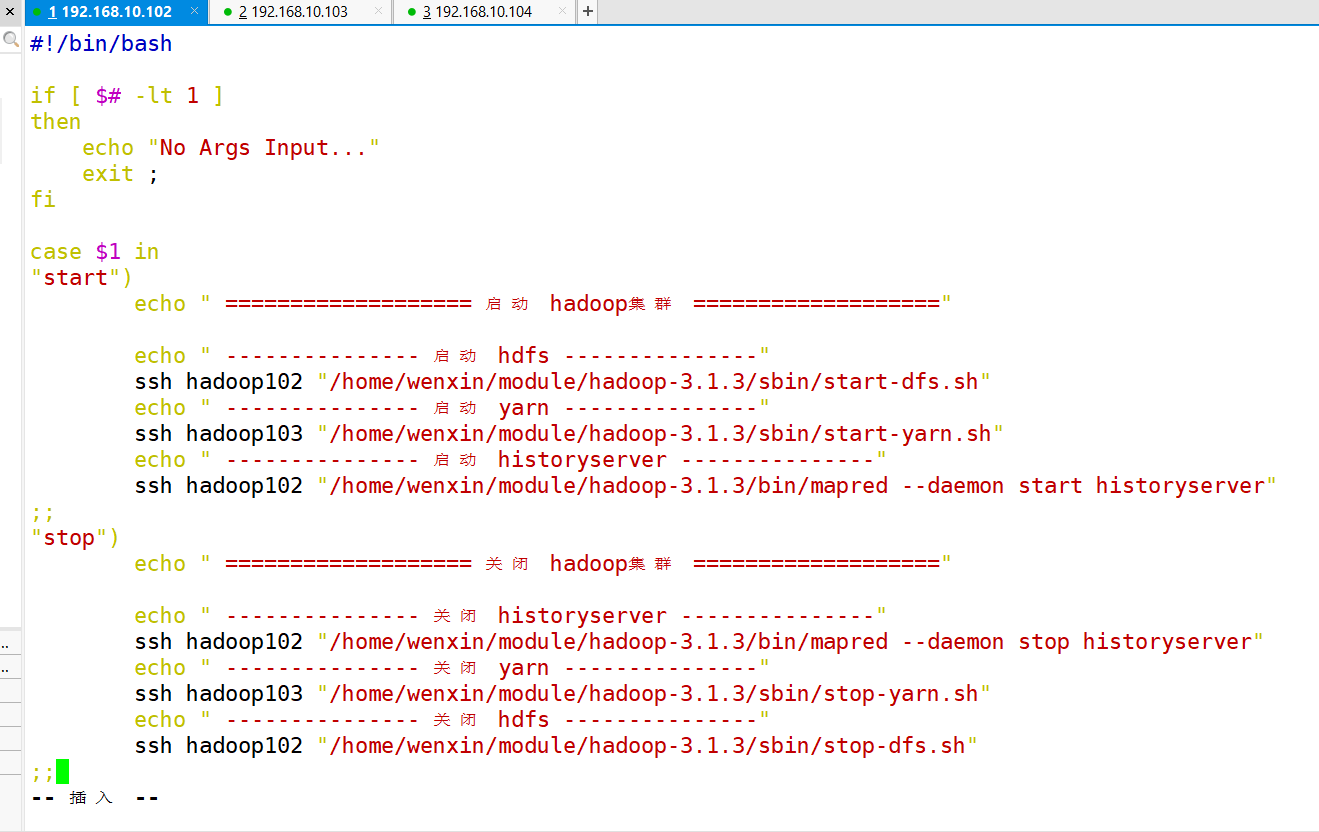
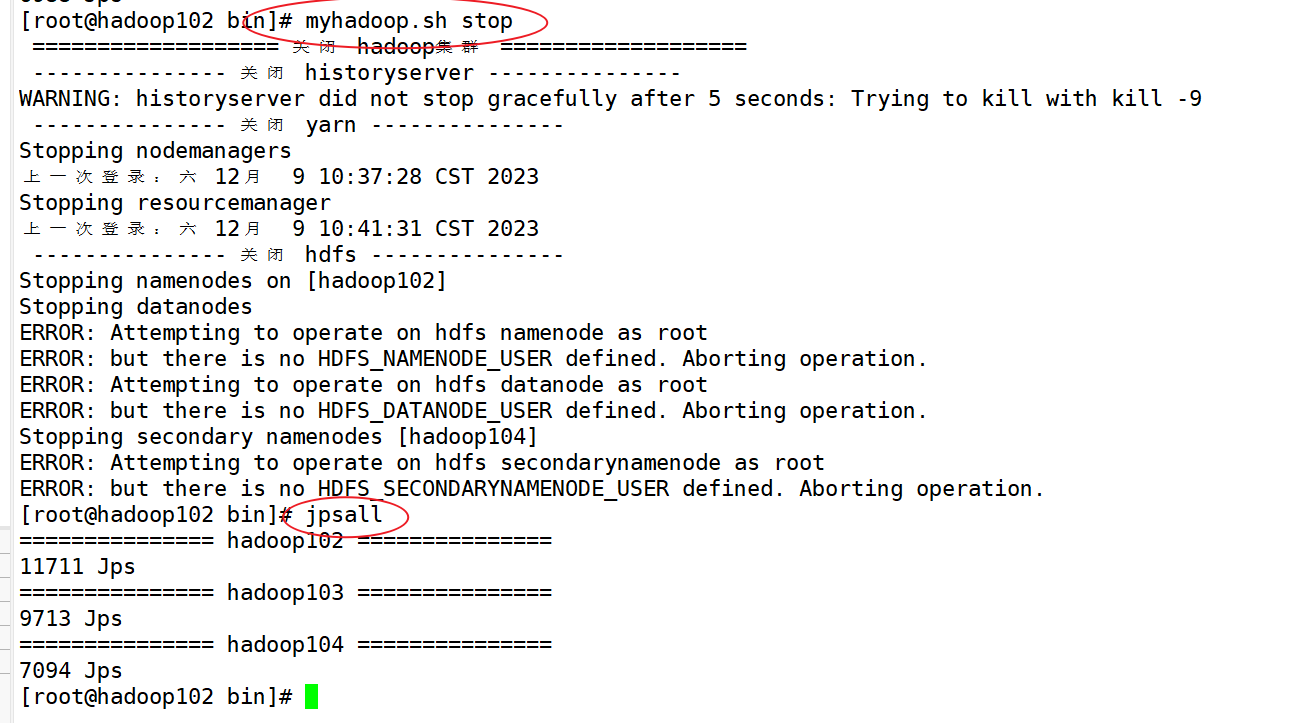
1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
[root@hadoop102 ~]$ cd /home/wenxin/bin
[root@hadoop102 bin]$ vim myhadoop.sh
- 输入如下内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/home/wenxin/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/home/wenxin/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/home/wenxin/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