AutoCF:Automated Self-Supervised Learning for Recommendation
一、概述
《Automated Self-Supervised Learning for Recommendation》该论文介绍了自动化自监督学习在推荐系统中的应用。
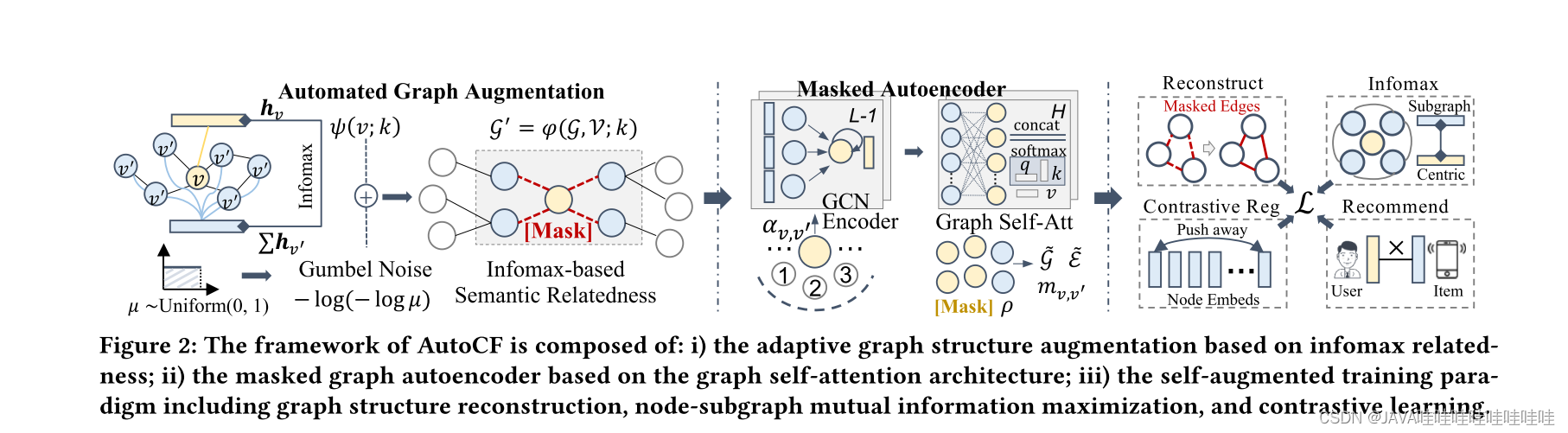
这篇论文介绍了一种名为AutoCF的自动协同过滤方法,旨在解决协同过滤中数据增强的问题。传统的对比学习方法在数据增强方面通常依赖于手动生成对比视图,这在不同数据集和推荐任务中很难泛化并且对噪声扰动不够鲁棒。为了填补这一差距,AutoCF采用了一种统一的自动生成数据增强的方法。具体而言,它基于生成式自监督学习框架,使用可学习的增强范式来提取重要的自监督信号。通过遮蔽(mask)图中的子图结构来提取重要的自监督信号,为了增强表示的判别能力,AutoCF设计了一个遮蔽图自编码器,通过重构遮蔽子图结构来聚合全局信息。
二、引言
引言主要介绍了推荐系统的作用和目标,以及当前基于图神经网络的推荐模型在标签依赖性、数据稀缺和噪声等方面存在的限制。为了解决这些问题,近期的研究提出了基于对比学习技术的数据增强方法,但这些方法仍然依赖于手动生成的对比视图,而在不同的推荐场景中准确生成对比视图是具有挑战性的。因此,需要一个统一的基于自监督学习的推荐模型,能够自动提取重要的自监督信号以进行自适应增强,减轻人工工作量。
基于此,研究提出了一种基于掩码图自编码器架构的自监督增强的自动化框架。该框架旨在回答三个关键问题:
- Q1:如何自动提取对推荐目标更有益的自监督信号?
- Q2:如何通过保留有信息的协同关系实现可学习的图增强?
