【Python特征工程系列】利用随机森林模型分析特征重要性(源码)
2023-12-13 20:03:49
一、引言
????如果有一个包含数十个甚至数百个特征的数据集,每个特征都可能对你的机器学习模型的性能有所贡献。但是并不是所有的特征都是一样的。有些可能是冗余的或不相关的,这会增加建模的复杂性并可能导致过拟合。
特征重要性分析可以识别并关注最具信息量的特征,从而带来以下几个优势:
- 改进的模型性
- 能减少过度拟合
- 更快的训练和推理
- 增强的可解释性
随机森林是一种集成学习方法,由多个决策树组成。使用随机森林模型来分析特征重要性是一种常见的方法。随机森林模型的特征重要性是基于模型的训练结果得出的,因此它反映了模型对特征的相对重要性。这些重要性值可以用于帮助你理解哪些特征对于模型的预测结果具有更大的影响力。
我将持续更新特征重要性分析的一些方法,关注我,不错过!本文将详细解读利用随机森林模型分析特征重要性的步骤!
二、具体实现过程
2.1 准备数据
data = pd.read_csv(r'E:\数据杂坛\\UCI Heart Disease Dataset.csv')
df = pd.DataFrame(data)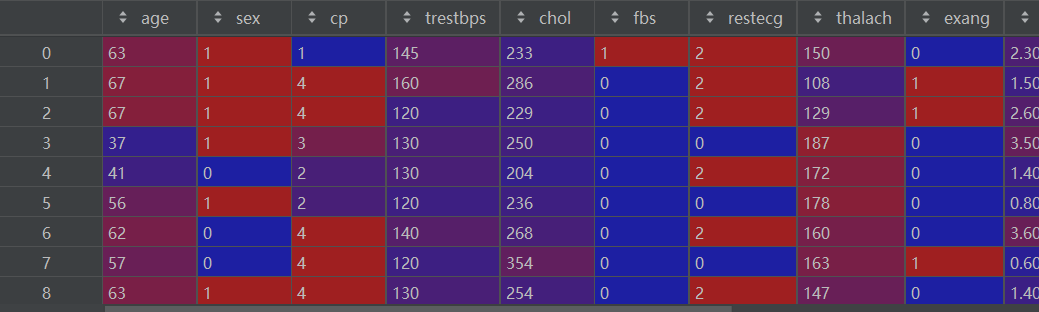
2.2 目标变量和特征变量
target = 'target'
features = df.columns.drop(target)特征变量如下:

2.3 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)?X_train如下:
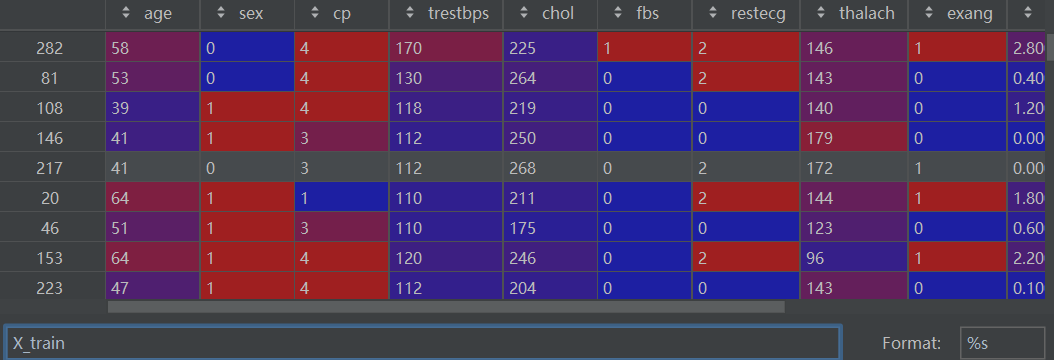
2.4 训练随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=0)
model.fit(X_train, y_train)2.5 提取特征重要性
feature_importance = model.feature_importances_
feature_names = features?feature_importance如下:

2.6 创建特征重要性的dataframe
importance_df = pd.DataFrame({'Feature': feature_names, 'Importance': feature_importance})import_df如下:
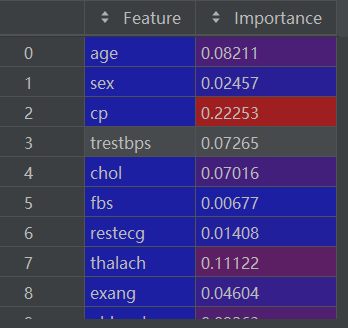
2.7 对特征重要性进行排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)排序后的 importance_df如下:
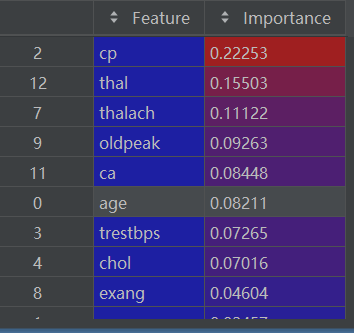
2.8 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()?可视化结果如下:
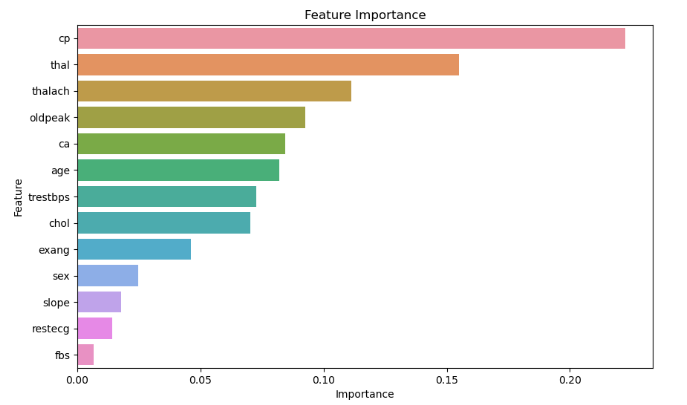
好了,本篇内容就到这里,需要数据集和源码的小伙伴可以关注底部公众号领取!
文章来源:https://blog.csdn.net/sinat_41858359/article/details/134972785
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!