/home/wenxin/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/home/wenxin/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/home/wenxin/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
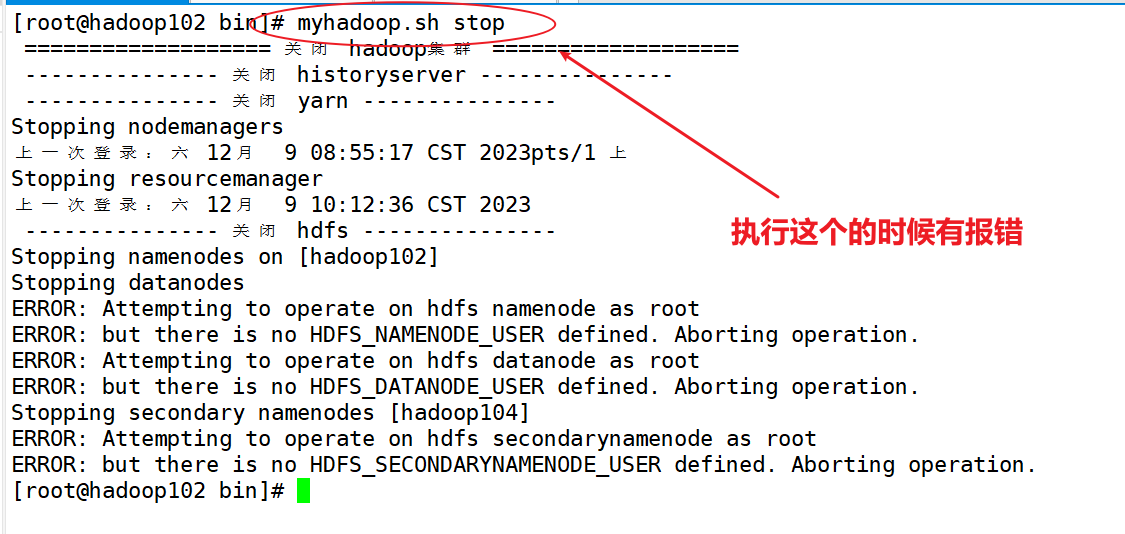
目前还没找到解决方法。
2)查看三台服务器Java进程脚本:jpsall
[root@hadoop102 bin]$ vim jpsall
- 输入如下内容
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
- 保存后退出,然后赋予脚本执行权限
[root@hadoop102 bin]$ chmod +x jpsall
3)分发/bin目录,保证自定义脚本在三台机器上都可以使用
