Python大数据之PySpark(五)RDD详解
2023-12-13 19:51:45
RDD详解
为什么需要RDD?
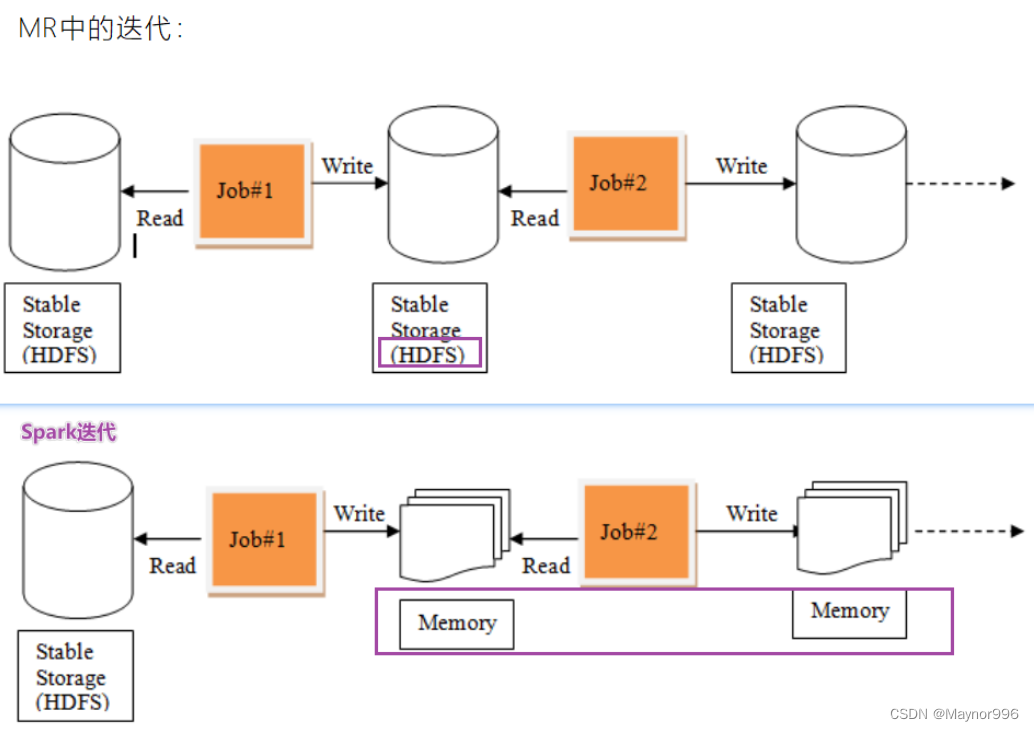
- 首先Spark的提出为了解决MR的计算问题,诸如说迭代式计算,比如:机器学习或图计算
- 希望能够提出一套基于内存的迭代式数据结构,引入RDD弹性分布式数据集,如下图
- 为什么RDD是可以容错?
- RDD依靠于依赖关系dependency relationship
- reduceByKeyRDD-----mapRDD-----flatMapRDD
- 另外缓存,广播变量,检查点机制等很多机制解决容错问题
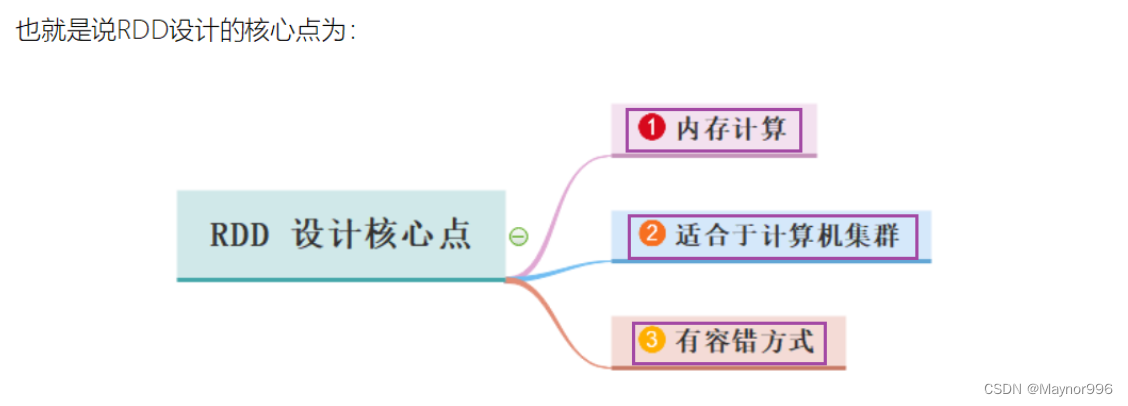
- 为什么RDD可以执行内存中计算?