- Q3:如何设计全局信息聚合的图自编码器框架以进行自适应图重构。
通过引入掩码图自编码器架构,该框架可以有效地提取自监督信号并进行数据增强,而无需手动指定对比视图。这一方法受到生成式自监督学习在视觉领域的成功启发。掩码图自编码器能够自动学习到重要的自监督信号,并通过保留有信息的协同关系来实现图的增强。同时,全局信息聚合的图自编码器框架可以进行自适应的图重构,进一步提高模型性能。
三、主要贡献
-
自适应自监督信号提取:通过设计可学习的掩码函数,能够自动识别图中重要的中心节点,并利用这些节点进行基于重构的数据增强。这种方法能够根据图的结构自适应地提取自监督信号。
-
考虑节点语义相关性:在掩码学习阶段,考虑了节点特定的子图语义相关性,以准确地保留基于图的协同关系。这有助于提高模型对用户和项目之间关系的理解和建模能力。
-
掩码图自编码器:提出了一种新的掩码图自编码器,其中关键组成部分是一个图神经编码器。该编码器能够捕捉全局的协同关系,从而能够准确地重构被掩码的用户-项目子图结构。
四、模型构架
4.1?Automated Graph Augmentation 自动图增强
【自动图增强(Automated Graph Augmentation)是一种在基于图的机器学习模型中使用的技术,用于增强模型的表示和性能。它涉及生成额外的合成数据点或修改现有的图结构,以提供更多样化和信息丰富的训练样本。
自动图增强有几种方法,包括:
1. 节点添加:向图中添加新节点,引入额外的实体或特征。这些节点可以代表推荐系统中的新用户、物品或其他相关实体。
2. 边添加:在现有节点之间添加新的边,捕捉额外的关系或交互。这有助于建模复杂的依赖关系,并改善对用户-物品交互的理解。
3. 边权重修改:可以调整图中现有边的权重,以强调或减弱特定的关系。这可以基于领域知识或从数据中学习得到。
4. 图转换:可以对整个图结构进行转换或重塑,以创建变化和多样性,从而增强模型的泛化能力。
通过自动图增强技术,可以扩展训练数据集并提供更多的样本多样性,从而改善图模型的性能和鲁棒性。这对于解决图数据中的稀疏性、噪声和数据不平衡等问题非常有用。】
4.1.1 Learning to Mask Paradigm 学习掩码范式
在自适应掩码图自编码器 AutoCF 中,提出了学习掩码范式来自动提取重构的自监督信号,以增强对图结构交互数据的建模能力。该方法通过自适应地重构掩码用户-物品交互边,以更好地捕捉高阶图协同关系。具体而言,学习图中交互掩码函数 𝜑(·) 的核心思想是首先识别图中的中心节点,并根据它们的子图结构信息遮罩有信息量的交互边。在掩码过程中,使用超参数 𝑘 控制高阶连接性的注入程度,𝑘 越大,注入的高阶连接性越多。
掩码函数可形式化为:
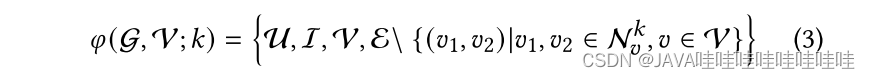
通过学习可自适应的掩码策略,AutoCF 可以提取有信息量的图结构特征,从而增强模型的建模能力,更好地表达高阶图协同关系。这种方法可以改进图模型在推荐系统等任务中的性能,提高模型的泛化能力和鲁棒性。
4.1.2 Infomax-based Semantic Relatedness 基于infomax的语义相关性
在基于Infomax的语义相关性方法中,文中利用互信息来衡量节点级嵌入和子图级表示之间的语义相关性,以捕捉用户和物品之间的高阶图协同关系。