[root@hadoop102 ~]$ xsync /bin
(3)常考面试题
【1】常用端口号
-
hadoop3.x
HDFP NameNode 内部通讯端口:8020/9000/9820
HDFS NameNode 对用户的查询端口:9870
Yarn查看任务运行情况的:8088
历史服务器:19888 -
hadoop2.x
HDFS NameNode 内部通讯端口:8020/9000
HDFS NameNode 对用户的查询端口:50070
Yarn查看任务运行情况的:8088
历史服务器19888
【2】常用配置-文件
-
hadoop3.x :
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml workers -
hadoop2.x :
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml slaves
2、HDFS概述
(1)HDFS产出背景及定义
1)HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
分布式指的是多台服务器解决同一件事情。
2)HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
已经写入的就不适合修改了
(2)HDFS优缺点
优点:
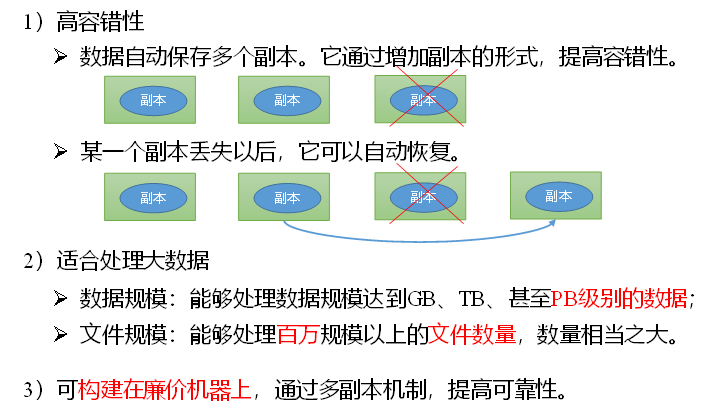
缺点:

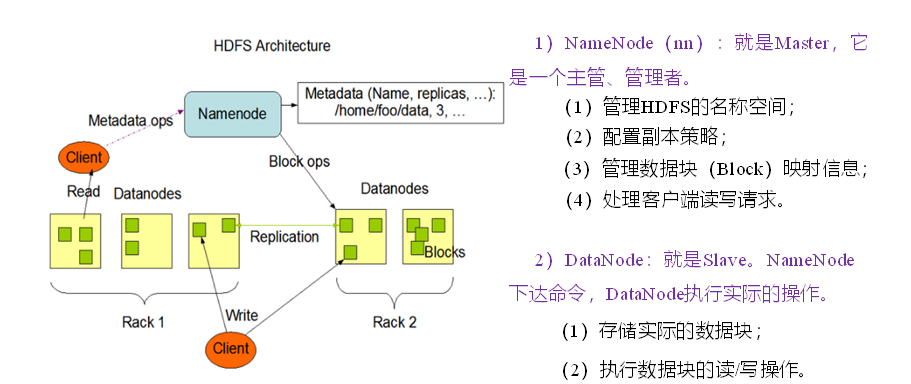
(3)HDFS的组成架构

(4)HDFS文件块大小(面试重点)
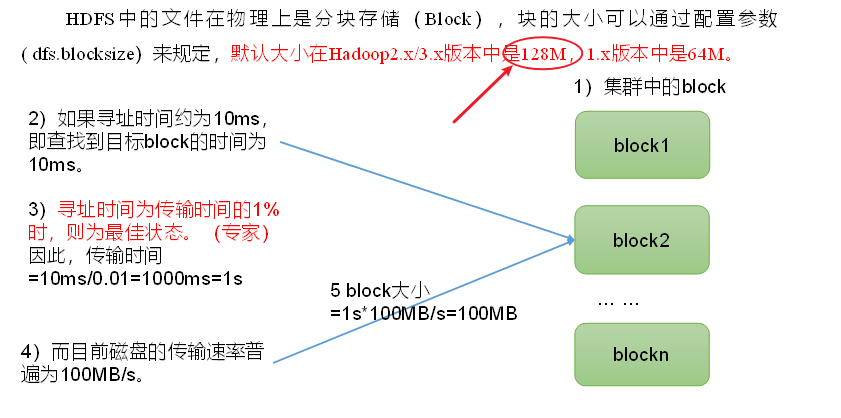

块太大不利于后期的并发运算,而且处理起来较慢。
3、HDFS的Shell操作
hadoop fs 具体命令 或者R hdfs dfs 具体命令
两个是完全相同的。
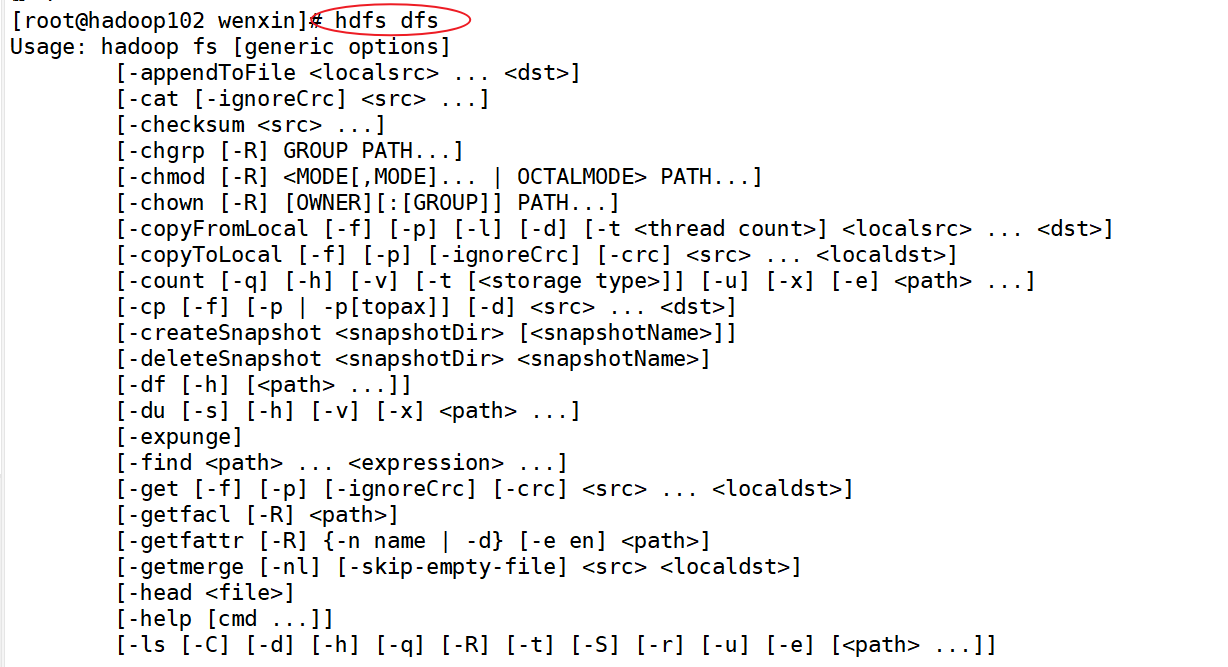
命令大全:
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
