在线文本转语音工具的实现
文章目录
文章最下面有工具链接!
前言
最近有文字转语音功能的需求,虽然也有一些免费工具,不过并没有找到好用的在线的文本转语音工具,因此便有了这篇文章。
edge-tts库
这是一个基于微软edge浏览器大声朗读功能的python库,作者将其进行封装,因此我们可以借由它来实现文字转语音功能,那么首先我先介绍一下这个库。edge-tts的github地址
1.首先使用pip安装这个库
pip3 install edge_tts
2.写一段示例代码
import asyncio
import edge_tts
Content = "注意看,这是一段文字转语音的测试"
voiceName = "zh-TW-YunJheNeural"
output = "sound.mp3"
rate = '+5%'
volume = '+0%'
pitch = '+0Hz'
async def main():
communicate = edge_tts.Communicate(text = Content, voice=voiceName ,rate=rate, volume=volume,pitch=pitch)
await communicate.save(output)
asyncio.run(main())
asyncio.run 是 Python 标准库中 asyncio 模块提供的一个函数,用于运行一个异步函数直到它完成。它通常用于简化异步代码的执行,特别是在运行一个完整的异步应用程序时,而edge_tts所需要的就是这么一个异步执行,使用edge_tts.Communicate来生成音频内容,然后使用communicate.save来将文件保存到本地路径,其中text为所需要的文本,voice为所需要的音色,这个一会介绍,rate为语速,volume为音量,默认0就是满的,pitch为音调,后三个所接收的数据需要带上 正负号 数字 百分比的形式,其中pitch需要 正负号 数字 Hz的形式。
voice为音色参数,对于音色的获取,需要在安装完库之后在cmd里输入
edge-tts --list-voices
来查询,我列举一下这个库所支持的中文音色:
{ "Value": "zh-CN-XiaoxiaoNeural", "text": "晓晓" },
{ "Value": "zh-CN-XiaoyiNeural", "text": "小艺" },
{ "Value": "zh-CN-YunjianNeural", "text": "云建" },
{ "Value": "zh-CN-YunxiNeural", "text": "云溪" },
{ "Value": "zh-CN-YunxiaNeural", "text": "云霞" },
{ "Value": "zh-CN-YunyangNeural", "text": "云阳" },
{ "Value": "zh-CN-liaoning-XiaobeiNeural", "text": "东北小贝" },
{ "Value": "zh-CN-shaanxi-XiaoniNeural", "text": "山西小妮" },
{ "Value": "zh-HK-HiuGaaiNeural", "text": "粤语小妹" },
{ "Value": "zh-HK-HiuMaanNeural", "text": "粤语小妹2" },
{ "Value": "zh-HK-WanLungNeural", "text": "粤语小哥" },
{ "Value": "zh-TW-HsiaoChenNeural", "text": "台湾小妹" },
{ "Value": "zh-TW-HsiaoYuNeural", "text": "台湾小妹2" },
{ "Value": "zh-TW-YunJheNeural", "text": "台湾小哥" }
3.多线程
如果你跟着教程做了下来,你可以尝试使用一段超过5000字的长文本,你会发现生成速度明显慢了下来,我们可以使用多线程来同时生成多段文本,然后再把他们拼接到一起,这样速度便会有明显的提升
下面是一段多线程同步生成文件的测试,我们需要在项目目录下创建texts的文件夹,里面放上我们想要生成的文本:
import asyncio
import time