- RDD本身设计就是基于内存中迭代式计算
- RDD是抽象的数据结构

什么是RDD?
- RDD弹性分布式数据集
- 弹性:可以基于内存存储也可以在磁盘中存储
- 分布式:分布式存储(分区)和分布式计算
- 数据集:数据的集合
RDD 定义
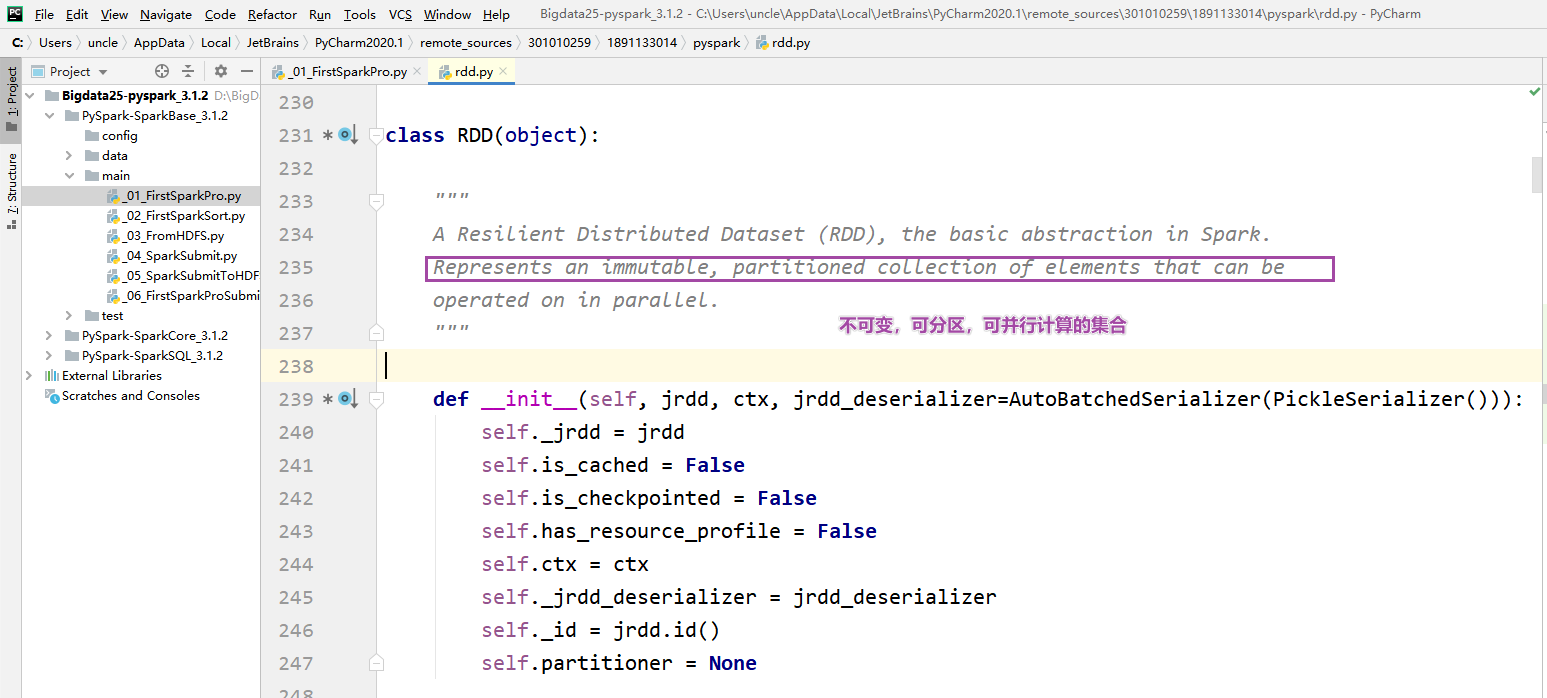
- RDD是不可变,可分区,可并行计算的集合
- 在pycharm中按两次shift可以查看源码,rdd.py
- RDD提供了五大属性
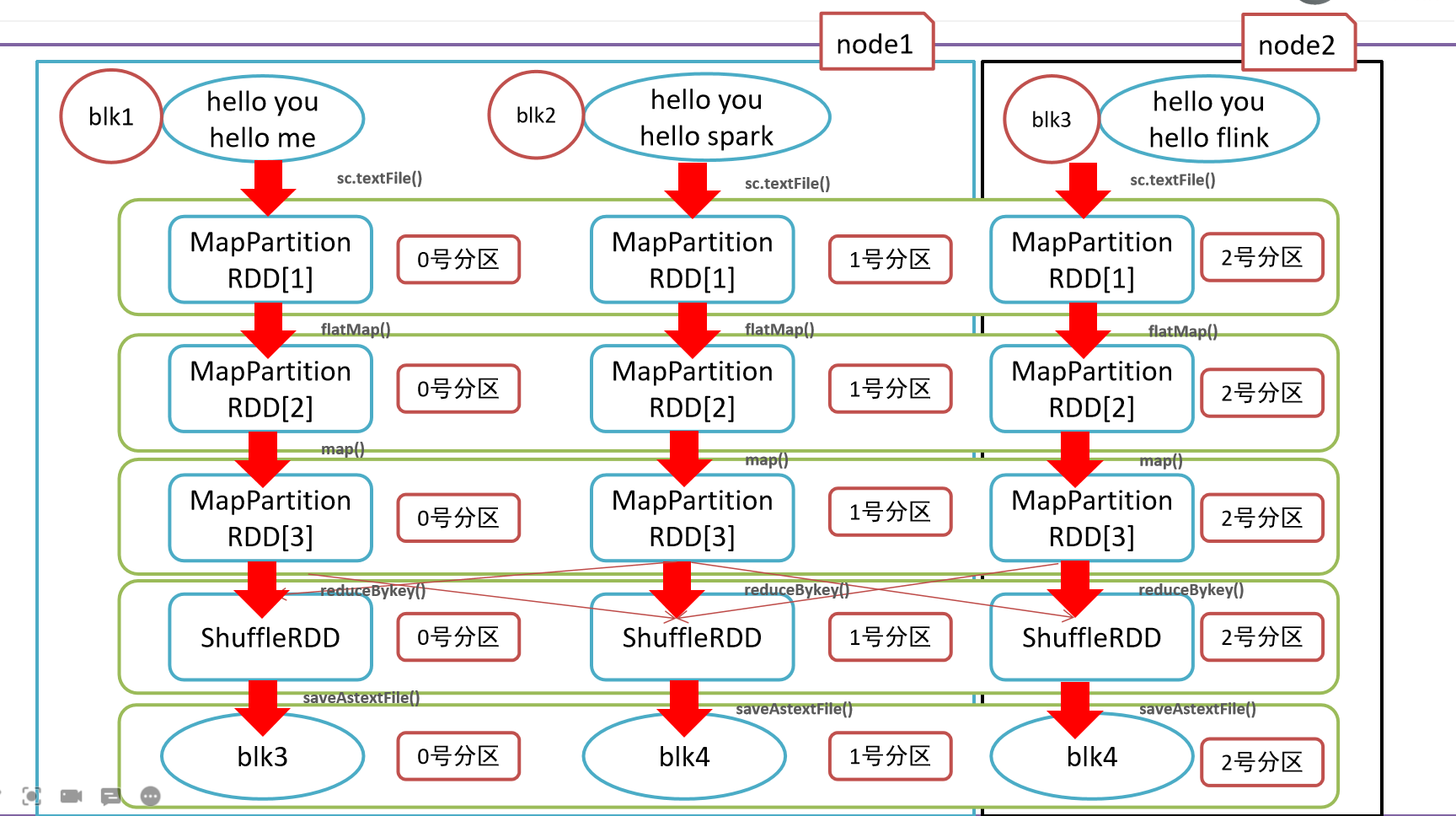
RDD的5大特性
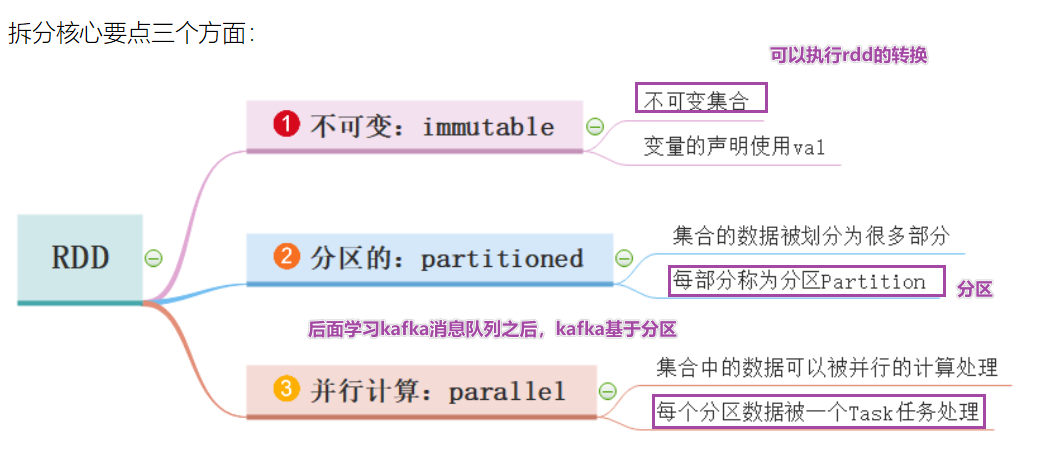
- RDD五大特性:
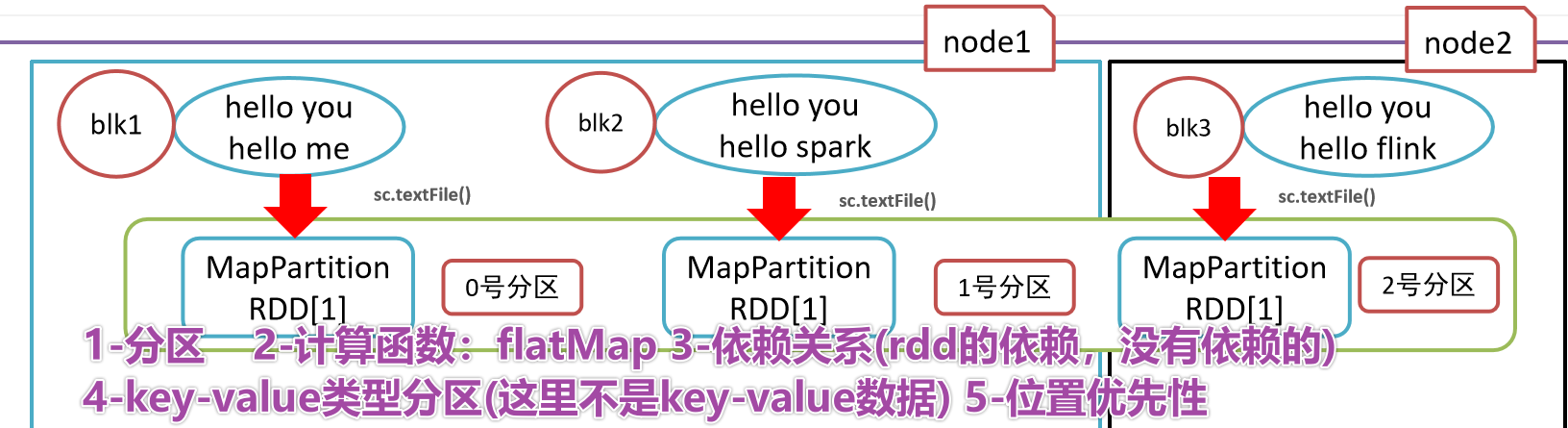
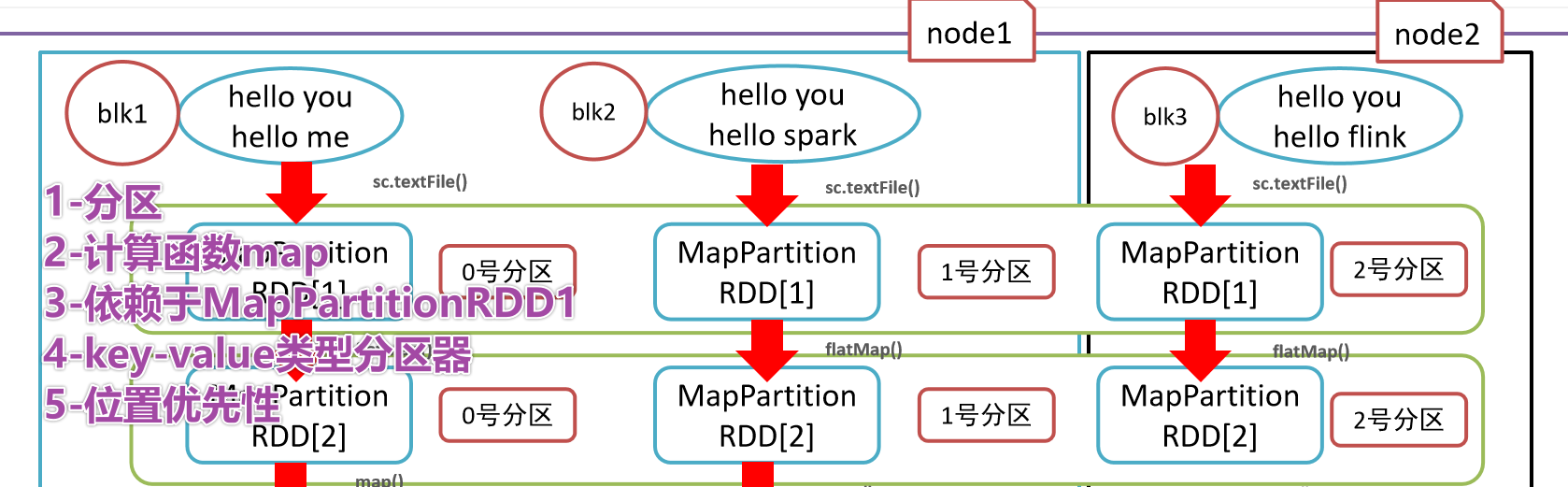
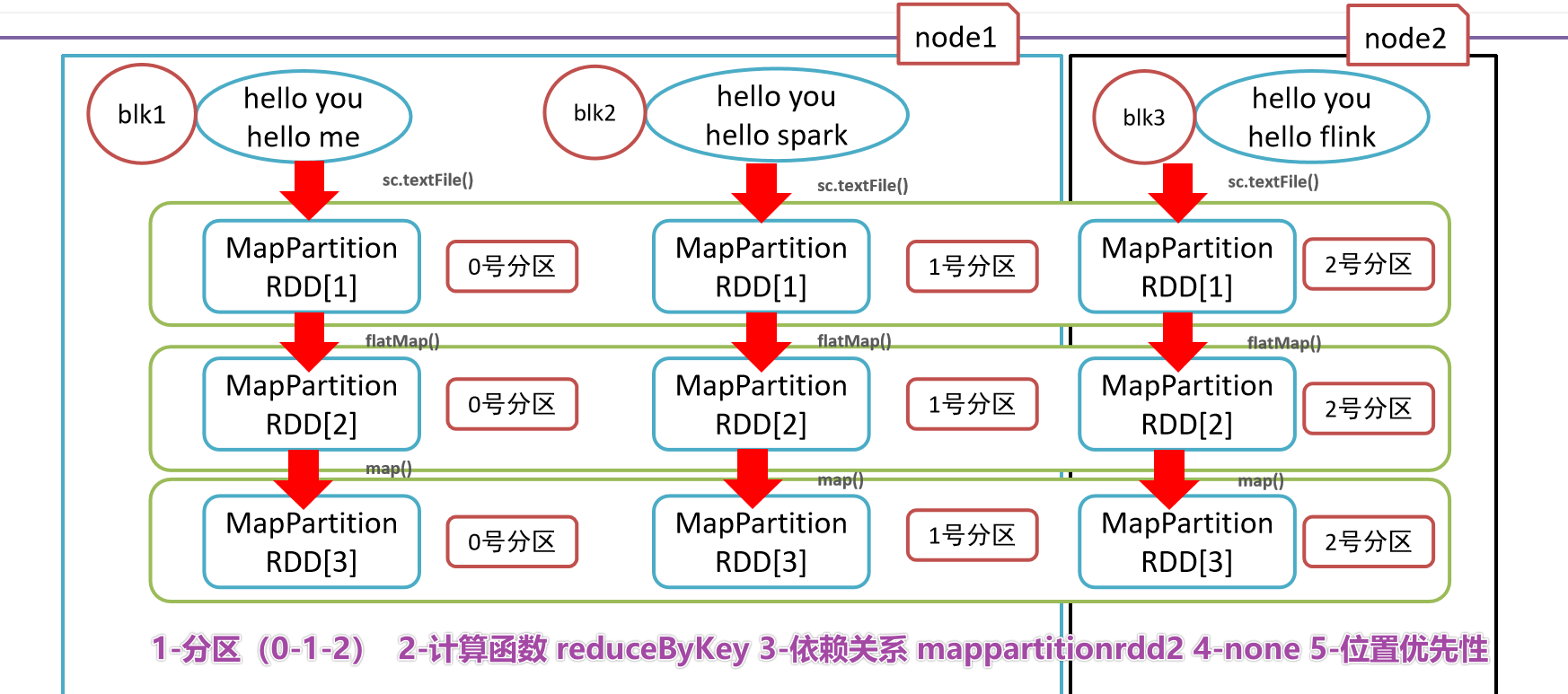
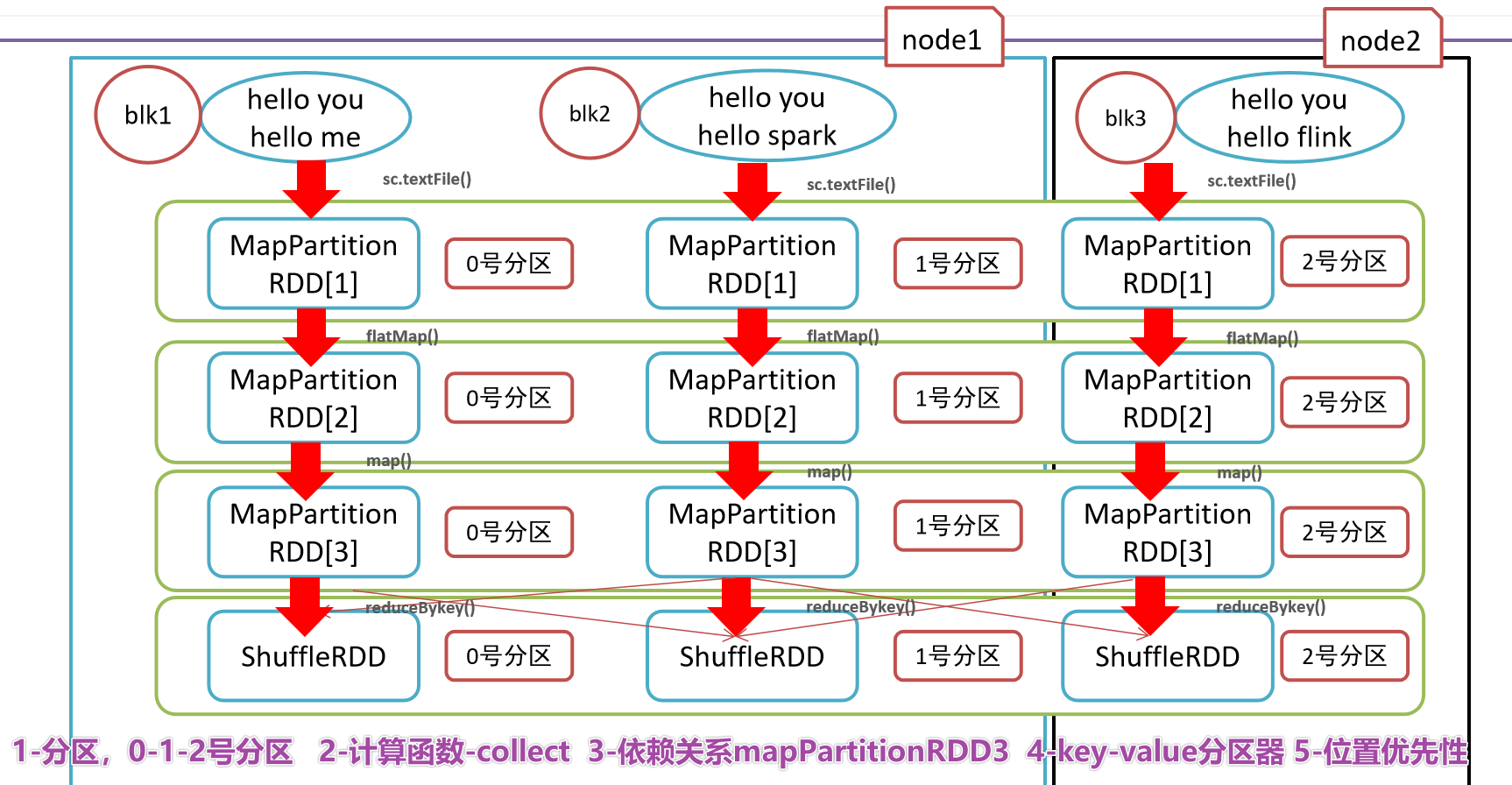
- 1-RDD是有一些列分区构成的,a list of partitions
- 2-计算函数
- 3-依赖关系,reduceByKey依赖于map依赖于flatMap
- 4-(可选项)key-value的分区,对于key-value类型的数据默认分区是Hash分区,可以变更range分区等
- 5-(可选项)位置优先性,移动计算不要移动存储

- 1-