(1)准备工作
- 启动dfs服务
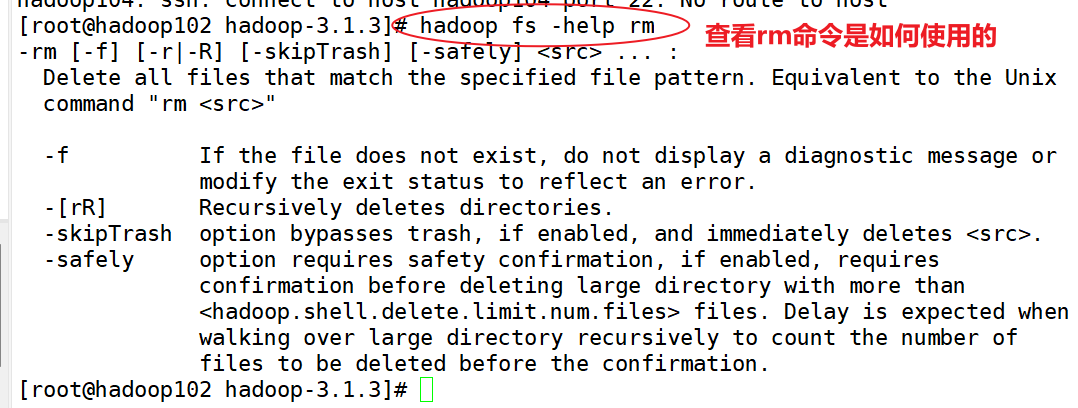
-help:输出这个命令参数
hadoop fs -help rm
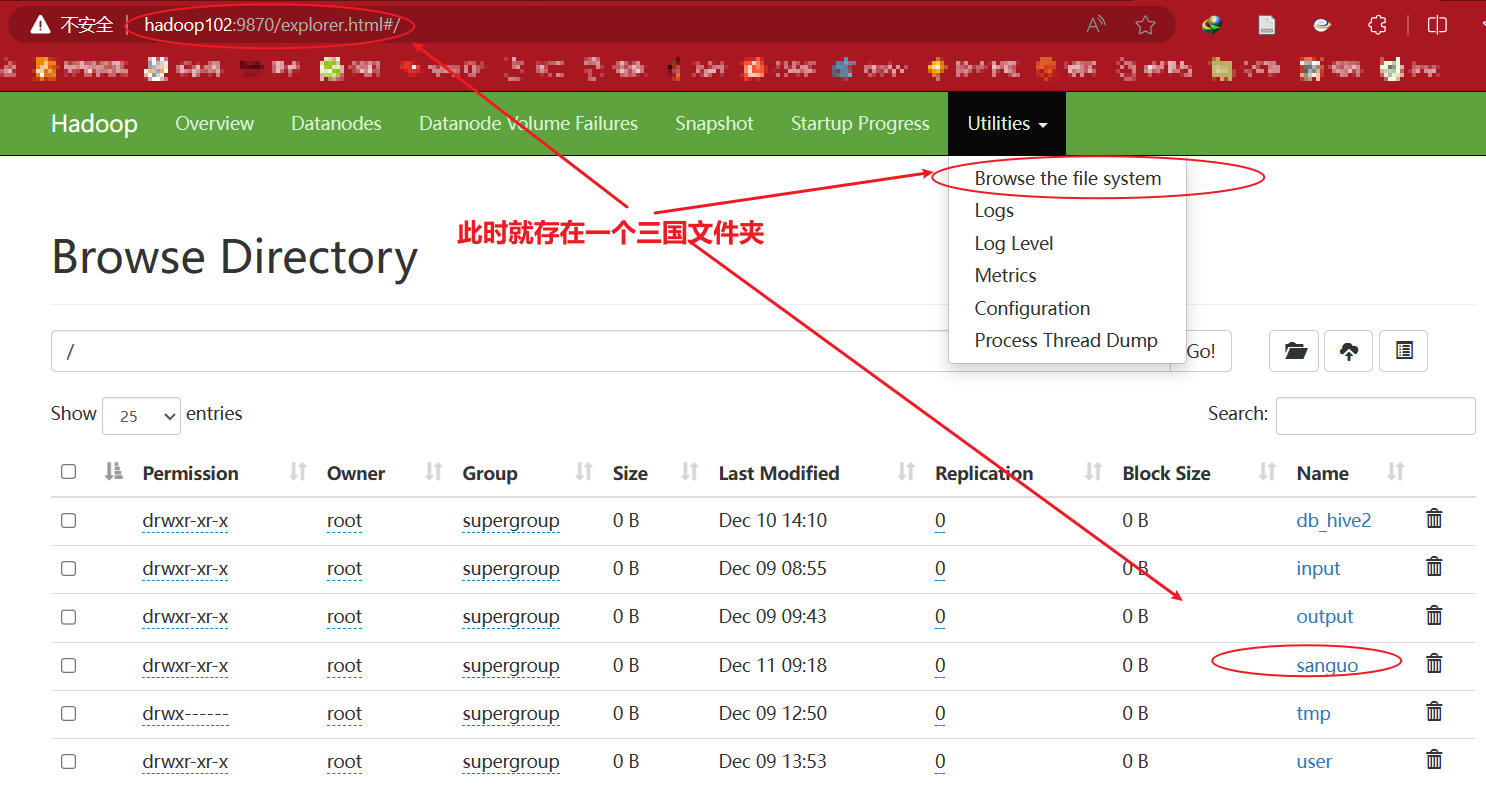
创建/sanguo文件夹
hadoop fs -mkdir /sanguo
在网址上输入:hadoop102:9870
(2)上传命令
1)-moveFromLocal:从本地剪切粘贴到HDFS
[root@hadoop102 hadoop-3.1.3]# hadoop fs -moveFromLocal ./shuguo.txt /sanguo

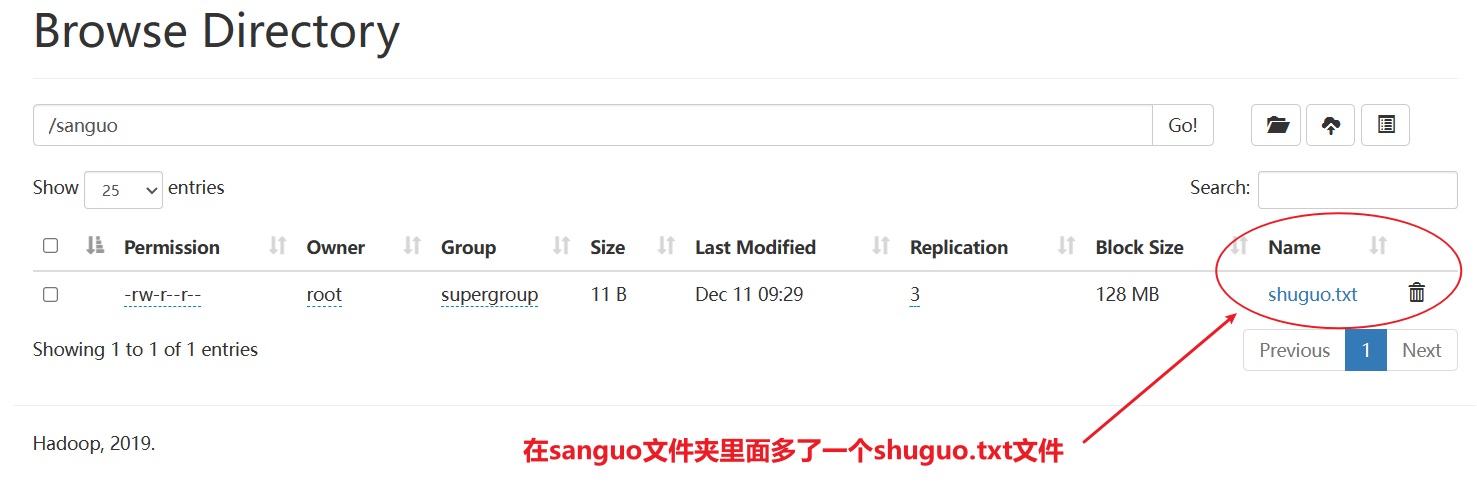
2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@hadoop102 hadoop-3.1.3]# hadoop fs -copyFromLocal weiguo.txt /sanguo