import edge_tts
import os
async def convert(text, file_name) -> None:
start_time = time.time()
communicate = edge_tts.Communicate(text, "zh-CN-XiaoxiaoNeural")
await communicate.save(f"sounds/{file_name}.mp3")
print(f"{file_name}用时:{int(time.time() - start_time)}秒")
async def main():
# 创建输出文件夹
if not os.path.exists("sounds"):
os.makedirs("sounds")
tasks = []
# 遍历输入文件夹
for root, dirs, files in os.walk("texts"):
for file in files:
# 将文件中的文本读出来
with open(os.path.join(root, file), "r", encoding='utf-8') as text_file:
text = text_file.read()
# 获取文件名
file_name, ext = os.path.splitext(file)
# 加入任务列表
tasks.append(convert(text, file_name))
# 等待所有任务完成
await asyncio.gather(*tasks)
asyncio.run(main())
可以看到这几篇文章都在同步下载,那么如果我们有一段很长的长文本,那么就可以按照这种方式来快速生成了。
pydub库
1.介绍
pydub 是一个用于处理音频文件的 Python 库,对音频进行各种操作变得更加容易。以下是一些 pydub 的主要功能:
音频格式转换: pydub 支持多种音频格式之间的转换,例如将 MP3 转换为 WAV 或反之。
音频剪辑和拼接: 你可以使用 pydub 对音频进行剪辑或拼接,合并多个音频文件。
音频格式调整: 调整音频的采样率、声道数、比特率等属性。
音频切片: 从音频文件中提取特定时间范围的片段。
音频效果: 提供一些简单的音频效果,例如增加音量、降低音量、应用均衡器等
我们只需要用到其中的音频拼接功能就可以,需要注意的是,使用这个库需要用到ffmpeg,对于ffmpeg的安装方法请移步至此:ffmpeg官网
2.示例
使用它来拼接音频是十分简单的,这是一段示例代码:
from pydub import AudioSegment
#读取音频文件
audio1 = AudioSegment.from_file("file1.wav")
audio2 = AudioSegment.from_file("file2.wav")
#拼接音频文件
merged_audio0=audio1+audio2
#保存拼接后的音频文件
merged_audio.export("merged.wav", format="wav")
将他们整合起来
需要texts,cache,download三个文件夹,其中texts里为你的文章,然后pwd需要设置为项目运行路径
import asyncio
import edge_tts
import time
from pydub import AudioSegment
import hashlib
pwd = "/var/www/html/sound"
rate = '+0%'
volume = '+0%'
pitch = '+0Hz'
def calculate_8_digit_md5(input_string):
md5 = hashlib.md5()
md5.update(input_string.encode('utf-8'))
md5_hash = md5.hexdigest()[:8]
return md5_hash
def get_current_time():
current_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
return current_time
async def convert(text, file_name, count,voice_name) -> None:
global result
start_time = time.time()
communicate = edge_tts.Communicate(text=text,voice=voice_name,rate=rate,volume=volume,pitch=pitch)
await communicate.save(pwd+f"/cache/{file_name}{count}.mp3")
print(f"{file_name}用时:{int(time.time() - start_time)}秒")
def split_and_terminate(input_string, chunk_size=3000):
res = []
start = 0
while start < len(input_string):
# 截取指定大小的片段
chunk = input_string[start:start + chunk_size]
if start + chunk_size < len(input_string):
last_comma = chunk.rfind(',')
last_period = chunk.rfind('。')
last_punctuation = max(last_comma, last_period)
if last_punctuation != -1:
chunk = chunk[:last_punctuation + 1]
res.append(chunk)
start += len(chunk)
return res
async def main():
print("md5:"+md5)
result = split_and_terminate(text)
tasks = []
for index, chunk in enumerate(result):
tasks.append(convert(chunk, md5,str(index+1),"zh-CN-XiaoxiaoNeural"))
await asyncio.gather(*tasks)
def save_string_to_file(data, file_path):
try:
with open(file_path, 'w', encoding='utf-8') as file:
file.write(data)
print(f"字符串已成功保存到文件: {file_path}")
except Exception as e:
print(f"保存文件时发生错误: {e}")
if __name__ == "__main__":
global text,md5
with open(pwd+"/texts/测试.txt", "r", encoding='utf-8') as text_file:
text = text_file.read()
md5 = calculate_8_digit_md5(text + str(time.time()))
asyncio.run(main())
print('音频下载完成')
result = AudioSegment.from_file(pwd+"/cache/" + md5 + "1.mp3")
print('第1段合成完成')
count = len(split_and_terminate(text))
for i in range(2,count+1):
result += AudioSegment.from_file(pwd+"/cache/" + md5 + str(i) + ".mp3")
print('第' + str(i) + '段合成完成')
result.export(pwd+"/download/"+md5+".mp3", format="mp3")
print(md5+".mp3生成成功")
我把他们部署到了我的服务器上,可以在线使用
点我使用工具
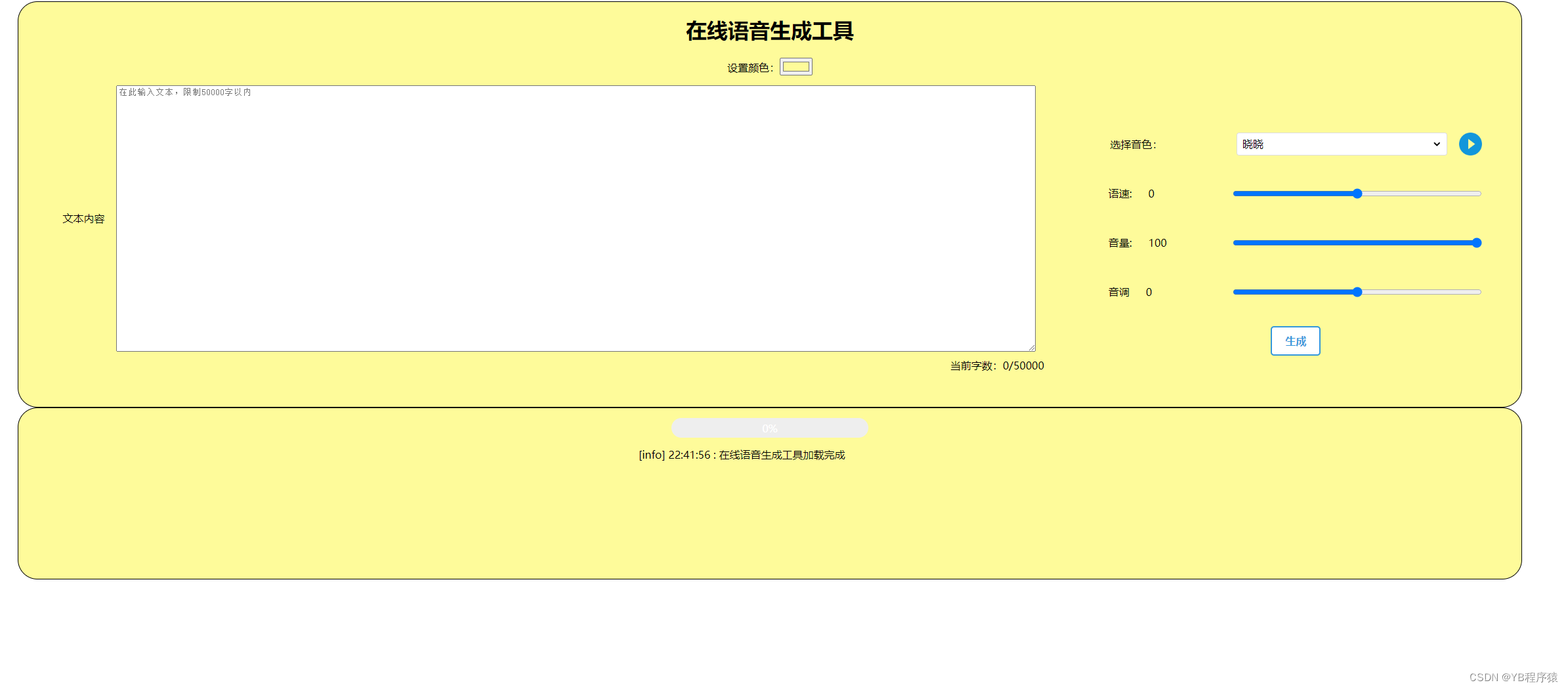
这个网站还有进度条功能和日志显示功能,他们都是用原生html实现的,如果有人感兴趣,评论区说下,我再出期文章!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!