- 2-
- 3-
- 4-
- 5-最终图解
- RDD五大属性总结
- 1-分区列表
- 2-计算函数
- 3-依赖关系
- 4-key-value的分区器
- 5-位置优先性
RDD特点—不需要记忆
- 分区
- 只读
- 依赖
- 缓存
- checkpoint
WordCount中RDD
RDD的创建
PySpark中RDD的创建两种方式
并行化方式创建RDD
rdd1=sc.paralleise([1,2,3,4,5])
通过文件创建RDD
rdd2=sc.textFile(“hdfs://node1:9820/pydata”)
代码:
# -*- coding: utf-8 -*- # Program function:创建RDD的两种方式 ''' 第一种方式:使用并行化集合,本质上就是将本地集合作为参数传递到sc.pa 第二种方式:使用sc.textFile方式读取外部文件系统,包括hdfs和本地文件系统 1-准备SparkContext的入口,申请资源 2-使用rdd创建的第一种方法 3-使用rdd创建的第二种方法 4-关闭SparkContext ''' from pyspark import SparkConf, SparkContext if __name__ == '__main__': print("=========createRDD==============") # 1 - 准备SparkContext的入口,申请资源 conf = SparkConf().setAppName("createRDD").setMaster("local[5]") sc = SparkContext(conf=conf) # 2 - 使用rdd创建的第一种方法 collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6]) print(collection_rdd.collect()) # [1, 2, 3, 4, 5, 6] # 2-1 如何使用api获取rdd的分区个数 print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) # 5 # 3 - 使用rdd创建的第二种方法 file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt") print(file_rdd.collect()) print("rdd numpartitions:{}".format(file_rdd.getNumPartitions())) # 2 # 4 - 关闭SparkContext sc.stop()
小文件读取
通过外部数据创建RDD
http://spark.apache.org/docs/latest/api/python/reference/pyspark.html#rdd-apis