3)-put:等同于copyFromLocal,生产环境更习惯用put
[root@hadoop102 hadoop-3.1.3]# hadoop fs -put wuguo.txt /sanguo
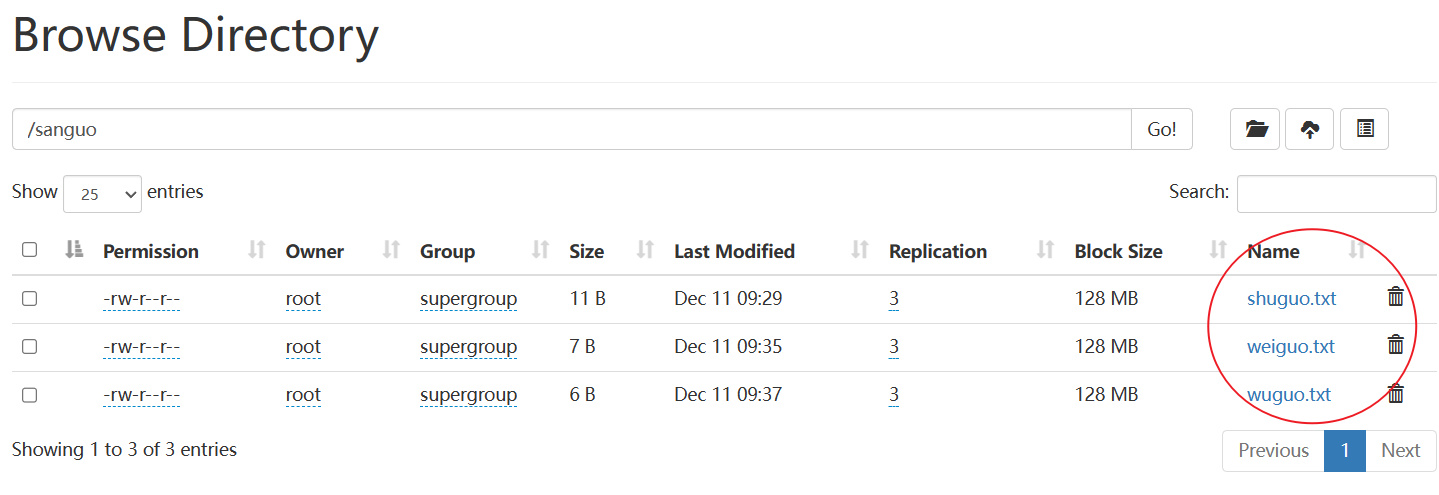
4)-appendToFile:追加一个文件到已经存在的文件末尾【HDFS只允许在文件的末尾进行追加,不允许修改】
[root@hadoop102 hadoop-3.1.3]# hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
将liubei.txt文件追加到sanguo文件夹下的shuguo.txt文件的末尾
(3)下载命令
1)-copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo.txt ./
将hdfs中的sanguo文件夹下的shuguo.txt文件拷贝到本地的当前路径下
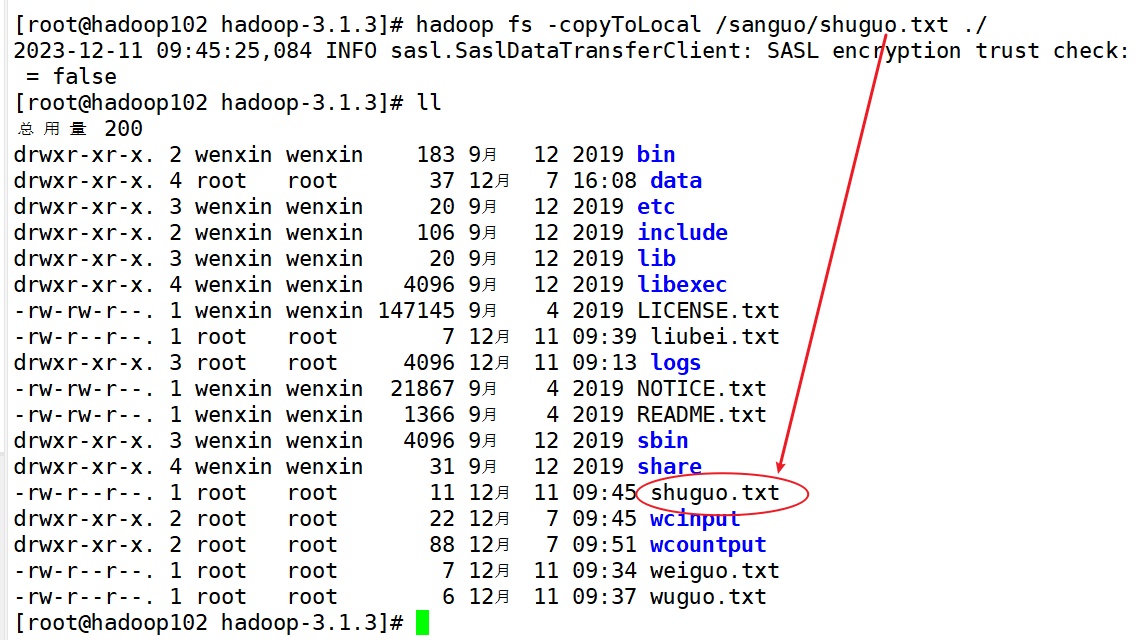