 通过计算子图语义相关性得分𝑠𝑣,可以衡量目标节点𝑣与其邻居节点在子图中的结构一致性和拓扑信息噪声的比例。较高的语义相关性得分表示目标节点与相关节点之间的结构一致性较高,并且子图中的拓扑信息噪声较低。
通过计算子图语义相关性得分𝑠𝑣,可以衡量目标节点𝑣与其邻居节点在子图中的结构一致性和拓扑信息噪声的比例。较高的语义相关性得分表示目标节点与相关节点之间的结构一致性较高,并且子图中的拓扑信息噪声较低。
该方法的核心思想是使用随机初始化的用户/物品嵌入来计算互信息,并通过聚合邻居节点的嵌入来生成子图级表示。通过这种方式,能够量化节点级嵌入和子图级表示之间的语义相关性,并提升模型对高阶图协同关系的建模能力。
通过基于Infomax的语义相关性方法,能够更好地理解和利用用户和物品之间的图结构交互数据,从而提高模型的表达能力和性能。这对于推荐系统等任务非常有价值,可以提升模型的准确性和鲁棒性。
4.1.3 Learning to Mask withGumbel Distribution 学习使用 Gumbel 分布进行掩码
在AutoCF中,使用了学习掩码和Gumbel分布来实现自适应的数据增强和自我监督。通过设计可学习的掩码函数𝜑(G,V; 𝑘),能够自动生成用户-物品交互的自监督重构信号。为了提高学习掩码的鲁棒性,本文引入了Gumbel分布噪声,并将其应用于节点特定掩码概率的计算中。
通过将Gumbel分布噪声注入到节点特定掩码概率的推导中,获得了修正后的掩码概率𝜓′(𝑣; 𝑘)。基于这些估计的掩码概率,选择具有最高学习掩码概率的用户和物品节点作为中心节点,形成一个子集。
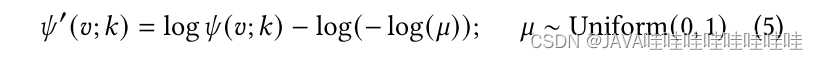
为了进一步增强模型的自我监督能力,使用子图互信息最大化来注入自监督信号。通过最大化子图的互信息,我们优化了一个基于Infomax的目标函数LInfoM,其中包括了所有节点的掩码概率之和。
通过学习掩码和使用Gumbel分布进行数据增强和自我监督,AutoCF能够提高模型的鲁棒性和泛化能力。这种方法为模型提供了更好的数据增强机制,并增强了模型对用户-物品交互的建模能力,从而提升了推荐系统等任务的性能。
4.2 Masked Graph Autoencoder?掩码图自编码器
掩码图自编码器(Masked Graph Autoencoder)是一种专门针对图结构数据设计的自编码器。它用于无监督学习任务,例如图重建和节点表示学习。
掩码图自编码器的主要思想是通过从图的部分掩码或损坏版本中重建原始图,学习图的潜在表示。该自编码器包含两个主要组件:编码器和解码器。
1. 编码器:编码器将输入图映射到低维潜在空间。通常使用图卷积层或其他图神经网络结构来捕捉图的结构信息和节点特征。编码器将图转换为潜在表示。
2. 解码器:解码器接收编码器生成的潜在表示,并重建原始图。它旨在恢复输入图中被掩码或损坏的边或节点。解码器常常使用图生成模型或图卷积解码器等技术来实现图的重建。
在训练过程中,图的一部分边或节点会被随机掩码或损坏。自编码器通过最小化原始图与重建图之间的重构误差进行训练。这个过程鼓励模型学习有意义的潜在表示,以捕捉输入图的重要结构和语义信息。
掩码图自编码器可用于各种图相关任务,包括图去噪、链接预测和异常检测。它实现了对图结构数据的无监督学习,使模型能够在没有显式标签的情况下捕捉图中的潜在模式和关系。
总的来说,掩码图自编码器为学习图的潜在表示和从部分损坏版本中重建图提供了一种框架。它是无监督学习和分析图数据的有力工具。
