面试官:如果单表数据量过大怎么办?

要回答这个问题,首先我们要明确这个表的数据是否全部有用?使用MySQL的过程,经常会遇到一个问题,比如说某张”log”表,用于保存某种记录,随着时间的不断的累积数据,但是只有最新的一段时间的数据是有用的;这个时候会遇到性能和容量的瓶颈,需要将表中的历史数据进行归档。
也就是说,大部分情况,我们做数据归档就足以解决这个问题。只有那些全部很重要的业务数据,才需要做分库分表。
利用存储过程和事件来定期进行数据的导出删除操作
1 、创建一个新表,表结构和索引与旧表一模一样
create?table?table_new?like?table_old;
2 、新建存储过程,查询30天的数据并归档进新数据库,然后把30天前的旧数据从旧表里删除
delimiter?$
create?procedure?sp()
begin
insert?into?tb_new?select?*?from?table_old?where?rectime?<?NOW()?-?INTERVAL?30?DAY;
delete?from?db_smc.table_old?where?rectime?<?NOW()?-?INTERVAL?30?DAY;
end
3、创建EVENT,每天晚上凌晨00:00定时执行上面的存储过程
create?event?if?not?exists?event_temp
on?schedule?every?1?day
on?completion?preserve
do?call?sp();
备注:第一次执行存储过程的时候因为历史数据过大, 可能发生意外让该次执行没有成功。重新执行时会遇到报错ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction,应急解决方案如下:
1、执行show full processlist;查看所有MySQL线程。
2、执行SELECT * FROM information_schema.INNODB_TRX; 查看是否有错误线程,即线程id在show full processlist;的结果中,状态为sleep的线程。
3、kill进程id。
另外写存储过程的时候可以控制事务的大小,比如说可以根据时间字段每次归档一天或者更小时间段的数据,这样就不会有大事务的问题,里面还可以加入日志表,每次归档操作的行为都写入日志表,以后查起来也一目了然。

实战
首先,查看一下哪些表数据量特别大:
SELECT???
????TABLE_NAME?AS?'表名',??
????TABLE_ROWS?AS?'记录数'??
FROM???
????information_schema.TABLES???
WHERE???
????TABLE_SCHEMA?=?'tms'?and?TABLE_ROWS?>?1000;??--?这里替换为你的数据库名
如图,我要对原数据库中的single_packaging表进行归档,就先新建一个用于归档的数据库doc_history:
然后建一张一模一样的表在这个数据库,编写归档的存储过程:
delimiter?$
create?procedure?sp()
begin
insert?into?doc_history.single_packaging?select?*?from?old_schema.single_packaging??where?create_time?<?NOW()?-?INTERVAL?7?DAY;
delete?from?old_schema.single_packaging?where?create_time?<?NOW()?-?INTERVAL?7?DAY;
end
注意老库和新库的区别。
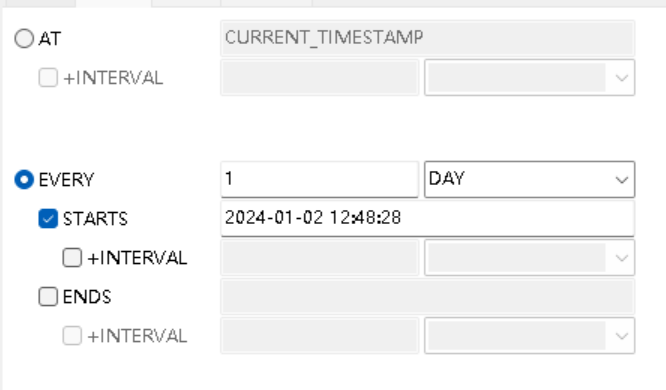
最后,设置事件,每天定时跑:
create?event?if?not?exists?event_temp
on?schedule?every?1?day
on?completion?preserve
do?call?sp();
这样就OK了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!