【BERT】深入BERT模型2——模型中的重点内容,两个任务
前言
BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年
近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BERT模型的变体,而且在模型中增加了BERT预训练模型之后,许多NLP任务的模型性能都得到了很大程度的提升,这也说明了BERT模型的有效性。
由于BERT模型内容较多,想要深入理解该模型并不容易,所以我分了大概三篇博客来介绍BERT模型,第一篇主要介绍BERT模型的整体架构,对模型有一个整体的认识和了解;第二篇(也就是本篇博客)详细介绍BERT模型中的重点内容,包括它所提出的两个任务;第三篇从代码的角度来理解BERT模型。
目前我只完成了前两篇论文,地址如下,之后完成第三篇会进行更新。
第一篇:【BERT】深入理解BERT模型1——模型整体架构介绍
第二篇:【BERT】深入BERT模型2——模型中的重点内容,两个任务
第三篇:
模型重点内容介绍
首先先解释以下上一篇博客中经常提到的模型的单向和双向:
????????单向:是指生成句子中某个单词的编码表示时,只结合句子中该单词位置之前的语境,而不考虑之后的语境;双向:是指生成句子中某个单词的编码表示时,同时考虑句子中该单词位置之前和之后的语境。
????????由此可知,Transformer的编码器(主要是多头注意力机制)天然就是双向的,因为它的输入是完整的句子,也就是说,指定某个单词,BERT已经读入了它两个方向上的所有单词。
7、BERT的标准配置有两种:BERT-base和BERT-large。
BERT-base:包含12个编码器层。每个编码器使用12个注意头,编码其中的全连接网络包含768个隐藏单元。因此,从该模型中得到的向量大小也是768。(每个单词向量表示的大小=每个编码器层的大小。)
若编码器层数记为L,注意力投书记为A,隐藏单元数记为H,则BERT-base模型:L=12,A=12,H=768,该模型的总参数大小为110M。该模型如下图所示:

?
BERT-large:包含24个编码器层,每个编码器使用16个注意头,编码器中的全连接网络包含1024个隐藏单元。因此,从该模型中得到的向量大小也是1024。因此,BERT-large模型:L=24,A=16,H=1024,该模型的总参数大小为340M。该模型如下图所示:

?
8、预训练BERT模型:
预训练的意思是,假设我们有一个模型m,首先我们为某种任务使用大规模的语料库训练模型m。现在来了一个新任务,并有一个新模型,我们使用已经训练过的模型(预训练的模型)m的参数来初始化新的模型,而不是使用随机参数来初始化新模型,然后根据新任务调整(微调)新模型的参数。这是一种迁移学习。
BERT模型在大规模语料库中通过两个任务来预训练,分别是屏蔽语言建模和下一句预测。
9、语言建模:
在语言建模任务中,我们训练模型给定一系列单词来预测下一个单词。可以把语言模型分为两类:自回归语言建模、自编码语言建模。
(1)自回归语言建模
我们可以将自回归语言建模归类为:前向预测(左到右)、反向预测(右到左)。
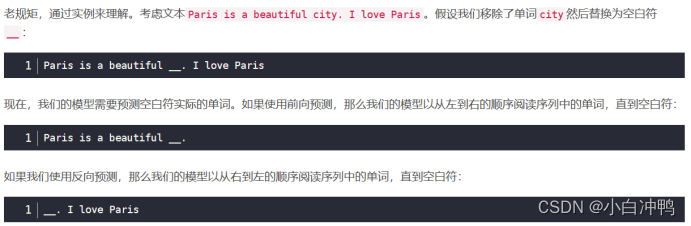 ?
?
因此,自回归模型天然就是单向的,意味着它们只会以一个方向阅读输入序列。
(2)自编码语言建模
自编码语言建模任务同时利用了前向和反向预测的优势,即:它们在预测时同时读入两个方向的序列。因此,我们可以说自编码语言模型天生就是双向的。