# -*- coding: utf-8 -*- # Program function:创建RDD的两种方式 ''' 1-准备SparkContext的入口,申请资源 2-读取外部的文件使用sc.textFile和sc.wholeTextFile方式 3-关闭SparkContext ''' from pyspark import SparkConf, SparkContext if __name__ == '__main__': print("=========createRDD==============") # 1 - 准备SparkContext的入口,申请资源 conf = SparkConf().setAppName("createRDD").setMaster("local[5]") sc = SparkContext(conf=conf) # 2 - 读取外部的文件使用sc.textFile和sc.wholeTextFile方式\ file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100") wholefile_rdd = sc.wholeTextFiles("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100") print("file_rdd numpartitions:{}".format(file_rdd.getNumPartitions()))#file_rdd numpartitions:100 print("wholefile_rdd numpartitions:{}".format(wholefile_rdd.getNumPartitions()))#wholefile_rdd numpartitions:2 print(wholefile_rdd.take(1))# 路径,具体的值 # 如何获取wholefile_rdd得到具体的值 print(type(wholefile_rdd))#<class 'pyspark.rdd.RDD'> print(wholefile_rdd.map(lambda x: x[1]).take(1)) # 3 - 关闭SparkContext sc.stop()* 如何查看rdd的分区?getNumPartitions()

扩展阅读:RDD分区数如何确定
# -*- coding: utf-8 -*- # Program function:创建RDD的两种方式 ''' 第一种方式:使用并行化集合,本质上就是将本地集合作为参数传递到sc.pa 第二种方式:使用sc.textFile方式读取外部文件系统,包括hdfs和本地文件系统 1-准备SparkContext的入口,申请资源 2-使用rdd创建的第一种方法 3-使用rdd创建的第二种方法 4-关闭SparkContext ''' from pyspark import SparkConf, SparkContext if __name__ == '__main__': print("=========createRDD==============") # 1 - 准备SparkContext的入口,申请资源 conf = SparkConf().setAppName("createRDD").setMaster("local[*]") # conf.set("spark.default.parallelism",10)#重写默认的并行度,10 sc = SparkContext(conf=conf) # 2 - 使用rdd创建的第一种方法, collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6],5) # 2-1 如何使用api获取rdd的分区个数 print("rdd numpartitions:{}".format(collection_rdd.getNumPartitions())) #2 # 总结:sparkconf设置的local[5](默认的并行度),sc.parallesise直接使用分区个数是5 # 如果设置spark.default.parallelism,默认并行度,sc.parallesise直接使用分区个数是10 # 优先级最高的是函数内部的第二个参数 3 # 2-2 如何打印每个分区的内容 print("per partition content:",collection_rdd.glom().collect()) # 3 - 使用rdd创建的第二种方法 # minPartitions最小的分区个数,最终有多少的分区个数,以实际打印为主 file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/words.txt",10) print("rdd numpartitions:{}".format(file_rdd.getNumPartitions())) print(" file_rdd per partition content:",file_rdd.glom().collect()) # 如果sc.textFile读取的是文件夹中多个文件,这里的分区个数是以文件个数为主的,自己写的分区不起作用 # file_rdd = sc.textFile("/export/data/pyspark_workspace/PySpark-SparkCore_3.1.2/data/ratings100", 3) # 4 - 关闭SparkContext sc.stop()* 首先明确,分区的个数,这里一切以看到的为主,特别在sc.textFile
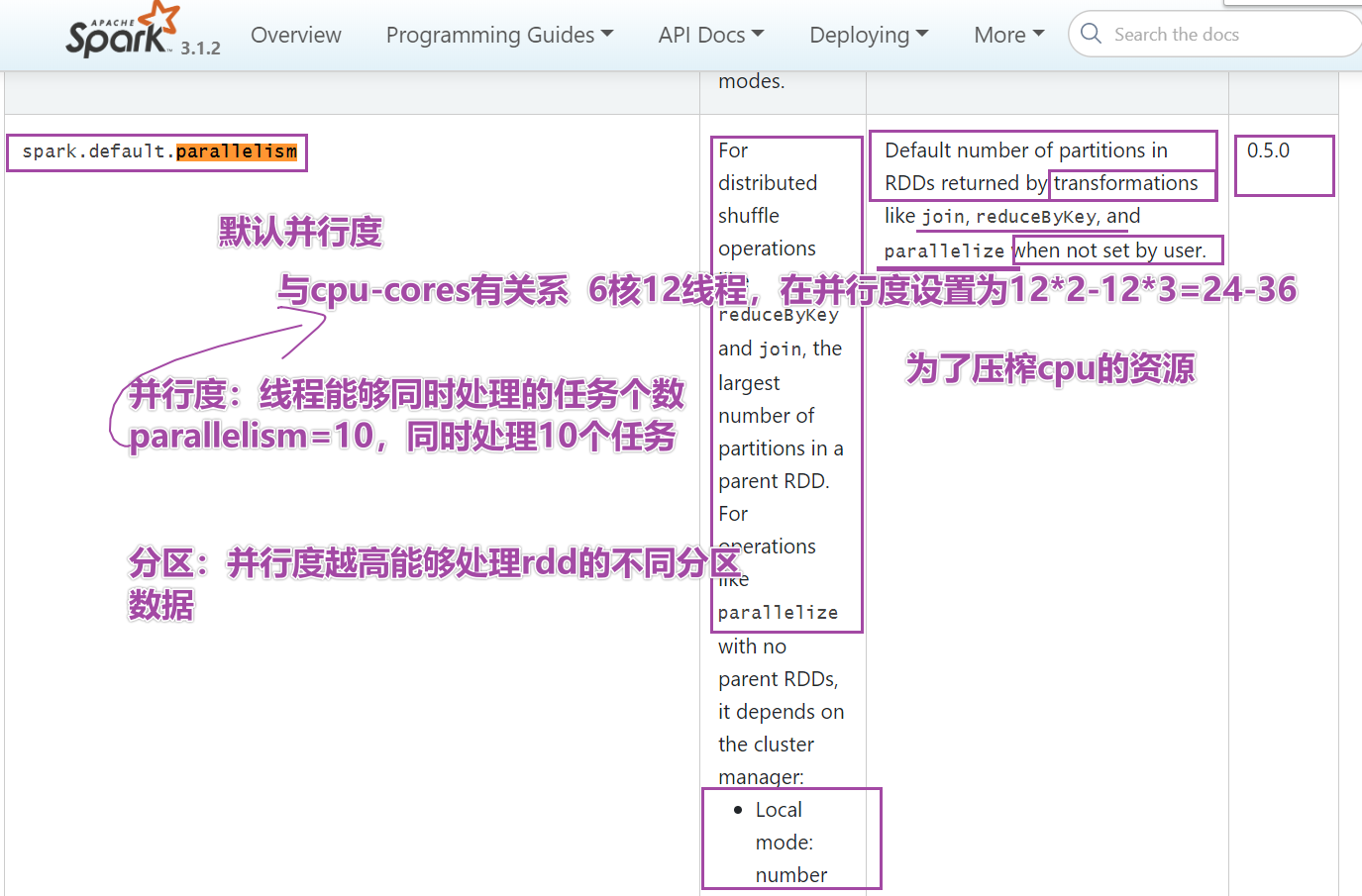


重要两个API
分区个数getNumberPartitions
分区内元素glom().collect()
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢感觉这辈子,最深情绵长的注视,都给了手机?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12453356.html
文章来源:https://blog.csdn.net/xianyu120/article/details/133526153
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!