2)-get:等同于copyToLocal,生产环境更习惯用get
hadoop fs -get /sanguo/shuguo.txt ./
(4)HDFS直接操作命令
1)-ls: 显示目录信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo

2)-cat:显示文件内容
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt

3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -chown root:root /sanguo/shuguo.txt
4)-mkdir:创建路径
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo

6)-mv:在HDFS目录中移动文件
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo
7)-tail:显示一个文件的末尾1kb的数据
因为在生产环境当中,往往最末尾的文件是最新的文件。文件都是从最末尾追加的。
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
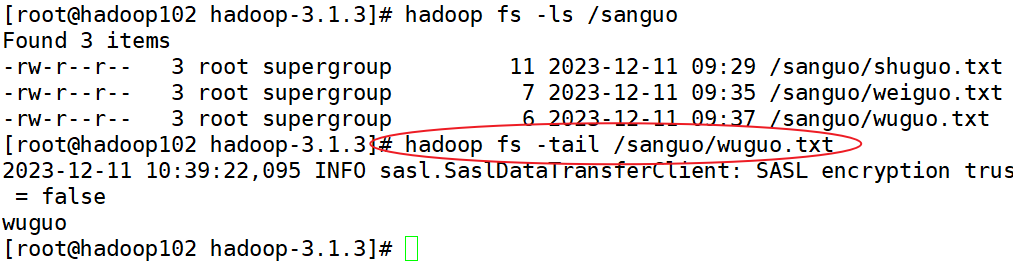
8)-rm:删除文件或文件夹
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo

[root@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo

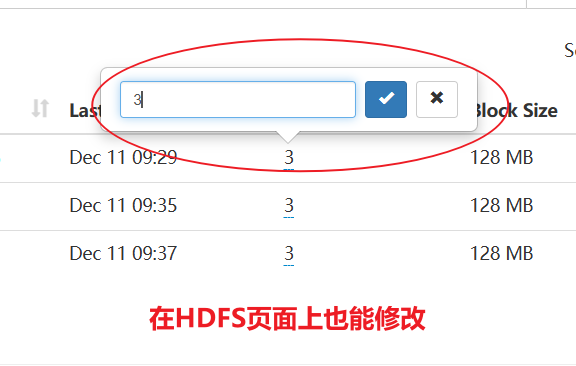
11)-setrep:设置HDFS中文件的副本数量
[root@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt

这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!