因此,双向的模型能获得更好的结果。
BERT是一个自编码语言模型,即:预测时同时从两个方向阅读序列。
10、屏蔽语言建模
屏蔽语言建模任务:对于给定的输入序列,我们随机屏蔽15%的单词,然后训练模型去预测这些屏蔽的单词。
以这种方式屏蔽标记会在预训练和微调之间产生差异。即,我们训练BERT通过预测[MASK]标记,训练完之后,我们可以为下游任务微调预训练的BERT模型,比如情感分析任务,但在微调期间,我们的输入不会有任何的[MASK]标记,因此,它会导致BERT的预训练方式与微调方式不匹配。
为了解决以上问题,我们应用80-10-10%的规则。我们指导我们会随即屏蔽句子中15%的标记。现在对这15%的标记,80%的概率用[MASK]标记替换该标记,10%的概率用过一个随即标记(单词)替换该标记,剩下10%的概率我们不做任何替换。
为了预测屏蔽的标记,我们将BERT返回的屏蔽的单词表示R[MASK]喂给一个带有softmax激活函数的前馈神经网络,然后该网络输出此表中每个单词属于该屏蔽的单词的概率。
在全词屏蔽模型中,如果子词被屏蔽了,然后我们屏蔽与该子词对应单词的所有子词。注意,我们也需要保持屏蔽概率为15%。所以当屏蔽子词对应的所有单词后,如果超过了15%的屏蔽率,我们可以取消屏蔽其他单词。
11、下一句预测
为了进行分类,我们简单地将[CLS]标记的嵌入表示喂给一个带有softmax函数的全连接网络,该网络会返回我们输入的句子对属于isNext和notNext的概率。因为[CLS]标记保存了所有标记的聚合表示,也就得到了整个输入的信息,所以我们可以直接拿该标记对应的嵌入表示来进行预测。
不太理解嵌入表示经过带有softmax的前馈网络怎么就得到了概率?解释:softmax的输出就是各类别的概率值,且这些概率值的和为1。(全连接层和前馈网络是一回事儿)
12、预训练过程中的热身步:
在训练的初始阶段,我们可以设置一个很大的学习率,但是我们应该在后面的迭代中设置一个较小的学习率。因为在初始的迭代时,我们远没有收敛,所以设置较大的学习率带来更大的步长是可以的,但在后面的迭代中,我们已经快要收敛了,如果学习率(导致步长)较大,可能会错过收敛位置(极小值)。在初始迭代期设置较大的学习率而在之后的迭代期减少学习率的做法被称为学习率scheduling。
热身步就是用于学习率scheduling的。假设我们的学习率是1e-4,然后热身步为10000个迭代,这意味着我们在初始的10000个迭代中,将学习率从0增大到1e-4。在10000个迭代后,我们线性地减少学习率,因为我们接近收敛位置了。
13、激活函数
BERT使用的激活函数叫作GELU(Gaussian Error Linear Unit,高斯误差线性单元)。GELU函数为:
![]()
其中,![]() 是标准的高斯累积分布函数(Gaussian cumulative distribution function)。
是标准的高斯累积分布函数(Gaussian cumulative distribution function)。
GLEU的近似计算数学公式为:
![]()
其函数图像如下所示:
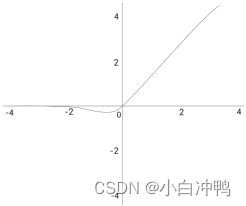
与Relu函数的比较:
Relu将小于0的数据映射到0,将大于0的数据映射到本身,虽然性能比Sigmoid函数好,但是缺乏数据的统计特性,而Gelu则在Relu的基础上加入了统计特性。论文中提到在好几个深度学习任务中Gelu的效果都优于Relu。
14、子词Tokenization:用来处理未登录词(即词表中没有出现过的词,OOV),效果很好。
将未登录词拆分成子词,检查子词是否存在于词表中,不必为拆分后的第一个子词增加##,而是要在除第一个子词之外的子词前增加##。并将词表中不存在的子词添加到词表中。
以上就是对BERT模型重点内容的介绍,希望对大家有所帮助。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!