AutoCF旨在通过对图中掩码的用户-物品交互边进行重构学习任务,增强基于图的协同过滤。它采用图自编码器框架,其中图卷积网络被用作编码器,用于将图的结构信息融入用户和物品节点的嵌入中。为了解决图神经网络的过度平滑问题,并引入全局信息聚合,AutoCF采用图自注意力作为解码器。通过这种方式,AutoCF结合了重构学习和协同过滤,提高了推荐系统的性能。
4.2.1?Graph Convolution-based Structure Encoder?基于图卷积的结构编码器
在AutoCF中,使用基于图卷积的结构编码器来编码图的结构信息。该编码器利用轻量级图卷积进行消息传递,以生成节点的嵌入表示。在编码器中,采用了嵌入传播模式,其中节点的嵌入通过加权节点和邻居节点的嵌入来更新。权重由节点的度数进行归一化计算。在嵌入传播过程中,应用残差连接以促进最后一层图中的自我传播,以解决梯度消失的问题。这种编码器结构能够有效地编码图的结构信息,并生成节点的嵌入表示。

4.2.2?Graph Self-Attention Decoder?图自注意力解码器
在AutoCF中,为了解决图卷积编码器中的过度平滑问题,作者设计了图自注意力解码器作为自监督结构重构的一部分。该解码器利用全局自注意力来进行远程信息聚合,以替代局部卷积融合。为了提高效率并捕捉高阶结构信息,作者提出了在强调掩码子图结构的节点子集上进行成对关系学习。
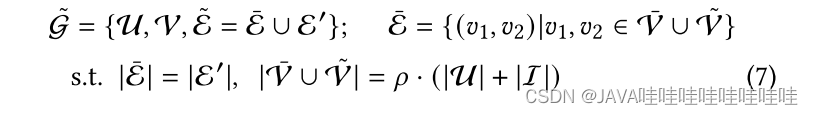 通过选择节点对和边,使用基于图注意力的消息传递进行信息聚合。
通过选择节点对和边,使用基于图注意力的消息传递进行信息聚合。
 最后,通过逐层聚合编码的用户/物品表示生成整体嵌入,并通过重构阶段恢复掩码的交互图结构。
最后,通过逐层聚合编码的用户/物品表示生成整体嵌入,并通过重构阶段恢复掩码的交互图结构。
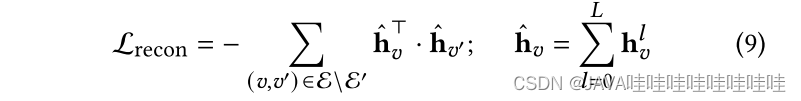
这个图自注意力解码器的设计旨在提高模型的效率和能力,以更好地捕捉图结构的信息,并用于自监督训练阶段的结构重构任务。通过引入全局自注意力和成对关系学习,该解码器能够更好地处理图中的长程依赖关系,并捕捉节点之间的高阶结构信息。这些改进有助于改善AutoCF模型在推荐系统中的性能。
4.3?Model Training
在模型训练阶段,AutoCF引入了对比训练策略来提高表示的区分能力,并在自监督学习的目标下生成均匀分布的用户和物品嵌入。为了实现这一目标,模型使用了正则化技术,通过训练用户-物品、用户-用户和物品-物品对的嵌入,生成更均匀的嵌入表示。损失函数包括了对比训练的损失以及其他自监督学习的目标,以优化模型的性能。
 最终的联合损失函数结合了主要推荐任务和自监督学习的目标,并通过控制正则化和权重衰减项的强度来平衡各个部分的影响。通过这样的训练策略,AutoCF能够获得更好的表示能力和推荐性能。
最终的联合损失函数结合了主要推荐任务和自监督学习的目标,并通过控制正则化和权重衰减项的强度来平衡各个部分的影响。通过这样的训练策略,AutoCF能够获得更好的表示能力和推荐性能。
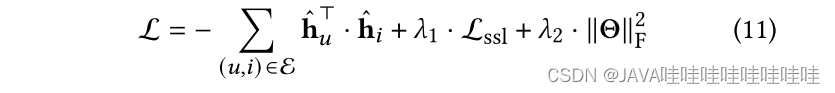
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!